How the plug-in works
The Couchbase Plug-in for Elasticsearch continuously streams data between Couchbase Server and Elasticsearch. Any document changes made in Couchbase Server will be sent to Elasticsearch via the plugin which insures your search index contains the most current items in your system. The plug-in enables the following:
- Provides Real-Time Replication. The plug-in continuously transfers data to the search cluster after Couchbase Server writes the data to disk; it will help keep your search index on Elasticsearch current with the information in Couchbase Server.
- Topology Aware. Using the plug-in, the system can handle node failures within a Couchbase cluster or Elasticsearch cluster and adapt accordingly. Replication from a Couchbase cluster will continue from functioning nodes and the items will be sent to available servers in the Elasticsearch cluster.
- Recovery from Network Failure. The plug-in is aware of what data has already been replicated from Couchbase what data still needs to be replicated. If a network failure interrupts data transfer from a Couchbase cluster, once the network issue has been resolved, replication can resume for remaining data.
If you are already building applications with Couchbase Server, you are probably aware of using views to index and query data from the server. You use this functionality to find, retrieve, and sort data based on document metadata and specified document attributes. For instance you could use views to retrieve all beer documents where the alcohol percentage is greater than 8%. Or you could use views to calculate the average alcohol percentage of all beers in an application. Providing full-text search for Couchbase documents with Elasticsearch complements this functionality by enabling you to provide text-based search results. The following shows the different elements in a system using Couchbase Server and Elasticsearch:
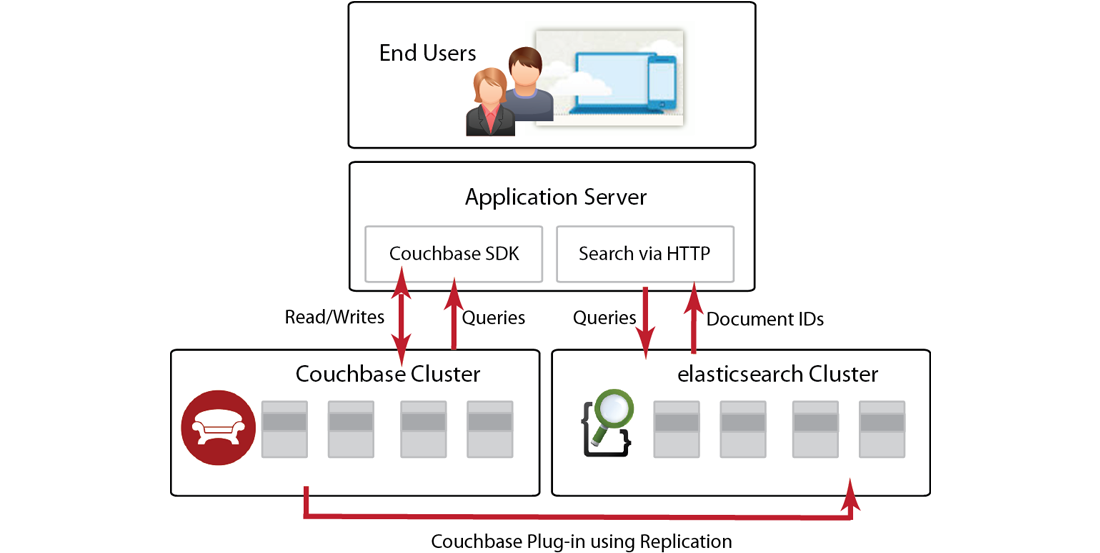
Your website or web application interacts with Couchbase Server via a Couchbase SDK. These SDKs are provided in a variety of popular web programming languages and are responsible for establishing a connection with the server and for communicating reads/writes and other functions with the server. As mentioned earlier you can also index and query data from Couchbase Server using views and your Couchbase SDK.
To provide full-text search with Couchbase Server you need to have a cluster of Elasticsearch engines, the Couchbase Plug-in for Elasticsearch, and a running Couchbase cluster. After an application writes or updates data in Couchbase Server, the server replicates a copy of that data to the Elasticsearch cluster for indexing. The Elasticsearch cluster will perform indexing based on text content in your data; then via an Elasticsearch client, you send a search query to Elasticsearch via HTTP. Elasticsearch does not keep an entire copy of each item replicated from Couchbase cluster. After Elasticsearch indexes an item it keeps the ID for the item and other metadata, but discards the content to remain efficient. After your application queries Elasticsearch for an item via HTTP, it will send back document IDs which you can use to retrieve the entire document from Couchbase Server.