Couchbase Memory Allocation
Couchbase memory allocation is configured in the CouchbaseCluster resource.
It’s important to understand how memory allocation works in Couchbase Server, and how it applies to deployments using the Kubernetes Operator.
Kubernetes presents some unique challenges when it comes to allocating memory for Couchbase Server. This page discusses the various Couchbase memory allocation settings presented by the Kubernetes Operator, what they actually mean, and how they should be used optimally in your deployment.
Memory Quota Basics
In Couchbase Server, memory is allocated per node, with each service having its own configurable memory quota at the cluster level. Once you specify the memory quota for a particular Couchbase service, an amount of memory equal to the quota will be reserved on each Couchbase cluster node where an instance of that service exists. Note that instances of the same service cannot have different memory allocations within a cluster.
For deployments using the Kubernetes Operator, memory quotas are configured in the CouchbaseCluster resource.
Consider the following cluster of three nodes, with each node running all services:
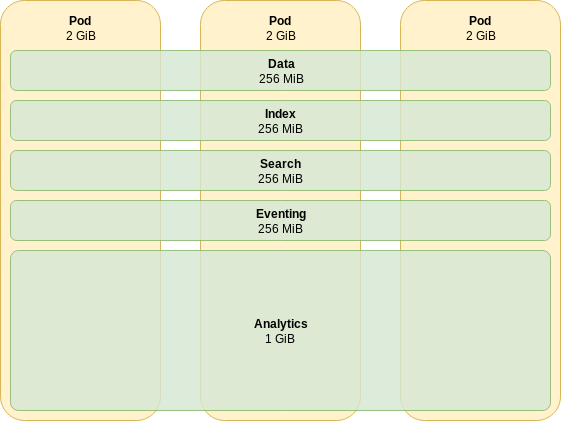
|
You’ll notice that the Query service is not pictured in Figure 1. This is because the Query service is not memory constrained, and will compete for memory against all the other services. |
When deploying the cluster in Figure 1 using the Kubernetes Operator, the CouchbaseCluster configuration would include the following:
apiVersion: couchbase.com/v2
kind: CouchbaseCluster
spec:
cluster:
dataServiceMemoryQuota: 256Mi
indexServiceMemoryQuota: 256Mi
searchServiceMemoryQuota: 256Mi
eventingServiceMemoryQuota: 256Mi
analyticsServiceMemoryQuota: 1Gi
servers:
- size: 3
name: all_services
services:
- data
- index
- query
- search
- eventing
- analytics|
The memory quotas from the configuration above are the defaults that the Kubernetes Operator will use if none are specified. The defaults are the lowest allowed and almost certainly will need modification for your specific workload. |
In this configuration, couchbaseclusters.spec.cluster.dataServiceMemoryQuota is set to 256Mi, resulting in 256 MB of RAM being reserved for the Data service on each node, for a total of 768 MB across the whole cluster.
As the cluster is horizontally scaled, so is the amount of memory allocated across the cluster.
If you were to scale this cluster by changing couchbaseclusters.spec.servers.size to 4, it would yield 1 GB of memory available to the Data service.
Homogeneous clusters like this one aren’t recommended in production for several reasons. One of the main reasons is that they don’t scale well horizontally. This is because adding a node to the cluster will increase the total memory allocations of all services. While this might be fine in a scenario where the utilization of each service rises in parallel, it is much more likely that you’ll need to scale one service more than the others. For example, if you were running the cluster in Figure 1 and found that utilization of the Data service was high while utilization of the Search service was low, adding a node in this scenario would help increase the capacity of the Data service, but result in unused capacity for the Search service. This kind of over-provisioning increases administrative overheads, as well as costs.
Bucket Memory Quotas
Bucket memory, like service memory, is also allocated per node.
The value you specify for couchbasebuckets.spec.memoryQuota will be reserved on each Couchbase Server node that runs the Data service.
However, buckets reserve their memory as a portion of the Data service quota.
