検索やレポートする情報は、要約あるいはreduceする必要がある場合がよくあります。これが有用な機会は多くあります。例えば、コメントなど特定の種別のアイテム全ての件数を取得したり、素材にマッチするレシピや、キーワードに対するブログエントリなどを取得したい場合です。
注記
ビューでreduce関数を使用しているとき、emit()を呼び出すことで指定されるvalueはreduce関数によって生成された値で置き換えれられます。これは、emit()によって指定されたvalueがreduce関数への入力パラメータのひとつとして使用されることによるものです。reduce関数は、対応するmap()関数によって出力されるvalueのグループをreduce処理するように設計されています。
あるいは、reduceは合計の計算に利用できます、たとえばある顧客の全ての請求額の合計、あるいはレシピ内の準備と調理時間の合計などです。emitされたデータのグループに対する任意の計算を実行することができます。
上記の各ケースで、生データは、emit()のコールによって生成された情報のひとつかそれ以上の行からの情報です。入力データ、つまりemit()のコールによって生成された各レコードは、出力での新しいレコードを生成するためにreduce処理されたり、一緒にグループ化されたりします。
グループ化は、mapフェーズで生成された行の情報は出力されたキーの値にもとづいて行われます。出力された同一のキーで要約され、照合されます。
reduce関数を使用するときの要約は次のように行われます:
入力レコードごとに、対応するreduce関数が行に対して実行され、reduce関数が返す値が結果の行となります。
たとえば、ビルトインの
_sumreduce関数を使用すると、各ケースのvalueが出力されたkeyをもとにして合計されます。JSON{ "rows" : [ {"value" : 13000, "id" : "James", "key" : "James" }, {"value" : 20000, "id" : "James", "key" : "James" }, {"value" : 5000, "id" : "Adam", "key" : "Adam" }, {"value" : 8000, "id" : "Adam", "key" : "Adam" }, {"value" : 10000, "id" : "John", "key" : "John" }, {"value" : 34000, "id" : "John", "key" : "John" } ] }
名前をユニークキーとして使い、mapによって生成された上記のデータはキーで照合、reduceされて以下のような出力になるでしょう:
JSON{ "rows" : [ {"value" : 33000, "key" : "James" }, {"value" : 13000, "key" : "Adam" }, {"value" : 44000, "key" : "John" }, ] }
共通のキー (John, Adam, James) のそれぞれで、合計が計算され、6つの入力行はここに示される3行に減少しました。
もし、クエリ実行時にグルーピングを選択したのであれば、結果は
emit()のコールからkeyでグループ化されます。先の例のように、キーをグループの値として利用することをベースにreduce処理は動作します。配列をキーに利用した場合、クエリ実行時の結果のグループ化において、reduce関数のレベルを指定することができます。レベルは配列内のどの要素でグループ化するかを指定します。詳細については、「クエリでのグループ化」を参照してください。
ビューの定義は柔軟です。ビューにアクセスする際にreduce関数を適用するか選択することができます。これは、同じビューに対して、reduceされた結果と、reduceされていない(mapのみ)両方の結果にアクセスできるということです。二つの異なるデータの種別にアクセスするために別のビューを作成する必要はありません。
reduce関数が呼び出されるたびに、生成されたビューの内容は同一のキーと各行の値フィールドを含みますが、キーは選択されたグループ(あるいはグループレベルに応じたグループ要素の配列)で、値はreduceで計算された値となります。
Couchbaseは、_count、_sum、と_statsの3つのデフォルトビルトインreduce関数を持っています。また、カスタムreduce関数を書くこともできます。
加えて、reduce関数には次の利点があります。reduceの計算結果はその他のビュー情報と一緒にインデックスに格納されています。これはreduce関数を有効にしてビューにアクセスすると、インデックスの内容から直接情報が返却されることを意味します。これによりクエリがCouchbase Serverに与える影響は非常に低くなり(実行時に値は計算されない)、範囲指定のクエリを実行したとしても、クエリ実行時に高速に結果を得ることができます。
注記
reduce()関数は、map()フェーズの間に出力されたデータをreduceして要約するような設計になっています。データを要約するためだけに利用するべきで、出力情報の変換や情報を単一の構造に連結するためには使用しないでください。
