SQL++ Pushdowns optimize the performance of SQL++ queries by supporting grouping and aggregate expressions.
Overview
Grouping and aggregate pushdown improves the performance of SQL++ queries with groupings and aggregations.
After the optimizer selects an index for a query block, it attempts the two optimizations below:
-
Pagination optimization, by pushing the OFFSET and LIMIT parameters to the index scan.
-
Grouping and aggregate pushdown to the indexer (introduced in Couchbase 5.5).
Prior to Couchbase Server 5.5, when a query contained aggregation and/or grouping, the query engine would fetch all relevant data from the indexer and group the data itself, even if the query was covered by an index. With Couchbase Server 5.5 (Enterprise Edition) and later, the query intelligently requests the indexer to perform grouping and aggregation in addition to range scan. The Indexer has been enhanced to perform grouping, COUNT(), SUM(), MIN(), MAX(), AVG(), and related operations.
You do not need to make any changes to the query to use this feature, but a good index design is required to cover the query and order the keys. Not every query will benefit from this optimization, and not every index can accelerate every grouping and aggregation. Understanding the right patterns will help you to design your indexes and queries. Grouping and aggregate pushdown is supported on both storage engines: Standard GSI and Memory Optimized GSI (MOI).
This reduction step reduces the amount of data transfer and disk I/O, resulting in:
-
Improved query response time
-
Improved resource utilization
-
Low latency
-
High scalability
-
Low TCO
Let’s compare query performance with and without grouping and aggregate pushdown. Consider the following generic example index and query:
CREATE INDEX idx_expr ON keyspace_ref (a); SELECT a, aggregate_function(a) FROM keyspace_ref WHERE a IS NOT MISSING GROUP BY a;
Without grouping and aggregate pushdown, the query engine fetches relevant data from the indexer, and then the query engine groups and aggregates the data, as shown in the typical query execution plan below.

With grouping and aggregate pushdown, the query uses the same index, but the indexer does the grouping and aggregation as well. In the typical query execution plan below, you can see fewer steps, and note the lack of the grouping step after the index scan.

With grouping and aggregate pushdown, this simple generic query typically executes in less than a third of the time. As the data and query complexity grows, the performance benefit (both latency and throughput) will grow as well.
The query plan shows the accelerated aggregation details. For details, see Appendix: Query Plan Fields.
Here’s how a query executes when the indexer handles the grouping and aggregation. Note that the query engine does not fetch any data from the data service (KV service).

For reference, this is how the same query would be executed without grouping and aggregate pushdown.

Examples for Grouping and Aggregation
Consider a composite index:
CREATE INDEX idx_grp_add ON airport
(geo.alt, geo.lat, geo.lon, id);This section considers sample queries that can benefit from this optimization, and queries that cannot.
- Positive Case examples of queries that use indexing grouping and aggregation
SELECT COUNT(*) FROM airport WHERE geo.alt > 10;
SELECT COUNT(geo.alt) FROM airport
WHERE geo.alt BETWEEN 10 AND 30;
SELECT COUNT(geo.lat) FROM airport
WHERE geo.alt BETWEEN 10 AND 30 AND geo.lat = 40;
SELECT geo.alt, AVG(id), SUM(id), COUNT(geo.alt), MIN (geo.lon), MAX(ABS(geo.lon))
FROM airport WHERE geo.alt > 100 GROUP BY geo.alt;
SELECT lat_count, SUM(id) FROM airport
WHERE geo.alt > 100 GROUP BY geo.alt
LETTING lat_count = COUNT(geo.lat) HAVING lat_count > 1;
SELECT AVG(DISTINCT geo.lat) FROM airport
WHERE geo.alt > 100 GROUP BY geo.alt;
SELECT ARRAY_AGG(geo.alt) FROM airport
WHERE geo.alt > 10;- Negative Case examples
SELECT COUNT(*) FROM airport WHERE geo.lat > 20;This query has no predicate on the leading key geo.alt.
The index idx_grp_add cannot be used.
SELECT COUNT(*) FROM airport;This query has no predicate at all.
SELECT COUNT(v1) FROM airport
LET v1 = ROUND(geo.lat) WHERE geo.lat > 10;The aggregate depends on LET variable.
