Array Indexing
- reference
Array Indexing adds the capability to create global indexes on array elements and optimizes the execution of queries involving array elements.
This is a huge leap from the previous versions where secondary indexes could only be created and subsequently queried on whole arrays. You can now create an index of array elements ranging from plain scalar values to complex arrays or JSON objects nested deeper in the array.
Syntax
To create an array index, the overall syntax is the same as for a global secondary index. The distinguishing feature is the use of an array expression as an index key.
Refer to the CREATE INDEX statement for details of the syntax.
Index Key
index-key ::= expr | array-expr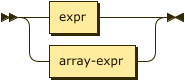
To create an array index, one index key must be an array expression. The index key containing the array expression is referred to as the array index key. The index definition may also contain other index keys which are not array expressions.
- expr
-
A SQL++ expression over any fields in the document. This cannot use constant expressions, aggregate functions, or sub-queries.
- array-expr
-
An array expression. Refer to Array Expression below.
|
Array Index Key
Currently, the index definition for an array index may only contain one array index key. However, the array index key may index more than one field or expression within the array, as described below. For an UNNEST scan to use an array index, the array index key containing the appropriate array expression must be the leading key of the index definition. The UNNEST scan can generate index spans on other non-leading index keys when appropriate predicates exist. In order for the optimizer to select the correct array index for a SELECT, UPDATE, or DELETE statement, the query predicate which appears in the WHERE clause must be constructed to match the format of the array index key. See Format of Query Predicate for details. You can add the |
Array Expression
array-expr ::= full-array-expr | simple-array-expr
The array expression can be either a full array expression, which uses the ARRAY operator to index specified fields and elements within the array; or a simple array expression, which indexes all fields and elements in the array.
Full Array Expression
full-array-expr ::= ( 'ALL' | 'DISTINCT' ) 'ARRAY' var-expr
'FOR' var ( 'IN' | 'WITHIN' ) expr
( ',' var ( 'IN' | 'WITHIN' ) expr )* ( 'WHEN' cond )? 'END'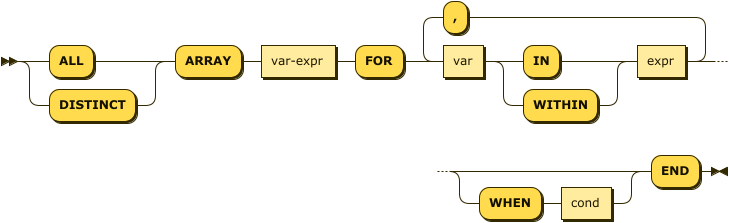
The ARRAY operator lets you map and filter the elements or attributes of a collection, object, or objects.
It evaluates to an array of the operand expression that satisfies the WHEN clause, if specified.
- var-expr
-
A function of the
varvariable used in the FOR clause. - var
-
Represents elements in the array specified by
expr. - expr
-
Evaluates to an array of objects, elements of which are represented by the
varvariable. - cond
-
Specifies predicates to qualify the subset of documents to include in the index array.
|
Variable Expression
You can index one or more expressions within the array (up to maximum of 32) by using the FLATTEN_KEYS() function in the The To create an array index involving multiple array elements or multiple arrays, you may construct the You can add the |
Simple Array Expression
simple-array-expr ::= ( 'ALL' | 'DISTINCT' ) expr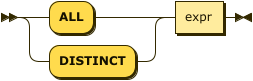
Couchbase Server 5.0 and later provides a simpler syntax for array indexing when all array elements are indexed as is, without needing to use the ARRAY operator in the index definition.
- expr
-
An array field name, or an expression that can evaluate to an array. In this case, all fields and elements of the array are indexed.
Format of Query Predicate
In order for the optimizer to select the correct array index for a SELECT, UPDATE, or DELETE statement, the query predicate which appears in the WHERE clause must be constructed to match the format of the array index key.
Consider the following expressions used in a CREATE INDEX statement:
C1
|
C2
|
And the following expressions used in the SELECT statement WHERE clause:
Q1
|
Q2
|
The following dependencies must be satisfied for the Query service to consider the array index:
-
The index keys used in CREATE INDEX must be used in the WHERE clause. (The query can use different variable names from those used in the array index definition.)