複合構造体を使用するとき、reduce関数での複合構造体のサイズの限度は64KBとなっています。
_count関数は、map()関数からの入力行の単なるカウントを提供し、この中で関連アイテムをカウントするためにキーとグループレベルを使用します。map()の段階で生成された値は無視されます。
たとえば、次の入力を利用する場合:
{ "rows" : [ {"value" : 13000, "id" : "James", "key" : ["James", "Paris"] }, {"value" : 20000, "id" : "James", "key" : ["James", "Tokyo"] }, {"value" : 5000, "id" : "James", "key" : ["James", "Paris"] }, {"value" : 7000, "id" : "Adam", "key" : ["Adam", "London"] }, {"value" : 19000, "id" : "Adam", "key" : ["Adam", "Paris"] }, {"value" : 17000, "id" : "Adam", "key" : ["Adam", "Tokyo"] }, {"value" : 22000, "id" : "John", "key" : ["John", "Paris"] }, {"value" : 3000, "id" : "John", "key" : ["John", "London"] }, {"value" : 7000, "id" : "John", "key" : ["John", "London"] }, ] }
reduce()関数を有効にして、グループレベルに1を使用すると次にようになります:
{ "rows" : [ {"value" : 3, "key" : ["Adam" ] }, {"value" : 3, "key" : ["James"] }, {"value" : 3, "key" : ["John" ] } ] }
reduceはmapが出力した配列の第一要素をキーとして新しい結果セットを出力します。値は、最初の要素によって照合したレコード数のカウントです。
グループレベルに2を使用すると、次が生成されます:
{ "rows" : [ {"value" : 1, "key" : ["Adam", "London"] }, {"value" : 1, "key" : ["Adam", "Paris" ] }, {"value" : 1, "key" : ["Adam", "Tokyo" ] }, {"value" : 2, "key" : ["James","Paris" ] }, {"value" : 1, "key" : ["James","Tokyo" ] }, {"value" : 2, "key" : ["John", "London"] }, {"value" : 1, "key" : ["John", "Paris" ] } ] }
すると、map出力の最初の2つの要素にマッチしたキーに対するカウントとなります。
ビルトインの_sum関数は、map()関数の呼び出しによる値を合計し、各行のvalueにある情報を合計します。情報は単一の数字もしくはrereduceの場合数字の配列のどちらかになります。
注記
入力値数値の文字列表現ではなく、数値でなければなりません。reduceの入力が正しいフォーマットでない場合、map/reduce全体が失敗します。入力データが数字であることを確認するためmap()関数の段階ではparseInt()か、parseFloat()の関数の呼び出しを使用すべきです。
たとえば、前述の営業のデータを使って、ビューをグループレベル1でアクセスすると、次のように各セールスマンの総売上を生成します:
{ "rows" : [ {"value" : 43000, "key" : [ "Adam" ] }, {"value" : 38000, "key" : [ "James" ] }, {"value" : 32000, "key" : [ "John" ] } ] }
グループレベル2を利用すると、セールスマンと都市毎に要約された情報を取得することができます:
{ "rows" : [ {"value" : 7000, "key" : [ "Adam", "London" ] }, {"value" : 19000, "key" : [ "Adam", "Paris" ] }, {"value" : 17000, "key" : [ "Adam", "Tokyo" ] }, {"value" : 18000, "key" : [ "James", "Paris" ] }, {"value" : 20000, "key" : [ "James", "Tokyo" ] }, {"value" : 10000, "key" : [ "John", "London" ] }, {"value" : 22000, "key" : [ "John", "Paris" ] } ] }