Positive query examples with GROUP BY on leading index keys
The following example uses the idx_grp_add index defined previously:
CREATE INDEX idx_grp_add ON airport
(geo.alt, geo.lat, geo.lon, id);In the following query, the GROUP BY keys (geo.alt, geo.lat) are the leading keys of the index, so the index is naturally ordered and grouped by the order of the index key definition.
Therefore, the query below is suitable for indexer to handle grouping and aggregation.
SELECT geo.alt, geo.lat, SUM(geo.lon), AVG(id), COUNT(DISTINCT geo.lon)
FROM airport
WHERE geo.alt BETWEEN 10 AND 30
GROUP BY geo.alt, geo.lat
HAVING SUM(geo.lon) > 1000;The query plan shows that the index scan handles grouping and aggregation:

Positive query examples with GROUP BY on non-leading index keys
The following example uses the idx_grp_add index defined previously:
CREATE INDEX idx_grp_add ON airport
(geo.alt, geo.lat, geo.lon, id);
SELECT geo.lat, id, SUM(geo.lon)
FROM airport
WHERE geo.alt BETWEEN 10 AND 30
GROUP BY geo.lat, id
HAVING SUM(geo.lon) > 1000;In this case, the indexer sends partial group aggregation, which the query merges to create the final group and aggregation.
In this scenario (when the grouping is on non-leading keys), any query with aggregation and DISTINCT modifier cannot be accelerated by the indexer, such as COUNT(DISTINCT id).

Positive query examples on array indexes with GROUP BY on leading index keys
Consider the following index and query:
CREATE INDEX idx_grp_add_distinct ON hotel
(geo.lat, geo.lon, DISTINCT public_likes, id);
SELECT geo.lat, geo.lon, SUM(id), AVG(id)
FROM hotel
WHERE geo.lat BETWEEN 10 AND 30
AND geo.lon > 50
AND ANY v IN public_likes SATISFIES v = "%a%" END
GROUP BY geo.lat, geo.lon
HAVING SUM(id) > 100;In this case, the predicates are on the leading keys up to and including the array key.
Therefore, indexer can efficiently do the grouping as seen by the optimal plan below.
It’s important to note the array index key is created with a DISTINCT modifier (not the ALL modifier) to get this optimization and that the SATISFIES clause in the ANY predicate must be that of equality (that is, v = "%a%").

Consider the index and query:
CREATE INDEX idx_grp_add_all ON hotel
(ALL public_likes, geo.lat, geo.lon, id);
SELECT un, t.geo.lat, COUNT(un), AVG(t.geo.lat)
FROM hotel AS t
UNNEST t.public_likes AS un
WHERE un > "J"
GROUP BY un, t.geo.lat;In this case, the UNNEST operation can use the index because the leading ALL array key is the array being unwound.
Note, the unwound operation repeats the parent document (hotel) and the t.geo.lat reference would have duplicates compared to the original hotel documents.
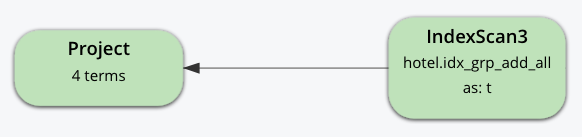
Query Qualification and Pushdown
Not every GROUP BY and aggregate query can be handled by the indexer. Following are some simple rules that will help you to write the proper queries and design the required indexes to get the most of this feature.
The following are necessary in order for an indexer to execute GROUP BY and aggregates:
-
All the query predicates are able to convert into ranges and able to push to indexer.
-
The whole query must be covered by an index.
-
For a query to be covered by an index, every attribute referenced in the query should be in one index.
-
Query should not have operations such as joins, subquery, or derived table queries.
-
-
GROUP BY keys and Aggregate expressions must be one of the following:
-
Index keys or document key
-
An expression based on index keys or document key
-
-
GROUP BY and aggregate expressions must be simple.
Scenarios for Grouping and Aggregation
Like any feature in a query language, there are subtle variations between each query and index that affects this optimization. We use the travel sample dataset to illustrate both positive and negative use cases.