This means that after you add together the memory quotas of all CouchbaseBucket resources, they cannot exceed the cluster’s dataServiceMemoryQuota in the CouchbaseCluster configuration.
You can think of the dataServiceMemoryQuota as the budget, and the memory quota of each CouchbaseBucket resource gets deducted from that budget.
An important thing to keep in mind is that when you scale the Data service horizontally by adding additional nodes, bucket memory will scale linearly — each existing bucket will get more memory, rather than additional memory being made available for new buckets.
This is because the memory quota for each CouchbaseBucket resource gets reserved on each server node that runs the Data service.
For example, if you look at the cluster in Figure 1, the Data service memory quota is 256 MB, which means that 256 MB of memory is reservable by buckets.
If this cluster had two CouchbaseBucket resources, each with a memory quota of 128 MB, then those two buckets would reserve the entire Data service memory quota for the entire cluster: 128 MB per bucket would be reserved on each node, for a total of 384 MB per bucket across the entire cluster.
If you scaled up the cluster by increasing the server count from 3 to 4, those same two buckets would each immediately reserve their 128 MB memory quotas on the new server, thus increasing the total memory reserved per bucket to 512 MB across the cluster
Like infrequently used services, this may lead to over-provisioning and wasted resources if a bucket doesn’t need the extra memory.
As your cluster scales up or down, it’s important to audit the memory usage of each bucket to ensure that they are maintaining the desired memory residency ratio.
But it is also worthwhile to check that you’re not wasting resources by reserving memory for buckets that don’t need it.
If after scaling up the cluster in the previous example to 4 nodes you determined that one of the buckets doesn’t need more than 256 MB of memory, you could change that bucket’s memory quota to 64 MB, thus freeing up Data service quota for other uses.
Advanced Memory Quotas
Since Couchbase services are set up on a per-node basis, they can be deployed, maintained, and provisioned independently of one another. This enables what is known as multi-dimensional scaling (MDS). You can use MDS to address some of the over-provisioning issues discussed in the previous section. Consider the following cluster of four nodes:
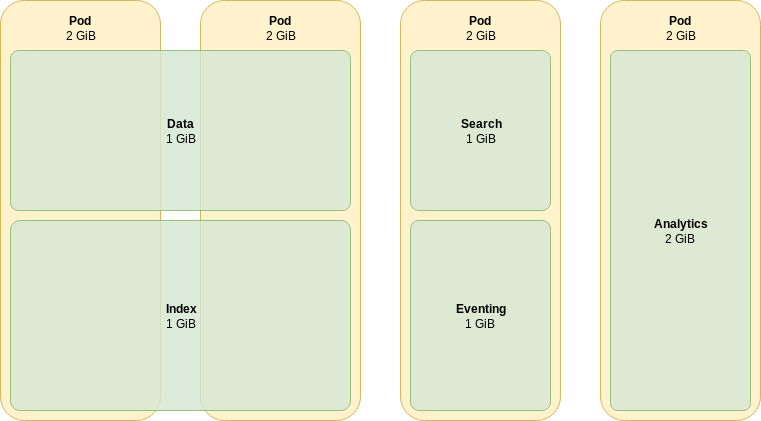
When deploying the cluster in Figure 2 using the Kubernetes Operator, the CouchbaseCluster configuration would include the following:
apiVersion: couchbase.com/v2
kind: CouchbaseCluster
spec:
cluster:
dataServiceMemoryQuota: 1Gi
indexServiceMemoryQuota: 1Gi
searchServiceMemoryQuota: 1Gi
eventingServiceMemoryQuota: 1Gi
analyticsServiceMemoryQuota: 2Gi
servers:
- size: 2
name: data_index
services:
- data
- index
- size: 1
name: search_eventing
services:
- search
- eventing
- size: 1
name: analytics_only
services:
- analyticsIn the cluster from Figure 2, there are three different MDS groups (servers that share the same set of services). MDS groups allow different services to be scaled independently. In this example, the Data and Index memory allocations across the cluster can be increased without unnecessarily increasing the allocations for the Search, Eventing, and Analytics services.
