Couchbase Server Groups
Couchbase Server Groups are granular, logical groupings of resources that are tolerant of large scale infrastructure faults. This section defines how the Operator can leverage them in your environment.
Couchbase server groups, that enable Server Group Awareness, are a way of logically partitioning a cluster to be fault tolerant across failure domains. The Operator is capable of automatically scheduling pod creation across failure domains and ensuring that they are added to the correct server groups.
By default, buckets are logically partitioned into vBuckets, which are distributed across all Couchbase Server nodes, providing automated load distribution. Bucket replicas are similarly distributed so that the failure of a node - or multiple nodes if more than one replica is requested - does not result in data loss, and a replica can assume control of the affected vBuckets.
Server groups allow you to logically group Couchbase Server nodes so that they can represent physical racks, data centers, or in the case of a cloud deployment, availability zones. This allows vBucket replicas to be scheduled in a completely separate server group, guaranteeing that the Couchbase Server cluster is tolerant of larger infrastructure failures, such as switch failure and availability zone outage.
Operator Server Group Scheduling
The following diagram depicts a cluster with two server classes (multi-dimensional scaling groups) that directly map to server configurations.
These classes are defined in the specification with the property couchbaseclusters.spec.servers:
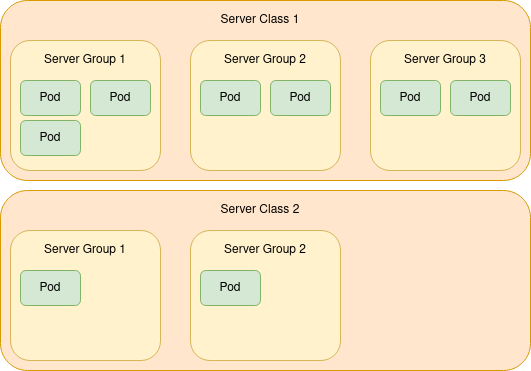
Server Class 1 may be a multi-dimensional scaling group of nodes running the data service, and Server Class 2 is running a query service.
Server classes are independently scheduled; this simplifies algorithm complexity and ensures that all pods in Server Class 2 are correctly balanced across configured server groups, unlike global scheduling. This protects against a potential service outage.
The scheduling algorithm attempts to keep the number of pods from each server class evenly distributed across all server groups.
Server groups are scheduled with pod node selectors and use the well known topology.kubernetes.io/zone label defined by default on managed clouds.
|
It’s good practice to keep each server group equally sized. In the example above, it is recommended that Server Class 1 contains 9 pods with 3 scheduled per server group. This keeps data replicas equally balanced across the server groups, as Couchbase server group scheduling of vBuckets is on a best-attempt basis. |
See the server group how-to for a server group configuration guide.