The following table lists the scenarios and requirements for queries to request the indexer to do the grouping and acceleration. When the requirements are unmet, the query will fetch the relevant data and then do the grouping and acceleration as usual. No application changes are necessary. The query plan generated reflects this decision.
- GROUP BY Scenarios
- Aggregate Scenarios
GROUP BY on leading keys
One of the common cases is to have both predicates and GROUP BY on leading keys of the index. First create the index so that the query is covered by the index. You can then think about the order of the keys.
The query requires a predicate on leading keys to consider an index.
The simplest predicate is IS NOT MISSING.
CREATE INDEX idx_expr ON keyspace_ref (a, b, c); SELECT a, b, aggregate_function(c) (1) FROM keyspace_ref WHERE a IS NOT MISSING (2) GROUP BY a, b;
| 1 | Where aggregate_function(c) is MIN(c), MAX(c), COUNT(c), or SUM(c) |
| 2 | 1st index field must be in a WHERE clause |
Use the MAX() aggregate to find the highest landmark latitude in each state, group the results by country and state, and then sort in reverse order by the highest latitudes per state.
CREATE INDEX idx1 ON landmark
(country, state, geo.lat);SELECT country, state, MAX(ROUND(geo.lat)) AS Max_Latitude
FROM landmark
WHERE country IS NOT MISSING
GROUP BY country, state
ORDER BY Max_Latitude DESC;In this query, we need to give the predicate country IS NOT MISSING (or any WHERE clause) to ensure this index is selected for the query.
Without a matching predicate, the query will use the primary index.
[
{
"Max_Latitude": 60,
"country": "United Kingdom",
"state": null
},
{
"Max_Latitude": 51,
"country": "United Kingdom",
"state": "England"
},
{
"Max_Latitude": 50,
"country": "France",
"state": "Picardie"
},
...
]{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan3",
"bucket": "travel-sample",
"covers": [
"cover ((`landmark`.`country`))",
"cover ((`landmark`.`state`))",
"cover (((`landmark`.`geo`).`lat`))",
"cover ((meta(`landmark`).`id`))",
"cover (max(round(cover (((`landmark`.`geo`).`lat`)))))"
],
"index": "idx1",
"index_group_aggs": {
"aggregates": [
{
"aggregate": "MAX",
"depends": [
2
],
"expr": "round(cover (((`landmark`.`geo`).`lat`)))",
"id": 4,
"keypos": -1
}
],
"depends": [
0,
1,
2
],
"group": [
{
"depends": [
0
],
"expr": "cover ((`landmark`.`country`))",
"id": 0,
"keypos": 0
},
{
"depends": [
1
],
"expr": "cover ((`landmark`.`state`))",
"id": 1,
"keypos": 1
}
]
},
...
}
]
}
]
}
}The query plan shows that grouping is executed by the indexer. This is detailed in Table 2.
GROUP BY on non-leading keys
When using GROUP BY on a non-leading key:
-
The indexer will return pre-aggregated results.
-
Results can have duplicate or out-of-order groups. The SQL++ indexer will do 2nd level of aggregation and compute the final result.
-
The SQL++ indexer can pushdown only if the leading key has a predicate.
To use Aggregate Pushdown, use the following syntax for the index and query statements:
CREATE INDEX idx_expr ON keyspace_ref (a, b, c);
SELECT aggregate_function(a), b, aggregate_function(c) FROM keyspace_ref WHERE a IS NOT MISSING GROUP BY b;
SELECT aggregate_function(a), aggregate_function(b), c FROM keyspace_ref WHERE a IS NOT MISSING GROUP BY c;
Use the COUNT() operator to find the total number of landmarks and use the MIN() operator to find the lowest landmark latitude in each state, group the results by state, and then sort in order by the lowest latitudes per state.