This does, however, make the cluster configuration slightly less intuitive. In the basic example from Figure 1, we only need to consider the sum of all service memory quotas when devising a scheme by which Kubernetes nodes should be allocated; the sum of all service memory quotas (plus overheads) must not exceed the total memory allocated for the Couchbase Server pod. When using MDS, however, this is dependent on which services are enabled for each server. For example, in the group with Data and Index enabled, the sum of only these two services must not exceed the memory allocated for the Couchbase Server pod.
A critical observation is that MDS groups made up of only a single service should only be scheduled onto dedicated Kubernetes nodes. If you wished to add an additional Data-only group to the cluster in Figure 2, then it would only be allocated 1 GB of memory; and if the underlying node, like the others, had 2 GB available, you’d risk over-provisioning. While this can be mitigated by scheduling MDS groups onto specialized hardware, or with specialized pod resource allocations, this increases configuration and operational complexity.
As previously mentioned, the Query service has unbounded memory constraints, and therefore should always be run in a dedicated MDS group.
Overheads and Resource Scheduling
When setting memory quotas for your cluster, you’ll need to consider the memory overhead requirements of the Couchbase Server application itself. If a Couchbase Server Pod has a total memory quota that is greater than 90% of the Kubernetes node’s overall memory, Couchbase Server will produce an error. However, since the application’s memory requirements can vary by workload, it’s generally recommended that Couchbase Server Pods reserve 25% more memory on top of their total memory quota (especially if the Pod is running the Data service).
When a Couchbase cluster is deployed by the Kubernetes Operator, each server Pod is scheduled onto its own dedicated Kubernetes node (recommended), or onto a shared Kubernetes node with other Pods. Depending on whether your Kubernetes nodes are dedicated or shared, there are slightly different considerations for when you go about setting memory quotas for Couchbase Pods.
For shared nodes, you’ll be using pod resource requests with the couchbaseclusters.spec.servers.resources attribute for each server in the CouchbaseCluster configuration.
These settings provide hints for the Kubernetes scheduler to use when picking appropriate nodes to run the server Pods.
The memory value under requests defines the minimum amount of memory the server Pod will reserve.
This value needs to be the total of all memory quotas for the services in the server specification, plus 25% overhead for the Couchbase Server application.
Using the server specification from Figure 1 as an example, you would add together the memory quota of all the services (256 + 256 + 256 + 1024 = 2048 MB), add 25% for application overhead, to get a total of 2560 MB.
Specifying a value of 2560Mi or greater for couchbaseclusters.spec.servers.resources.requests.memory will ensure that the server pod does not get evicted for using up too much memory.
The same memory requirements that apply to shared nodes (total of all service memory quotas in the server specification, plus 25% overhead for the Couchbase Server application) also apply to dedicated nodes. However, instead of using resource requests/limits to ensure server Pods have enough memory to satisfy quotas, you may be using things like labels, node selectors, and taints/tolerations to ensure that server Pods get scheduled onto Kubernetes nodes that you know for sure have enough memory.
|
Even when running a Couchbase Server Pod on a dedicated Kubernetes node, it’s important to remember that Kubernetes does not allow swap storage for containers, and thus a singular Pod must still remain within the bounds of the node’s allocatable memory, or else risk being evicted. |
Automatic Memory Reservation operator 2.2
When not explicitly specified in a server class’s pod template, the Operator will automatically populate the Couchbase server memory requests for that container. This is as defined by Overheads and Resource Scheduling, namely the total of all resource allocations per service enabled for that server class, plus a 25% overhead.
When using automatic memory allocation, be aware there is a couchbaseclusters.spec.cluster.queryServiceMemoryQuota field that can be set.
This has no affect on Couchbase Server — as it cannot constrain the query service — however, it does get added to the per-pod memory reservation total allowing sufficient overhead for query to be factored into cluster sizing.