ビルトインの_statsreduce関数は、入力データの統計的な計算に提供されています。_sum関数と同様に、emitの呼び出しで対応するvalueが数字になります。生成される統計は入力行のsum、count、minimun(min)、maximum (max)、そして合計の2乗(sumsqr)を含みます。
売上データを利用し、グループレベル1で若干切り捨てられた出力は次のようになります:
{ "rows" : [ { "value" : { "count" : 3, "min" : 7000, "sumsqr" : 699000000, "max" : 19000, "sum" : 43000 }, "key" : [ "Adam" ] }, { "value" : { "count" : 3, "min" : 5000, "sumsqr" : 594000000, "max" : 20000, "sum" : 38000 }, "key" : [ "James" ] }, { "value" : { "count" : 3, "min" : 3000, "sumsqr" : 542000000, "max" : 22000, "sum" : 32000 }, "key" : [ "John" ] } ] }
reduceされた出力の各行に対して、同様のフィールドが結果に出力されます。
reduce()関数はmap()関数と若干ことなる動作をしなければなりません。まず第一に、reduce()関数は対応するmap()関数から提供されるデータを変換しなければなりません。
reduce関数実行の中心的な構造は下の図に表示されています。
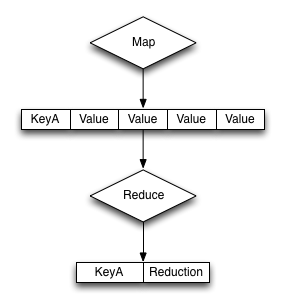
reduce()関数の基本フォーマットは次のとおりです:
function(key, values, rereduce) { … return retval; }
reduce関数は、3つの引数を指定します。
keykeyは、map()関数とgroup_levelから取り出された一意のキーです。valuesvalues引数は指定したkeyと一致するすべての値の配列です。たとえば、同じkeyが3回出力される場合、dataはemit()関数によって出力されるvalueを含む各アイテムからなる3つの配列です。rereducerereduceは関数が再reduce処理の一部として呼び出されるかどうかを示し、つまりreduce関数はreduceを入力データとして再び呼び出されます。rereduceがfalseの場合:与えられた
key引数は、map関数によって出力されたkey、そしてidが、そのkeyを出力したドキュメントIDの配列になります。valuesは値の配列となり、その配列の各要素が
keysの配列内の対応する要素に一致します。
rereduceがtrueの場合:keyはnullになります。valuesは、その前のreduce()関数が返すような値の配列になります。
関数はreturn()関数をコールしてreduceしたバージョンの情報を返します。戻り値の書式は、指定したキーに必要な形式と一致する必要があります。
テンプレートとしてこのモデルを使用すると、次の売り上げデータと標準的なmap()関数を利用して、_sumと_countのビルトイン関数の完全な実装を記述することが可能です。
function(doc, meta) { emit(meta.id, null); }
_count関数は、指定されたキーのすべてのレコードの数を返します。?reduce関数へのvalues引数は与えられたkeyのすべてのvalueの配列を含むので、配列の大きさがreduce()関数で返される必要があります:
function(key, values, rereduce) { if (rereduce) { var result = 0; for (var i = 0; i < values.length; i++) { result += values[i]; } return result; } else { return values.length; } }
ビルトイン_sum関数に相当するものを明示的に記述するには、わたされるvalues配列の合計を返す必要があります:
function(key, values, rereduce) { var sum = 0; for(i=0; i < values.length; i++) { sum = sum + values[i]; } return(sum); }
上記の関数では、データ値の配列が反復処理で加算されて、最終的な値として返されます。
reduce()関数は、透過的でかつ、スタンドアローンであるべきです。たとえば、_sum関数はグローバル変数もしくは、既存データの解析を使用せず、それ自身を呼び出す必要もないので、透過的であるということになります。
インクリメンタルなmap/reduceを機能的に取り扱う(つまり、存在するビューを更新する)ためにも、各関数が自分自身の出力を取り扱い、実行できなければなりません。これは、インクリメンタルな状況では関数が新しいレコードと前からの計算されたreduce処理の値の両方を取り扱わなければならないためです。
