Couchbase Scheduling and Isolation
Scheduling Couchbase pods across a Kubernetes cluster in a predictable manner is essential to guarantee consistent performance.
For any application, it is desirable to have consistent and predictable performance characteristics. This aids in predictability of future workloads, resource requirements, and operational expenditures.
This is especially relevant to stateful applications whose overall performance is limited by the slowest component. While Couchbase Server’s architecture is designed to implicitly load-balance client load across the cluster, in a cloud environment, outside influences may negatively affect overall performance characteristics. This section aims to define best practices to minimize undesirable and unpredictable variation.
Pod Isolation
The simplest method of avoiding unpredictability in Couchbase Server performance is the couchbaseclusters.spec.antiAffinity parameter.
This guarantees that Couchbase Server pods in the same cluster are unable to be scheduled by Kubernetes on the same node.
If anti-affinity were not specified, consider a three-pod Couchbase cluster. If two pods were scheduled on the same Kubernetes node, and the third on another, then given the implicit load-balancing of Couchbase clients, the first two pods would only be able to handle half the throughput of the third. This would give rise to performance inconsistency.
In a Kubernetes cluster dedicated to a single Couchbase cluster deployment, enabling anti-affinity would be sufficient to provide stable performance.
Cluster Isolation
Anti-affinity does not prevent distinct Couchbase clusters from being scheduled on the same Kubernetes nodes. Neither does it prevent Couchbase clusters from being scheduled alongside other applications that may interfere with them.
The Autonomous Operator offers two parameters that can be used in concert to guarantee workload isolation.
Taints and Tolerations
The couchbaseclusters.spec.servers.pod.spec.tolerations attribute allows Couchbase server pods exclusive access to a set of nodes.
By tainting Kubernetes nodes with NoSchedule, you can guarantee that no other pods will be scheduled to run there unless they have a matching toleration.
Couchbase Server pods can be configured with a toleration that will allow them to be scheduled on these nodes.
Furthermore, taints and tolerations are key/value pairs that allow specific clusters to be scheduled on specific nodes if you so desire.
This does not, however, prevent a Couchbase Server pod from being scheduled on a general purpose node that is not tainted, and therefore may still be subject to interference from other workloads.
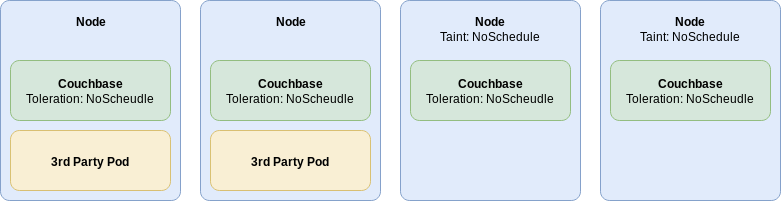
The diagram above shows the result of applying taints to Kubernetes nodes and an equal toleration to the Couchbase Server pods. Couchbase server can still be scheduled onto any node, however 3rd party pods are restricted to untainted nodes.
|
The |
Node Selectors
Given Kubernetes nodes have now been cordoned off from other processes and are now earmarked for exclusive use by Couchbase pods, we need to ensure they are scheduled on them.
The couchbaseclusters.spec.servers.pod.spec.nodeselector attribute achieves this goal.
A Kubernetes node selector forces a pod to be scheduled on a node only when it has a matching label. In this scenario you should label the nodes that have already been cordoned with a taint. Labels, like taints and tolerations, are key/value pairs, which allow them to be used to segregate individual Couchbase clusters from one another.
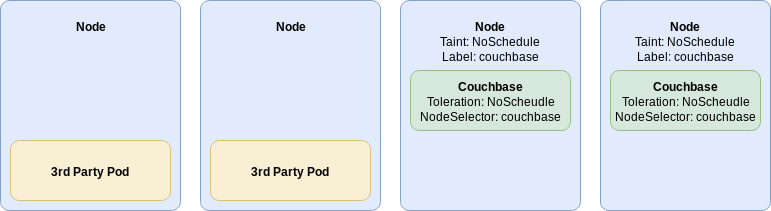
The diagram above shows the result of using both node selectors with taints and tolerations. Couchbase server pods are restricted only to their nodes, while other workloads cannot be scheduled there.
|
It is possible to segregate workloads exclusively with node selectors. The downside is that all other workloads would need to be explicitly scheduled. It is therefore highly recommended that taints be used to implicitly schedule 3rd party workloads away from Couchbase server nodes. |
Quality of Service
Cluster Isolation provides guaranteed resources for Couchbase clusters to use. It is, however, relatively complex to plan and implement. It may be sufficient to ensure that Couchbase pods are scheduled and cannot be terminated by accident.
By default, when Kubernetes schedules pods, it will place them on nodes with enough resource to accommodate them. It may also distribute pods across the cluster in order to spread the load. This may lead to a situation where there are no nodes capable of satisfying a Couchbase pod’s memory requests. Being a database, this may lead to the entire application stack not functioning.
Kubernetes provides priority classes in order to avoid these deadlock situations. By default all pods created by the user are run with the same priority class. It is possible to run pods with an elevated priority. If a high priority pod cannot be scheduled then it is possible for it to preempt pods of a lower priority — evict them from a node so that the high priority pod may be scheduled. If designed correctly, your platform will be able to tolerate evictions as those lower priority pods will be stateless and part of a highly available deployment.
Priority classes can be assigned to Couchbase server pods with the couchbaseclusters.spec.servers.pod.spec.priorityClassName parameter.