-
The
expr2in Q1 and Q2 must be equivalent to theexpr1in C1 and C2. This is a formal notion of equivalence. For example, they must be the same expressions, or equivalent arithmetic expressions such as(x+y)and(y+x). -
Usually,
g(x)in Q1 and Q2 must be sargable forf(x)in C1 and C2. In other words, if there were a scalar index with keyf(x), then that index would be applicable to the predicateg(x). For example, the predicateUPPER(x) LIKE "John%"is sargable for the index keyUPPER(x).
Flatten Keys
Now consider the following variants of C1 and C2, in which the index key f(x) uses the FLATTEN_KEYS() function to flatten expressions within the array:
C3
|
C4
|
-
The index keys C3 and C4 flatten expressions within the array, as if they were separate index keys; and all subsequent index keys are accordingly moved to the right. Queries will be sargable and will generate spans.
-
In order to select an array index defined using C3 or C4, the predicate
g(x)in Q1 and Q2 must be sargable for one of the arguments of the FLATTEN_KEYS() function —f1(x)orf2(x).
IN vs. WITHIN
-
Index key C1 can be used for query predicate Q1. Index key C2 can be used for both query predicates Q1 and Q2.
-
Index key C2 is strictly more expensive than index key C1, for both index maintenance and query processing. Index key C2 and query predicate Q2 are very powerful. They can efficiently index and query recursive trees of arbitrary depth.
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
CREATE INDEX idx_sched
ON route
( DISTINCT ARRAY v.flight FOR v IN schedule END );SELECT * FROM route
WHERE ANY v IN schedule SATISFIES v.flight LIKE 'UA%' END;Create a partial index (with WHERE clause) of individual attributes from selected elements (using WHEN clause) of an array.
CREATE INDEX idx_flight_sfo
ON route
( ALL ARRAY v.flight FOR v IN schedule WHEN v.day < 4 END )
WHERE sourceairport = "SFO";SELECT * FROM route
WHERE sourceairport = "SFO" (1)
AND ANY v IN schedule SATISFIES (v.flight LIKE 'UA%') (2)
AND (v.day=1) END; (3)CREATE INDEX ixf_sched
ON route
(ALL ARRAY FLATTEN_KEYS(s.day DESC, s.flight) FOR s IN schedule END,
sourceairport, destinationairport, stops);SELECT META(r).id
FROM route AS r
WHERE r.sourceairport = "SFO" (1)
AND r.destinationairport = "ATL" (2)
AND ANY s IN r.schedule SATISFIES s.day BETWEEN 1 AND 5 (3)
AND s.flight LIKE "DL%" END; (4)In this example, Query A is able to use the ixf_sched index defined by the Index, pass all the predicate information to index scan, and cover the query.
"spans": [
{
"exact": true,
"range": [
{
"high": "5",
"inclusion": 3,
"index_key": "(`s`.`day`)", (3)
"low": "1"
},
{
"high": "\"DM\"",
"inclusion": 1,
"index_key": "(`s`.`flight`)", (4)
"low": "\"DL\""
},
{
"high": "\"SFO\"",
"inclusion": 3,
"index_key": "`sourceairport`", (1)
"low": "\"SFO\""
},
{
"high": "\"ATL\"",
"inclusion": 3,
"index_key": "`destinationairport`", (2)
"low": "\"ATL\""
}
]
}
]| 1 | r.sourceairport = "SFO" is able to match and pass to IndexScan. |
| 2 | r.destinationairport = "ATL" is able to match and pass to IndexScan. |
| 3 | ARRAY predicate s.day BETWEEN 1 AND 5 is able to match and pass to IndexScan. |
| 4 | ARRAY predicate s.flight LIKE "DL%" is able to match and pass to IndexScan. |
SELECT s.day, s.flight,r.sourceairport, r.destinationairport, r.stops
FROM route AS r
UNNEST r.schedule AS s
WHERE r.sourceairport = "SFO" AND r.destinationairport = "ATL"
AND s.day BETWEEN 1 AND 5 AND s.flight LIKE "DL%"
ORDER BY s.day DESC
OFFSET 2
LIMIT 3;This query performs a covering UNNEST IndexScan, by applying all the predicates, using the ixf_sched index defined by the Index.
Even though the ORDER BY key uses an array index key, it can use index order, and pass LIMIT and OFFSET to the indexer.
The following statement creates an index of flight numbers from the schedule array for all routes.
If the schedule array is missing from any route, that route is indexed anyway.
