What’s New in Version 7.0?
Couchbase is the modern database for enterprise applications. Couchbase Server 7.0 combines the strengths of relational databases with the flexibility, performance, and scale of Couchbase. This release adds new relational model support including a dynamic data containment model with schema-like structure layers called scopes and collections, extended support for transactional workloads, and performance and operational improvements.
For information about platform support changes, deprecation notifications, notable improvements, and fixed and known issues, refer to the Release Notes.
New Features and Enhancements
This section describes the new features and enhancements in this release.
Quick Links: Scopes and Collections | Query Enhancements | Analytics Enhancements | The Backup Service | Metadata Management | More Enhancements
Scopes and Collections
Scopes and collections provide a dynamic data containment model by allowing you to categorize and organize documents within a bucket.
These data organization layers between Couchbase buckets and JSON documents map easily to RDBMS schema models, yet maintain the JSON flexibility to add new structures on demand.

A collection is a data container, defined on Couchbase Server, within a bucket whose type is either Couchbase or Ephemeral. Bucket-items can optionally be assigned to different collections according to content-type. For example, within a bucket that contains travel information, documents that relate specifically to airports might be assigned to an airports collection, while documents that relate to hotels might be assigned to a hotels collection, and so on.
A scope is a mechanism for the grouping of multiple collections. Collections might be assigned to different scopes according to content-type, or to deployment-phase (ie, test versus production). Applications can be assigned per-scope access-rights; allowing each application to access only those collections it requires.
The benefits of scopes and collections include:
-
The logical grouping of similar documents; potentially simplifying operations such as query, XDCR, and backup and restore.
-
The increased efficiency of indexing, due to the Data Service being able to provide documents from specific collections to the Index Service.
-
Simplified querying, since query statements are able more easily to specify particular subsets of documents.
-
Easier migration from relational databases to Couchbase Server, since collections can be designed to correspond to pre-existing relational tables.
-
Secure isolation of different document-types, within a bucket; allowing applications to be specifically authorized to use only their appropriate subsets of data.
A complete overview of scopes and collections is provided in Scopes and Collections.
Creating Scopes and Collections
Scopes and collections can be created by means of the Couchbase Web Console UI, the Couchbase CLI, the Couchbase REST API, and the N1QL query language. See Manage Scopes and Collections for instructions.
Assigning Roles with Reference to Scopes and Collections
Roles can be assigned to users with reference to specific scopes and collections, as well as to buckets. To see how this can be performed by means of the Couchbase Web Console UI, see Manage Users, Groups, and Roles.
Importing Documents into Scopes and Collections
Couchbase Server Version 7.0 allows documents to be imported into specific collections. For a step-by-step guide, see Import Documents.
Getting Information on Scopes and Collections
Information on currently defined scopes and collections can be returned by means of the cbstats collections, collections-details, scopes, and scopes-details commands.
Additionally, collection-specific information on keys and vkeys can be returned, by means of the cbstats key and vkey commands, respectively.
Using XDCR with Scopes and Collections
XDCR can replicate to a specific scope or collection. Examples are provided in Replicate Using Scopes and Collections.
Extended Support for Couchbase Transactions
Couchbase Server 7.0 extends the support of transactions to the N1QL query language. The support for multi-document ACID transactions was introduced in an earlier version (v6.5) and the feature is available to application developers through Couchbase SDK and APIs. See Transactions to learn about transactions.
With this release, application developers and RDBMS users can use familiar transactional constructs such as START TRANSACTION, SAVEPOINT, ROLLBACK and COMMIT. And, similar to RDBMS transactions, all N1QL DML statements support transactions.
To learn more about the transactional constructs in N1QL, see N1QL Support for Couchbase Transactions.
Analytics Enhancements
Support for Scopes and Collections in Analytics
In the Analytics data world, the top-level organizing concept is the Analytics scope, previously known as a dataverse. An Analytics scope (dataverse) is a namespace that gives you a place to create and manage Analytics collections and other artifacts for a given Analytics application. An Analytics scope is similar to a database or a schema in a relational DBMS.
Analytics collections, previously known as datasets, are containers that hold collections of JSON objects. These collections are similar to tables in a relational RDBMS or keyspaces in the Couchbase Query service.
Take a look at the Analytics Tutorial which walks you through the data model and main features in the Analytics world through examples.
User Defined Functions (N1QL UDFs)
User-defined functions are generally available in Couchbase Server 7.0.
In N1QL for Analytics, user-defined functions enable you to name and reuse complex or repetitive expressions, including subqueries, in order to simplify your queries. For more information, see User-Defined Functions.