This example uses the idx1 index defined previously:
CREATE INDEX idx1 ON landmark
(country, state, geo.lat);SELECT COUNT(country) AS Total_landmarks, state, MIN(ROUND(geo.lat)) AS Min_Latitude
FROM landmark
WHERE country IN ["France", "United States", "United Kingdom"]
GROUP BY state
ORDER BY Min_Latitude;{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan3",
"bucket": "travel-sample",
"covers": [
"cover ((`landmark`.`country`))",
"cover ((`landmark`.`state`))",
"cover (((`landmark`.`geo`).`lat`))",
"cover ((meta(`landmark`).`id`))",
"cover (count(cover ((`landmark`.`country`))))",
"cover (min(round(cover (((`landmark`.`geo`).`lat`)))))"
],
"index": "idx1",
"index_group_aggs": {
"aggregates": [
{
"aggregate": "COUNT",
"depends": [
0
],
"expr": "cover ((`landmark`.`country`))",
"id": 4,
"keypos": 0
},
{
"aggregate": "MIN",
"depends": [
2
],
"expr": "round(cover (((`landmark`.`geo`).`lat`)))",
"id": 5,
"keypos": -1
}
],
"depends": [
0,
1,
2
],
"group": [
{
"depends": [
1
],
"expr": "cover ((`landmark`.`state`))",
"id": 1,
"keypos": 1
}
],
"partial": true (1)
},
...
}
]
}
]
}
}
[
{
"Min_Latitude": 33,
"Total_landmarks": 1900,
"state": "California"
},
{
"Min_Latitude": 41,
"Total_landmarks": 8,
"state": "Corse"
},
{
"Min_Latitude": 43,
"Total_landmarks": 2208,
"state": null
},
...
]| 1 | The "partial": true line means it was pre-aggregated. |
Use COUNT(country) for the total number of landmarks at each latitude.
At a particular latitude, the state will be the same; but an aggregate function on it is needed, so MIN() or MAX() is used to return the original value.
SELECT COUNT(country) Num_Landmarks, MIN(state) State_Name, ROUND(geo.lat) Latitude
FROM landmark
WHERE country IS NOT MISSING
GROUP BY ROUND(geo.lat)
ORDER BY ROUND(geo.lat);[
{
"Latitude": 33,
"Num_Landmarks": 227,
"State_Name": "California"
},
{
"Latitude": 34,
"Num_Landmarks": 608,
"State_Name": "California"
},
{
"Latitude": 35,
"Num_Landmarks": 27,
"State_Name": "California"
},
...
]GROUP BY keys in different CREATE INDEX order
When using GROUP BY on keys in a different order than they appear in the CREATE INDEX statement, use the following syntax:
CREATE INDEX idx_expr ON keyspace_ref(a, b, c); SELECT aggregate_function(c) FROM keyspace_ref WHERE a IS NOT MISSING GROUP BY b, a;
Like Example 1 with the GROUP BY fields swapped.
Use the MIN() operator to find the lowest landmark longitude in each city, group the results by activity and city, and then sort in reverse order by the lowest longitudes per activity.
CREATE INDEX idx3 ON landmark
(activity, city, geo.lon);SELECT activity, city, MIN(ROUND(geo.lon)) AS Min_Longitude
FROM landmark
WHERE country IS NOT MISSING
GROUP BY activity, city
ORDER BY Min_Longitude, activity;[
{
"Min_Longitude": -124,
"activity": "buy",
"city": "Eureka"
},
{
"Min_Longitude": -123,
"activity": "eat",
"city": "Santa Rosa"
},
{
"Min_Longitude": -123,
"activity": "eat",
"city": "Sebastopol"
},
{
"Min_Longitude": -123,
"activity": "see",
"city": "Sebastopol"
},
...
]GROUP BY on expression
When grouping on an expression or operation, the indexer will return pre-aggregated results whenever the GROUP BY and leading index keys are not an exact match.
To use Aggregate Pushdown and avoid pre-aggregated results, use one of the two following syntaxes for the index and query statements:
CREATE INDEX idx_expr ON keyspace_ref(a+b, b, c); SELECT aggregate_function(c) FROM keyspace_ref WHERE a IS NOT MISSING GROUP BY a+b;
CREATE INDEX idx_operation ON keyspace_ref (LOWER(a), b, c); SELECT aggregate_function(c) FROM keyspace_ref WHERE a IS NOT MISSING GROUP BY LOWER(a);
For comparison, the below index and query combination will yield pre-aggregated results.
CREATE INDEX idx_operation ON keyspace_ref (a, b, c); SELECT aggregate_function(c) FROM keyspace_ref WHERE a IS NOT MISSING GROUP BY UPPER(a);
Let’s say the distance of a flight feels like "nothing" when it’s direct, but feels like the true distance when there is one layover. Then we can list and group by flight distances by calculating the distance multiplied by the stops it makes.