CREATE INDEX idx_sched_missing
ON route
(DISTINCT ARRAY v.flight FOR v IN schedule END INCLUDE MISSING);The following statement creates a flattened index on the time (utc) and day from the schedule array for all routes.
If the utc element is missing from any schedule, that schedule is indexed anyway.
CREATE INDEX ixf_sched_missing
ON route
(DISTINCT ARRAY FLATTEN_KEYS(v.utc INCLUDE MISSING, v.day) FOR v IN schedule END);CREATE INDEX idx_flight_stops
ON route
( stops, DISTINCT ARRAY v.flight FOR v IN schedule END );SELECT * FROM route
WHERE stops >=1
AND ANY v IN schedule SATISFIES v.flight LIKE 'FL%' END;
Please note that the example below will alter the data in your sample buckets.
To restore your sample data, remove and reinstall the travel-sample bucket.
Refer to Sample Buckets for details.
|
UPDATE route
SET schedule[0] = {"day" : 7, "special_flights" :
[ {"flight" : "AI444", "utc" : "4:44:44"},
{"flight" : "AI333", "utc" : "3:33:33"}
] }
WHERE destinationairport = "CDG" AND sourceairport = "TLV";Use the DISTINCT ARRAY clause in a nested fashion to index specific attributes of a document when the array contains other arrays or documents that contain arrays.
CREATE INDEX idx_nested ON route
(DISTINCT ARRAY
(DISTINCT ARRAY y.flight (1)
FOR y IN x.special_flights END)
FOR x IN schedule END);| 1 | In this case, the inner ARRAY construct is used as the var_expr for the outer ARRAY construct in the SQL++ Syntax above. |
SELECT count(*) FROM route
WHERE ANY x in schedule SATISFIES
(ANY y in x.special_flights SATISFIES y.flight IS NOT NULL END)
END;This query uses the index idx_nested defined by Index I.
It returns 3 results, as there are 3 routes with special flights.
SELECT count(*) FROM route
UNNEST schedule AS x
UNNEST x.special_flights AS y
WHERE y.flight IS NOT NULL;This query uses the index idx_nested defined by Index I.
It returns 6 results, as there are 3 routes with 2 special flights each.
CREATE INDEX ixf_sched_nested ON route
(ALL ARRAY
(ALL ARRAY FLATTEN_KEYS(s.day, sf.flight)
FOR sf IN s.special_flights END)
FOR s IN schedule END);SELECT RAW count(1)
FROM route AS r
WHERE ANY s IN schedule
SATISFIES (ANY sf IN s.special_flights
SATISFIES sf.flight IS NOT NULL AND s.day = 7
END)
END;This query performs a covering UNNEST IndexScan, by applying the predicates on both levels of the ARRAY, using the index ixf_sched_nested defined by Index II.
SELECT RAW count(1)
FROM route AS r
UNNEST r.schedule AS s
UNNEST s.special_flights AS sf
WHERE sf.flight IS NOT NULL AND s.day = 7;This query performs a covering UNNEST IndexScan, by applying the predicates on both levels of the ARRAY, using the index ixf_sched_nested defined by Index II; and uses index aggregation.
CREATE INDEX idx_flight_day ON route
(DISTINCT ARRAY [v.flight, v.day] FOR v IN schedule END);SELECT meta().id FROM route
WHERE ANY v in schedule SATISFIES [v.flight, v.day] = ["US681", 2] END;CREATE INDEX idx_sched_simple
ON route (ALL schedule);The following queries find details of all route documents matching a specific schedule.
SELECT * FROM route
WHERE ANY v IN schedule
SATISFIES v = {"day":2, "flight": "US681", "utc": "19:20:00"} END; (1)| 1 | Elements of the schedule array are objects, and hence the right side value of the predicate condition should be a similarly structured object. |
SELECT * FROM route t
UNNEST schedule sch
WHERE sch = {"day":2, "flight": "US681", "utc": "19:20:00"};This is a variant of Query A using UNNEST in the SELECT statement.
SELECT META(r).id
FROM route AS r
WHERE ANY v IN r.schedule SATISFIES v.day = 2 AND v.flight = "US681" END;Covering Array Index
Covering indexes are an efficient method of using an Index for a particular query, whereby the index itself can completely cover the query in terms of providing all data required for the query. Basically, it avoids the fetch phase of the query processing and related overhead in fetching the required documents from data-service nodes. For more details, see Covering Indexes.