ROLLUP and CUBE extensions to GROUP BY
The ROLLUP and CUBE extensions to GROUP BY enable the compact formulation of powerful hierarchical aggregation queries.
The ROLLUP aggregate function enables you to generate subtotals along with the grand total row.
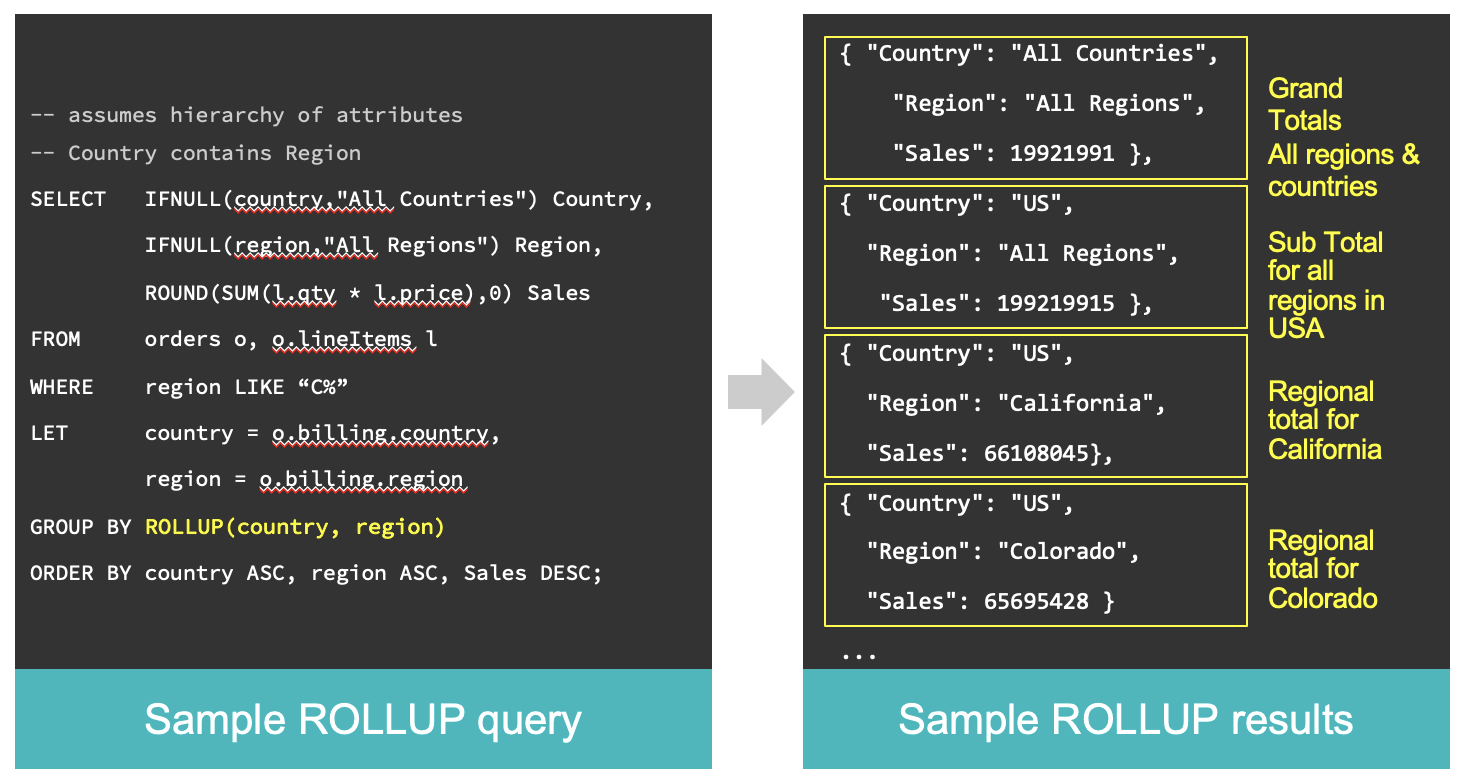
Take a look at the following blog for a ROLLUP aggregation example.
The CUBE aggregate function enables you to generate subtotals like the ROLLUP extension. In addition, the CUBE extension will generate subtotals for all combinations of grouping columns specified in the GROUP BY clause.
