DROP INDEX
- reference
The DROP INDEX statement allows you to drop a named primary index or a secondary index. Dropping an index that has replicas will also drop all of the replica indexes too. You can drop unnamed primary indexes using the DROP PRIMARY INDEX statement.
Prerequisites
RBAC Privileges
User executing the DROP INDEX statement must have the Query Manage Index privilege granted on the keyspace/bucket. For more details about user roles, see Authorization.
Syntax
drop-index ::= 'DROP' 'INDEX' ( index-path '.' index-name ( 'IF' 'EXISTS' )? |
index-name ( 'IF' 'EXISTS' )? 'ON' keyspace-ref ) index-using?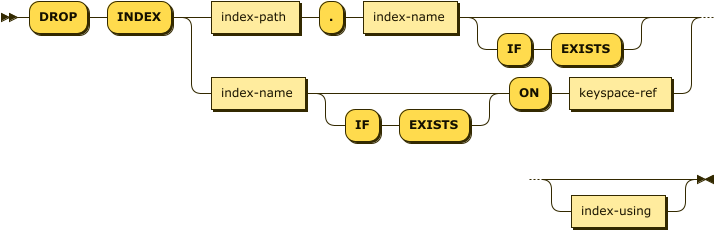
The DROP INDEX statement provides two possible syntaxes for specifying the index and the keyspace where the index is located.
- index-name
-
(Required) A unique name that identifies the index.
- index-path
-
(Optional) One possible syntax for specifying the the keyspace. Refer to Index Path below.
- keyspace-ref
-
(Optional) The other possible syntax for specifying the keyspace. Refer to Index Name ON Keyspace Reference below.
- index-using
-
Specifies the index type. (Optional) Refer to USING Clause below.
IF EXISTS Clause
The optional IF EXISTS clause enables the statement to complete successfully when the specified index doesn’t exist.
If the index does not exist within the specified keyspace, then:
-
If this clause is not present, an error is generated.
-
If this clause is present, the statement does nothing and completes without error.
Index Path
index-path ::= keyspace-full | keyspace-prefix | keyspace-partial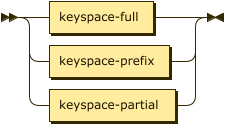
You can use a dotted notation to specify the index and the keyspace on which the index is built. This syntax provides compatibility with legacy versions of Couchbase Server. The index path may be a full keyspace path, a keyspace prefix, or a keyspace partial.
| If there is a hyphen (-) inside the index name or any part of the index path, you must wrap the index name or that part of the index path in backticks (` `). Refer to the examples below. |
Index Path: Full Keyspace
keyspace-full ::= namespace ':' bucket '.' scope '.' collection
If the index is built on a named collection, the index path may be a full keyspace path, including namespace, bucket, scope, and collection, followed by the index name. In this case, the query context is ignored.
- namespace
-
(Required) An identifier that refers to the namespace of the keyspace. Currently, only the
defaultnamespace is available. - bucket
-
(Required) An identifier that refers to the bucket name of the keyspace.
- scope
-
(Required) An identifier that refers to the scope name of the keyspace.
- collection
-
(Required) An identifier that refers to the collection name of the keyspace.
For example, default:`travel-sample`.inventory.airline.`idx-name` indicates the idx-name index on the airline collection in the inventory scope in the default:`travel-sample` bucket.
Index Path: Keyspace Prefix
keyspace-prefix ::= ( namespace ':' )? bucket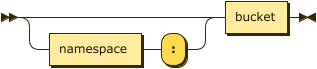
If the index is built on the default collection in the default scope within a bucket, the index path may be just an optional namespace and the bucket name, followed by the index name. In this case, the query context should not be set.
- namespace
-
(Optional) An identifier that refers to the namespace of the keyspace. Currently, only the
defaultnamespace is available. If the namespace name is omitted, the default namespace in the current session is used. - bucket
-
(Required) An identifier that refers to the bucket name of the keyspace.
For example, default:`travel-sample`.def_type indicates the def_type index on the default collection in the default scope in the default:`travel-sample` bucket.
Index Path: Keyspace Partial
keyspace-partial ::= collection
Alternatively, if the keyspace is a named collection, the index path may be just the collection name, followed by the index name. In this case, you must set the query context to indicate the required namespace, bucket, and scope.