CREATE INDEX idx4_expr ON route
(ROUND(distance*stops), ROUND(distance), sourceairport);SELECT ROUND(distance*stops) AS Distance_Feels_Like,
MAX(ROUND(distance)) AS Distance_True,
COUNT(sourceairport) Number_of_Airports
FROM route
WHERE ROUND(distance*stops) IS NOT MISSING
GROUP BY ROUND(distance*stops);...
"index_group_aggs": {
"aggregates": [
{
"aggregate": "COUNT",
"depends": [
2
],
"expr": "cover ((`route`.`sourceairport`))",
"id": 4,
"keypos": 2
},
{
"aggregate": "MAX",
"depends": [
1
],
"expr": "cover (round((`route`.`distance`)))",
"id": 5,
"keypos": 1
}
],
"depends": [
0,
1,
2
],
"group": [
{
"depends": [
0
],
"expr": "cover (round(((`route`.`distance`) * (`route`.`stops`))))",
"id": 0,
"keypos": 0
}
]
},
...
[
{
"Distance_Feels_Like": 0,
"Distance_True": 13808,
"Number_of_Airports": 24018
},
{
"Distance_Feels_Like": 309,
"Distance_True": 309,
"Number_of_Airports": 1
},
{
"Distance_Feels_Like": 1055,
"Distance_True": 1055,
"Number_of_Airports": 1
},
...
]Let’s say the distance of a flight feels like "nothing" when it’s direct, but feels like the true distance when there is one layover. Then we can list and group by the uppercase of the airport codes and listing the flight distances by calculating the distance multiplied by the stops it makes along with the total distance.
CREATE INDEX idx4_oper ON route
(sourceairport, ROUND(distance*stops), distance);SELECT UPPER(sourceairport) AS Airport_Code,
MIN(ROUND(distance*stops)) AS Distance_Feels_Like,
SUM(ROUND(distance)) AS Total_Distance
FROM route
WHERE sourceairport IS NOT MISSING
GROUP BY UPPER(sourceairport);[
{
"Airport_Code": "ITO",
"Distance_Feels_Like": 0,
"Total_Distance": 4828
},
{
"Airport_Code": "GJT",
"Distance_Feels_Like": 0,
"Total_Distance": 6832
},
{
"Airport_Code": "HYA",
"Distance_Feels_Like": 0,
"Total_Distance": 148
},
...
]Heterogeneous data types for GROUP BY key
When a field has a mix of data types for the GROUP BY key:
-
NULLSandMISSINGare two separate groups.
To see a separate grouping of MISSING and NULL, we need to GROUP BY a field we know exists in one document but not in another document while both documents have another field in common.
INSERT INTO landmark
VALUES("01",{"type":1, "email":"abc","xx":3});
INSERT INTO landmark
VALUES("02",{"type":1, "email":"abc","xx":null});
INSERT INTO landmark
VALUES("03",{"type":1, "email":"abcd"});SELECT type, xx, MIN(email) AS Min_Email
FROM landmark
WHERE type IS NOT NULL
GROUP BY type, xx;[
{
"Min_Email": "abc",
"type": 1,
"xx": 3
},
{
"Min_Email": "abc",
"type": 1,
"xx": null
},
{
"Min_Email": "abcd",
"type": 1 (1)
},
{
"Min_Email": "2willowroad@nationaltrust.org.uk",
"type": "landmark"
}
]| 1 | This is a separate result since field xx is MISSING |
GROUP BY META().ID Primary Index
If there is no filter, then pushdown is supported for an expression on the Document ID META().id in the GROUP BY clause.
To use Aggregate Pushdown, use the following syntax for the index and query statement:
CREATE PRIMARY INDEX idx_expr ON named_keyspace_ref; SELECT COUNT(1) FROM named_keyspace_ref GROUP BY SUBSTR(META().id, start, finish);
| If there is a filter on the Document ID, then the primary index can be used as a secondary scan. |
META().id fieldCREATE PRIMARY INDEX idx6 ON airport;SELECT COUNT(1) AS Count, SUBSTR(META().id,0,9) AS Meta_Group
FROM airport
GROUP BY SUBSTR(META().id,0,9);[
{
"Count": 168,
"Meta_Group": "airport_4"
},
{
"Count": 175,
"Meta_Group": "airport_5"
},
{
"Count": 125,
"Meta_Group": "airport_6"
},
...