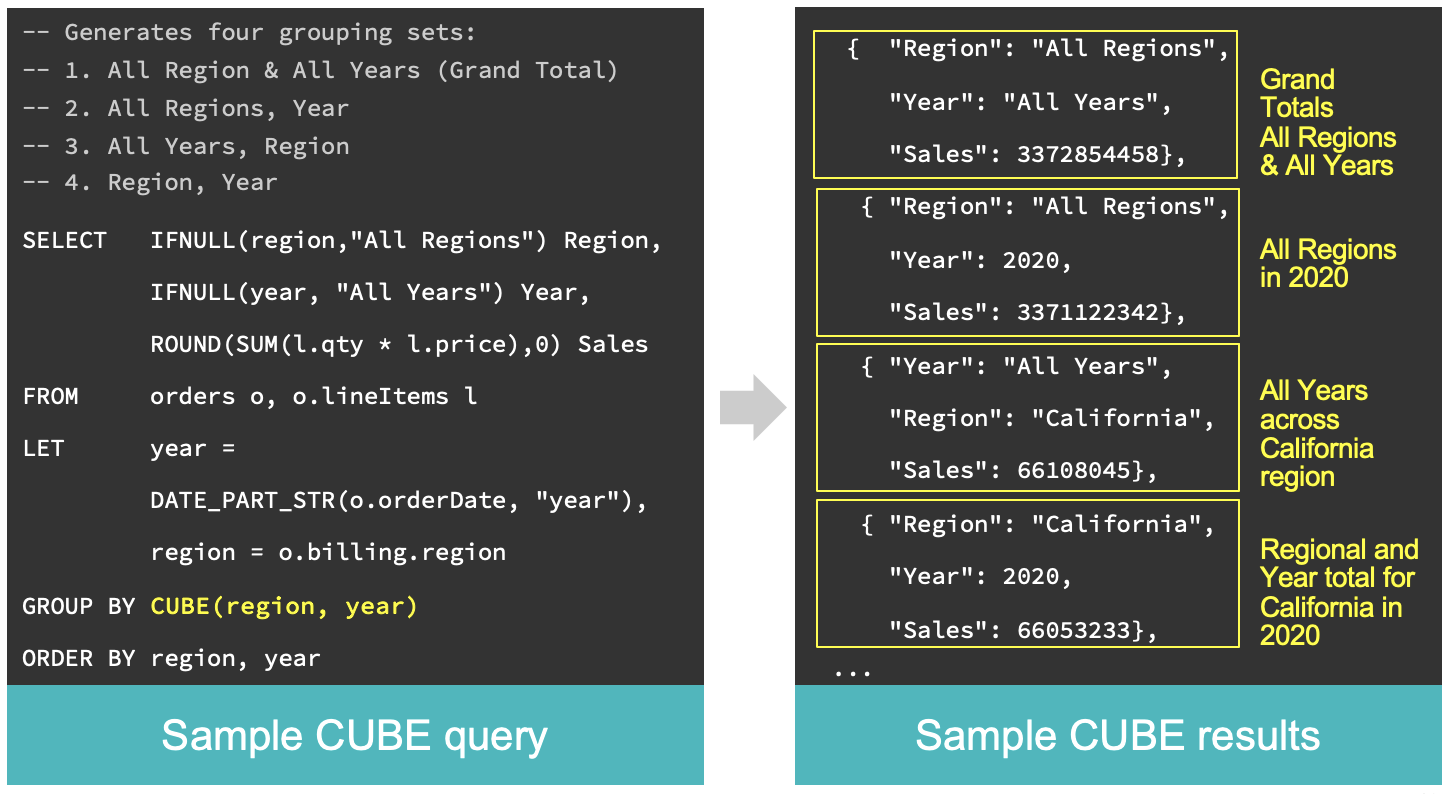
Support for Python Machine Learning Models (Python UDFs) [Developer Preview]
Python User-Defined Functions (UDFs) enable the evaluation of Python functions in the context of a N1QL query. The complexity of these UDFs can range from simple Python code snippets to trained models that are based on machine-learning frameworks like scikit-learn or PyTorch.
Query Enhancements
This release adds the following capabilities to the Query Service:
Support for Scopes and Collections with N1QL
In Couchbase Server 7.0, the N1QL query language supports a dotted path syntax for keyspace references to be able to access scopes and collections. In addition, a default query context can be specified through the Query Workbench or a request-level parameter, so that queries may refer to a collection directly without having to specify the path.
The N1QL language also contains new statements for scope and collection management. Refer to CREATE SCOPE, CREATE COLLECTION, DROP SCOPE, and DROP COLLECTION.
User Defined Functions
User-defined functions are generally available in Couchbase Server 7.0. These enable you to create functions for repetitive tasks. User-defined functions may be written in N1QL or in an external language — currently JavaScript is supported.
User-defined functions may be stored at the bucket level or the scope level. This determines the context for keyspace references within the function definition.
The N1QL language includes new statements to create, replace, execute, and drop user-defined functions. Refer to CREATE FUNCTION, EXECUTE FUNCTION, DROP FUNCTION, and User-Defined Functions.