Array indexing requires special attention to create covering array indexes. In general, the array field itself should be included as one of the index keys in the CREATE INDEX definition. For instance, in Example 1, the Index does not cover the Query because the Query projection list includes * which needs to fetch the document from the Data Service.
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
CREATE INDEX idx_sched_cover ON route
(DISTINCT ARRAY v.flight FOR v IN schedule END, schedule);The index keys of an index must be used in the WHERE clause of a DML statement to use the index for that query. In the SELECT or DML WHERE clause, Covering Array Indexes can be used by the following operators:
EXPLAIN SELECT meta().id FROM route
USE INDEX (idx_sched_cover) (1)
WHERE ANY v IN schedule SATISFIES v.flight LIKE 'UA%' END;| 1 | In this example, Query A needs Index I to cover it because the query predicate refers to the array schedule in the ANY operator. |
[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "DistinctScan",
"scan": {
"#operator": "IndexScan3",
"bucket": "travel-sample",
"covers": [
"cover ((distinct (array (`v`.`flight`) for `v` in (`route`.`schedule`) end)))",
"cover ((`route`.`schedule`))",
"cover ((meta(`route`).`id`))"
],
"filter": "cover (any `v` in (`route`.`schedule`) satisfies ((`v`.`flight`) like \"UA%\") end)",
"filter_covers": {
"cover (any `v` in (`route`.`schedule`) satisfies ((\"UA\" <= (`v`.`flight`)) and ((`v`.`flight`) < \"UB\")) end)": true,
"cover (any `v` in (`route`.`schedule`) satisfies ((`v`.`flight`) like \"UA%\") end)": true
},
"index": "idx_sched_cover",
// ...
}
}
]
}
}
]EXPLAIN SELECT meta().id FROM route
USE INDEX (idx_sched_cover)
WHERE ANY AND EVERY v IN schedule SATISFIES v.flight LIKE 'UA%' END;[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "DistinctScan",
"scan": {
"#operator": "IndexScan3",
"bucket": "travel-sample",
"covers": [
"cover ((distinct (array (`v`.`flight`) for `v` in (`route`.`schedule`) end)))",
"cover ((`route`.`schedule`))",
"cover ((meta(`route`).`id`))"
],
"filter": "any and every `v` in cover ((`route`.`schedule`)) satisfies ((`v`.`flight`) like \"UA%\") end",
"index": "idx_sched_cover",
// ...
}
}
]
}
}
]EXPLAIN SELECT meta(t).id FROM route t
USE INDEX (idx_sched_cover)
UNNEST schedule v
WHERE v.flight LIKE 'UA%';[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "DistinctScan",
"scan": {
"#operator": "IndexScan3",
"as": "t",
"bucket": "travel-sample",
"covers": [
"cover ((distinct (array (`v`.`flight`) for `v` in (`t`.`schedule`) end)))",
"cover ((`t`.`schedule`))",
"cover ((meta(`t`).`id`))"
],
"filter": "is_array(cover ((`t`.`schedule`)))",
"index": "idx_sched_cover",
// ...
}
}
]
}
}
]|
In this example, Query A has the following limitation: the collection operator EVERY cannot use array indexes or covering array indexes because the EVERY operator needs to apply the SATISFIES predicate to all elements in the array, including the case where an array has zero elements. As items cannot be indexed, it is not possible to index MISSING items, so the EVERY operator is evaluated in the SQL++ engine and cannot leverage the array index scan. |
CREATE INDEX idx_sched_cover_all ON route
(ALL ARRAY v.flight FOR v IN schedule END, schedule);EXPLAIN SELECT meta().id FROM route
USE INDEX (idx_sched_cover_all, idx_sched_cover)
WHERE EVERY v IN schedule SATISFIES v.flight LIKE 'UA%' END;[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "PrimaryScan3",
"bucket": "travel-sample",
"index": "def_inventory_route_primary",
// ...
}
]
}
}
]Implicit Covering Array Index
SQL++ supports simplified Implicit Covering Array Index syntax in certain cases where the mandatory array index-key requirement is relaxed to create a covering array-index. This special optimization applies to those queries and DML which have WHERE clause predicates that can be exactly and completely pushed to the indexer during the array index scan.
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Note that the GSI indexes are tree structures that support exact match and range matches.
And the ANY predicate returns true as long as it finds at least one matching item in the index.
Hence, an item found in the index can cover the query.
Furthermore, this is covered by both ALL and DISTINCT array indexes.