これは明示的に次のように記述できます:
f(keys, values) = f(keys, [ f(keys, values) ])これは下の図のようにグラフィカルに見ることができ、その前のreduce処理が情報の配列の中に含んでいるものが、値の配列の要素がreduce関数に提供されたように、reduce関数に再提供されます。
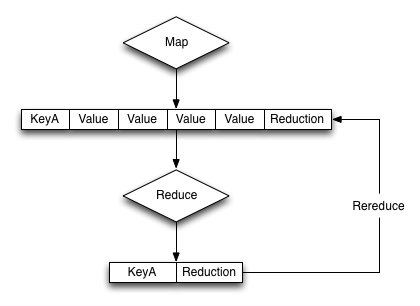
すなわち、reduce関数の入力はmapフェーズからの生データだけでなく、前のreduceフェーズでの出力もあるということです。これがrereduceと呼ばれ、reduce()という3つ目の引数によって識別されます。rereduce引数がtrueの場合、 keyとvalueの両方の引数は配列で、それぞれ含まれ関連するkeyとvalueに対応する要素を持っています。つまり、key[1]はvalue[1]のvalueに関連するkeyです。
この例はsum関数の拡張バージョンを考えたものとみることができ、ビューインデックスの構築の最初の繰り返しに値を提供する様子を示しています:
function('James', [ 13000,20000,5000 ]) {...}'James'というkeyのドキュメントがデータベースに追加されて、インクリメンタル更新を実行するためにビューの操作が再度呼び出されるときに、次のようになります:
function('James', [ 19000, function('James', [ 13000,20000,5000 ]) ]) { ... }実際には、インクリメンタル呼び出しでは前に計算された値と、新しいドキュメントから新しく出力されるvalueが提供されます。
function('James', [ 19000, 38000 ]) { ... }幸いにも、sumの構造の簡単さのために、関数はnumberの配列を受け取って、numberを返すということの両方を意味するので、再結合が簡単となります。
より複雑なreduce処理を記述したい場合、複合keyを出力するところ、つまりreduce()関数がmap()フェーズで生成されたデータに加えて複合valueとして前のreduce処理の引数を処理することを取り扱うことができる必要があります。たとえば、valueの合計とカウントの両方を表示するような複合的な出力を生成するためには、適切なreduce()関数がこのように記述されます:
function(key, values, rereduce) { var result = {total: 0, count: 0}; for(i=0; i < values.length; i++) { if(rereduce) { result.total = result.total + values[i].total; result.count = result.count + values[i].count; } else { result.total = sum(values); result.count = values.length; } } return(result); }
関数から提供された配列の各要素は要素がobject(前のreduceからの出力など)か、(mapフェーズからの)numberかどうかを識別するためにビルトインのtypeof関数を使用して確認して、それからそれに応じて返された値で更新します。
売上高のサンプルとグループレベル2を使用すると、reduceされたビューからの出力はこのようになります:
{"rows":[ {"key":["Adam", "London"],"value":{"total":7000, "count":1}}, {"key":["Adam", "Paris"], "value":{"total":19000, "count":1}}, {"key":["Adam", "Tokyo"], "value":{"total":17000, "count":1}}, {"key":["James","Paris"], "value":{"total":118000,"count":3}}, {"key":["James","Tokyo"], "value":{"total":20000, "count":1}}, {"key":["John", "London"],"value":{"total":10000, "count":2}}, {"key":["John", "Paris"], "value":{"total":22000, "count":1}} ] }
reduce関数はビューとインデックス構築のインクリメンタルな特徴を対処するために、このようなシナリオに対応するように記述されなければなりません。これが正しく取り扱えない場合、インデックスは正しい構築に失敗します。
注記
reduce()関数は処理のmap()フェーズの間に出力されたデータをreduceし、要約するように設計されています。データを要約するためだけに利用するべきで、出力情報の変換や情報を単一の構造に連結するためには使用しないでください。
複合構造体を使用するとき、reduce関数での複合構造体のサイズの限度は64KBとなっています。