Cost-based Optimizer
The cost-based optimizer (CBO) is generally available in Couchbase Server 7.0. It takes into account the cost of memory, CPU, network transport, and disk usage when choosing the optimal plan to execute a query.
The cost-based optimizer uses metadata and statistics to estimate amount of processing (memory, CPU, and I/O) for each operation. It compares the cost of alternative routes, and then selects the query-execution plan with the least cost.
To learn more about the cost-based optimizer, see Cost-Based Optimizer.
Memory Usage Quota Setting
The Query Service supports several new node-level settings and request-level parameters to support transactions and collections. The Query Service also supports a new node-level and request-level Memory Quota setting, which enables users to specify the maximum document memory consumption for a query. Refer to Settings and Parameters for details.
Index Advisor is Generally Available
The index advisor is generally available in Couchbase Server 7.0. As well as the ADVISE statement, the index advisor also supports the ADVISOR Function which enables users to generate index advice for every request in a session.
The index advisor leverages the cost-based optimizer in the first instance, to generate advice using a cost-based approach. If the cost-based optimizer is unable to recommend an index, the index advisor falls back on a rules-based approach.
The Backup Service
The Backup Service supports the scheduling of full and incremental data backups, either for specific individual buckets, or for all buckets on the cluster. It also allows the scheduling of merges of previously made backups. Data to be backed up can also be selected by service: for example, the data for the Data and Index Services alone might be selected for backup, with no other service’s data included.
The service — which is also referred to as backup (Couchbase Backup Service) — can be configured and administered by means of the Couchbase Web Console UI, the CLI, or the REST API.
A complete overview of the Backup Service is provided in Backup Service. Step-by-step instructions for using the service by means of Couchbase Web Console are provided in Manage Backup and Restore. A complete list of commands provided with the Couchbase REST API for the Backup Service is provided in Backup Service API.
Metadata Management
In Couchbase Server 7.0, metadata is managed by means of Chronicle; which is a consensus-based system, based on the Raft algorithm. Chronicle manages:
-
The node-list for the cluster.
-
The status of each node.
-
The service-map for the cluster, which indicates on which nodes particular services have been installed.
-
Bucket definitions, including the placement of scopes and collections.
-
The vBucket maps for the cluster.
Chronicle is:
-
Strongly consistent.
-
Supportive of full linearizability.
-
Fully tested with Jepsen.
Due to the strong consistency with which topology-related metadata is now managed, in the event of a quorum failure (meaning, the unresponsiveness of at least half of the cluster’s nodes), no modification of nodes, buckets, scopes, and collections can take place until the quorum failure is resolved.
Note that optionally, the quorum failure can be resolved by means of unsafe failover. However, that the consequences of unsafe failover in 7.0 are different from those in previous versions; and the new consequences should be fully understood before unsafe failover is attempted.
For a complete overview of how all metadata is managed by Couchbase Server, see Metadata Management. For information on unsafe failover and its consequences, see Performing an Unsafe Failover.
More Enhancements
Per-Service On-the-Wire Security Settings
Cluster-settings for on-the-wire security — including specifying TLS version and cipher-suite list — can now be set per service, as well as globally. For information, see On-the-Wire Security.
Consistent Metadata
In Couchbase Server 7.0+, metadata is managed by means of Chronicle; which is a consensus-based system, based on the Raft algorithm. For information, see Metadata Management.
Scalable Statistics
Scalable, Prometheus-based statistics for collections. For details, see Getting Cluster Statistics.
Non-Root Install and Upgrade
Non-root install and upgrade are now provided for all Linux platforms. See Non-Root Install and Upgrade.
New in Version 7.0.2
The following new features and improvements have been added in version 7.0.2:
-
TLS can be specified as mandatory for all internal and external cluster-communications — see Manage On-the-Wire Security.
-
HSTS (HTTP Strict Transport Security) can now be enabled — see Configure HSTS.
-
A cluster’s address family can be absolutely restricted to either IPv4 or IPv6 — see Manage Address Families.
-
A node’s alternate address can now be used to identify a target cluster for XDCR — see Create a Reference.
-
Standard index storage now supports indexes for both Couchbase buckets and Ephemeral buckets — see Storage Settings.
-
The Eventing Service now supports a bucket-backed caching capability, to improve performance for repetitive Data Service lookups.
-
The Eventing Service now supports node-to-node encryption. See Node-to-Node Encryption.
-
The Query Workbench now supports various charts (pie, diagram, scatter etc.) for displaying data. See Query Workbench.
-
The Search Service introduces rebalance based on file transfer; whereby, during rebalance, new partitions are optionally created by means of file transfer, rather than partition build; thereby enhancing performance. See the documentation provided for rebalancing the Search Service.