Specifying Type Identifiers
A type identifier allows the documents in a bucket to be identified filtered for inclusion into the index according to their type. When the Add Index, Edit Index, or Clone Index screen is accessed, a Type Identifier panel is displayed:
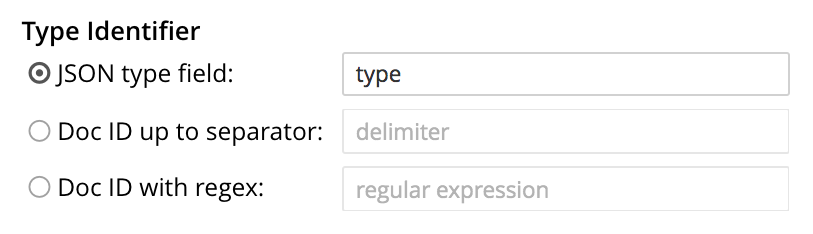
There are three options, each of which gives the index a particular way of determining the type of each document in the bucket.
This document filtering via the Type Identifier is only active is you append a . and then a substring to the end of the scope.collection in the Type Mapping.
JSON type field
It is the name of a document field. The value specified for this field is used by the index to determine the type of document.
|
FTS Indexing does not work for fields having a dot (. or period) in the field name. Users must avoid adding a dot (. or period) in the field name. Unsupported field names: field.name or country.name. For example, { "database.name": "couchbase"}Supported field names: fieldname or countryname. For example, { "databasename": "couchbase"}
|
The default value is type: meaning that the index searches for a field in each document whose name is type.
Each document that contains a field with that name is duly included in the index, with the value of the field specifying the type of the document.
| The value of the field should be of text type and cannot be an array or JSON object. |
Doc ID up to separator
The characters in the ID of each document, up to but not including the separator. For example, if the document’s ID is hotel_10123, the value hotel is determined by the index to be the type of document. The value entered into the field should be the separator-character used in the ID: for example, _, if that character is the underscore
Doc ID with regex
A RE2 regular expression that is applied by the index to the ID of each document. The resulting value is determined to be the type of the document. (This option may be used when the targeted document-subset contains neither a suitable JSON type field nor an ID that follows a naming convention suitable for Doc ID up to separator.) The value entered into the field should be the regular expression to be used.