- collection
-
(Required) An identifier that refers to the collection name of the keyspace.
For example, airline.`idx-name` indicates the idx-name index on the airline collection, assuming that the query context is set.
Index Name ON Keyspace Reference
keyspace-ref ::= keyspace-path | keyspace-partial
In Couchbase Server 7.0 and later, you can use the index name with the ON keyword and a keyspace reference to specify the keyspace on which the index is built.
The keyspace reference may be a keyspace path or a keyspace partial.
| If there is a hyphen (-) inside the index name or any part of the keyspace reference, you must wrap the index name or that part of the keyspace reference in backticks (` `). Refer to the examples below. |
Keyspace Reference: Keyspace Path
keyspace-path ::= ( namespace ':' )? bucket ( '.' scope '.' collection )?
If the keyspace is a named collection, or the default collection in the default scope within a bucket, the keyspace reference may be a keyspace path. In this case, the query context should not be set.
- namespace
-
(Optional) An identifier that refers to the namespace of the keyspace. Currently, only the
defaultnamespace is available. If the namespace name is omitted, the default namespace in the current session is used. - bucket
-
(Required) An identifier that refers to the bucket name of the keyspace.
- scope
-
(Optional) An identifier that refers to the scope name of the keyspace. If omitted, the bucket’s default scope is used.
- collection
-
(Optional) An identifier that refers to the collection name of the keyspace. If omitted, the default collection in the bucket’s default scope is used.
For example, def_type ON default:`travel-sample` indicates the def_type index on the default collection in the default scope in the default:`travel-sample` bucket.
Similarly, `idx-name` ON default:`travel-sample`.inventory.airline indicates the idx-name index on the airline collection in the inventory scope in the default:`travel-sample` bucket.
Keyspace Reference: Keyspace Partial
keyspace-partial ::= collectionAlternatively, if the keyspace is a named collection, the keyspace reference may be just the collection name. In this case, you must set the query context to indicate the required namespace, bucket, and scope.
- collection
-
(Required) An identifier that refers to the collection name of the keyspace.
For example, `idx-name` ON airline indicates the idx-name index on the airline collection, assuming the query context is set.

Usage
When using memory-optimized indexes, DROP INDEX is an expensive operation and may take a few minutes to complete.
If you drop an index with replicas while one of the index nodes is failed over, then only the replicas in the active index nodes are dropped. If the failed-over index node is recovered, then the orphan replica will be dropped when this failed-over indexer is added back to cluster.
If you drop an index with replicas when one of the index nodes is unavailable but not failed over, the drop index operation may fail.
If you drop an index which is scheduled for background creation, a warning message is generated, but the drop index operation succeeds.
| We recommend that you do not drop (or create) secondary indexes when any node with a secondary index role is down as this may result in duplicate index names. |
Examples
To try the examples in this section, you must set the query context as described in each example.
This example drops an index from the default collection in the default scope within the travel-sample bucket.
For this example, unset the query context.
For more information, see Query Context.
First create a secondary index on the default collection in the default scope in the travel-sample bucket.
Once the index creation statement comes back, query system:indexes for the status of the index.
CREATE INDEX `idx-callsign` ON `travel-sample`(callsign) USING GSI;
SELECT * FROM system:indexes WHERE name="idx-callsign";Subsequently, drop the index and check that it is no longer reported in the system:indexes output.
DROP INDEX `travel-sample`.`idx-callsign` USING GSI;
SELECT * FROM system:indexes WHERE name="idx-callsign";The following command would drop the index in exactly the same way, but uses alternative syntax.
DROP INDEX `idx-callsign` ON `travel-sample` USING GSI;This example drops an index from the airline collection.
For this example, the path to the required keyspace is specified by the query, so you do not need to set the query context.
First create an index called idx-name in the airline collection.
CREATE INDEX `idx-name` ON `travel-sample`.inventory.airline(name) USING GSI;Drop the index idx-name from the airline collection.
DROP INDEX `idx-name` ON `travel-sample`.inventory.airline;For this example, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Create an index called idx-name in the airline collection.
CREATE INDEX `idx-name` ON airline(name);Drop the index idx-name from the airline collection.
DROP INDEX `idx-name` ON airline;The following command would drop the index in exactly the same way, but uses alternative syntax.
DROP INDEX airline.`idx-name`;