Modification of memory allocation will cause an upgrade of the affected pods.
|
It is dangerous to change both a memory quota and the resource request at the same time. Changing both parameters, the resource request and a quota to take advantage of the new request, at the same time could potentially lead to the Couchbase Kubernetes Operator performing a swap/rebalance of all nodes in the cluster. This is due to the order in which these changes may be applied. If the quota modification gets applied before the new resource request, the memory will not be available for the pod, precipitating operator to create a new pod. To prevent this, change the resource request first, then apply the quota modification. |
Interactive Memory Allocation operator 2.1
The Operator provides memory allocation status information in your CouchbaseCluster resources with the couchbaseclusters.status.allocations attribute.
This provides direct feedback about your memory configuration, and makes applying the rules—previously discussed—more intuitive to understand and apply.
Consider the following server specification:
spec:
cluster:
dataServiceMemoryQuota: 256Mi
indexServiceMemoryQuota: 256Mi
searchServiceMemoryQuota: 256Mi
eventingServiceMemoryQuota: 256Mi
analyticsServiceMemoryQuota: 1Gi
servers:
- name: data
resources:
requests:
memory: 512Mi
services:
- data
size: 2
- name: index
resources:
requests:
memory: 512Mi
services:
- index
size: 1
- name: query_and_search
resources:
requests:
memory: 1Gi
services:
- query
- search
size: 1
- name: eventing_and_analytics
resources:
requests:
memory: 1Gi
services:
- eventing
- analytics
size: 1When processed by the Operator, it would populate the status like the following:
status:
allocations:
- name: data (1)
requestedMemory: 512Mi (2)
allocatedMemory: 256Mi (3)
allocatedMemoryPercent: 50 (4)
unusedMemory: 256Mi (5)
unusedMemoryPercent: 50 (6)
dataServiceAllocation: 256Mi (7)
- name: index
requestedMemory: 512Mi
allocatedMemory: 256Mi
allocatedMemoryPercent: 50
unusedMemory: 256Mi
unusedMemoryPercent: 50
indexServiceAllocation: 256Mi
- name: query_and_search
requestedMemory: 1Gi
allocatedMemory: 256Mi
allocatedMemoryPercent: 25
unusedMemory: 768Mi
unusedMemoryPercent: 75
searchServiceAllocation: 256Mi
- name: eventing_and_analytics
requestedMemory: 1Gi (8)
allocatedMemory: 1280Mi (9)
allocatedMemoryPercent: 125
unusedMemory: -256Mi (10)
unusedMemoryPercent: -25
analyticsServiceAllocation: 1Gi
eventingServiceAllocation: 256MiThe status is interpreted as follows:
| 1 | The name of an allocation maps directly to a server class name as defined in the specification. |
| 2 | The requestedMemory is populated only when a server class’s memory resource requests are specified.
It is a direct copy of that value. |
| 3 | The allocatedMemory is the sum total of the memory allocations for all services running on a particular server class. |
| 4 | The allocatedMemoryPercent is the amount of memory allocated from the amount of memory requested.
This is only populated if the server class’s memory resource requests are specified. |
| 5 | The unusedMemory is the amount of memory left from the server class’s memory resource requests after allocatedMemory has been removed from it.
This is only populated if the server class’s memory resource requests are specified. |
| 6 | The unusedMemoryPercent is the amount of memory left from the server class’s memory resource requests after allocatedMemory has been removed from it
This is only populated if the server class’s memory resource requests are specified.
Ideally, as described above, this value should be greater than 20%. |
| 7 | The dataServiceAllocation is the per-service memory allocation for this service class.
Each Couchbase service that is enabled for a server class will be displayed here.
It is a direct copy of the allocation specified in the cluster memory configuration. |
| 8 | In this example, the server class has requested 1GiB of memory. |
| 9 | The same server class has allocated 1280MiB (1.25GiB) or memory. This is greater that the requested memory, and therefore is over-committed. |
| 10 | This is immediately obvious when looking at the unused memory, as that value is negative. |