CREATE INDEX idx_sched_cover_simple ON route
(DISTINCT ARRAY v.flight FOR v IN schedule END);EXPLAIN SELECT meta().id FROM route
USE INDEX (idx_sched_cover_simple)
WHERE ANY v IN schedule SATISFIES v.flight LIKE 'UA%' END;[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "DistinctScan",
"scan": {
"#operator": "IndexScan3",
"bucket": "travel-sample",
"covers": [
"cover ((distinct (array (`v`.`flight`) for `v` in (`route`.`schedule`) end)))",
"cover ((meta(`route`).`id`))"
],
"filter": "cover (any `v` in (`route`.`schedule`) satisfies ((`v`.`flight`) like \"UA%\") end)",
"filter_covers": {
"cover (any `v` in (`route`.`schedule`) satisfies ((\"UA\" <= (`v`.`flight`)) and ((`v`.`flight`) < \"UB\")) end)": true,
"cover (any `v` in (`route`.`schedule`) satisfies ((`v`.`flight`) like \"UA%\") end)": true
},
"index": "idx_sched_cover_simple",
// ...
}
}
]
}
}
]This applies to only ALL array indexes because, for such index, all array elements are indexed in the array index, and the UNNEST operation needs all the elements to reconstruct the array. Note that the array cannot be reconstructed if on DISTINCT elements of the array are indexed.
In this example, Query A can be covered with the ALL index idx_sched_cover_simple_all defined by the Index, but Query B is not covered when using the DISTINCT index idx_sched_cover_simple defined by the Index in Example 10.
CREATE INDEX idx_sched_cover_simple_all ON route
(ALL ARRAY v.flight FOR v IN schedule END);EXPLAIN SELECT meta(t).id FROM route t
USE INDEX (idx_sched_cover_simple_all)
UNNEST schedule v
WHERE v.flight LIKE 'UA%';[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan3",
"as": "t",
"bucket": "travel-sample",
"covers": [
"cover ((`v`.`flight`))",
"cover ((meta(`t`).`id`))"
],
"filter": "cover (is_array((`t`.`schedule`)))",
"filter_covers": {
"cover (((`t`.`schedule`) < {}))": true,
"cover (([] <= (`t`.`schedule`)))": true,
"cover (is_array((`t`.`schedule`)))": true
},
"index": "idx_sched_cover_simple_all",
"index_id": "de0704c3fdb45b07",
"keyspace": "route",
"namespace": "default",
"scope": "inventory",
"spans": [
{
"exact": true,
"range": [
{
"high": "\"UB\"",
"inclusion": 1,
"low": "\"UA\""
}
]
}
],
"using": "gsi"
},
// ...
]
}
}
]EXPLAIN SELECT meta(t).id FROM route t
USE INDEX (idx_sched_cover_simple)
UNNEST schedule v
WHERE v.flight LIKE 'UA%';[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "DistinctScan",
"scan": {
"#operator": "IndexScan3",
"as": "t",
"bucket": "travel-sample",
"index": "idx_sched_cover_simple",
"index_id": "198a2bc8b0a3ea55",
"index_projection": {
"primary_key": true
},
"keyspace": "route",
"namespace": "default",
"scope": "inventory",
"spans": [
{
"exact": true,
"range": [
{
"high": "\"UB\"",
"inclusion": 1,
"low": "\"UA\""
}
]
}
],
"using": "gsi"
}
// ...
}
]
}
}
]Summary
The following table summarizes SQL++-supported collection operators in the DML WHERE clause for different kinds of array index features:
| Operator in the SELECT/DML WHERE clause | Array Index | Covering Array Index (with explicit array index-key) | Implicit Covering Array Index (without explicit array index-key) |
|---|---|---|---|
ANY |
✓ (both ALL & DISTINCT) |
✓ (both ALL & DISTINCT) |
✓ (both ALL & DISTINCT) |
UNNEST |
✓ (only ALL, with array as leading index-key) |
✓ (only ALL, with array as leading index-key) |
✓ (only ALL, with array as leading index-key) |
ANY AND EVERY |
✓ (both ALL & DISTINCT) |
✓ (both ALL & DISTINCT) |
✘ |
EVERY |
✘ |
✘ |
✘ |
|
In Couchbase Server 6.5 and later, you can use any arbitrary alias for the right side of an UNNEST — the alias does not have to be the same as the ARRAY index variable name in order to use that index. |