]LIMIT with GROUP BY on leading keys
To use Aggregate Pushdown when there is a LIMIT clause and a GROUP BY clause on one or more leading keys, use the following example of the index and query statement:
CREATE INDEX idx_expr ON named_keyspace_ref (k0, k1); SELECT k0, COUNT(k1) FROM named_keyspace_ref WHERE k0 IS NOT MISSING GROUP BY k0 LIMIT n;
CREATE INDEX idx7 ON landmark
(city, name);SELECT city AS City, COUNT(DISTINCT name) AS Landmark_Count
FROM landmark
WHERE city IS NOT MISSING
GROUP BY city
LIMIT 4;{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan3",
"bucket": "travel-sample",
"covers": [
"cover ((`landmark`.`city`))",
"cover ((`landmark`.`name`))",
"cover ((meta(`landmark`).`id`))",
"cover (count(DISTINCT cover ((`landmark`.`name`))))"
],
"index": "idx7",
"index_group_aggs": {
"aggregates": [
{
"aggregate": "COUNT",
"depends": [
1
],
"distinct": true,
"expr": "cover ((`landmark`.`name`))",
"id": 3,
"keypos": 1
}
],
"depends": [
0,
1
],
"group": [
{
"depends": [
0
],
"expr": "cover ((`landmark`.`city`))",
"id": 0,
"keypos": 0
}
]
},
"index_id": "7fe5ede3626e6d29",
"index_projection": {
"entry_keys": [
0,
3
]
},
"keyspace": "landmark",
"limit": "4", (1)
"namespace": "default",
...
}
]
}
]
}
}[
{
"City": null,
"Landmark_Count": 15
},
{
"City": "Abbeville",
"Landmark_Count": 1
},
{
"City": "Abbots Langley",
"Landmark_Count": 19
},
{
"City": "Aberdeenshire",
"Landmark_Count": 6
}
]| 1 | The limit is pushed to the indexer because the GROUP BY key matched with the leading index key. |
OFFSET with GROUP BY on leading keys
To use Aggregate Pushdown when there is an OFFSET clause and a GROUP BY clause on one or more leading keys, use the following example of the index and query statement.
CREATE INDEX idx_expr ON named_keyspace_ref (k0, k1); SELECT k0, COUNT(k1) FROM named_keyspace_ref WHERE k0 IS NOT MISSING GROUP BY k0 OFFSET n;
This example uses the idx7 index defined previously:
CREATE INDEX idx7 ON landmark
(city, name);SELECT city AS City, COUNT(DISTINCT name) AS Landmark_Count
FROM landmark
WHERE city IS NOT MISSING
GROUP BY city
OFFSET 4;{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan3",
"bucket": "travel-sample",
"covers": [
"cover ((`landmark`.`city`))",
"cover ((`landmark`.`name`))",
"cover ((meta(`landmark`).`id`))",
"cover (count(DISTINCT cover ((`landmark`.`name`))))"
],
"index": "idx7",
"index_group_aggs": {
"aggregates": [
{
"aggregate": "COUNT",
"depends": [
1
],
"distinct": true,
"expr": "cover ((`landmark`.`name`))",
"id": 3,
"keypos": 1
}
],
"depends": [
0,
1
],
"group": [
{
"depends": [
0
],
"expr": "cover ((`landmark`.`city`))",
"id": 0,
"keypos": 0
}
]
},
"index_id": "7fe5ede3626e6d29",
"index_projection": {
"entry_keys": [
0,
3
]
},
"keyspace": "landmark",
"namespace": "default",
"offset": "4", (1)
"scope": "inventory",
"spans": [
...
]
}
]
}
]
}
}[
{
"City": "Aberdour",
"Landmark_Count": 4
},
{
"City": "Aberdulais",
"Landmark_Count": 1
},
{
"City": "Abereiddy",
"Landmark_Count": 1
},
{
"City": "Aberfeldy",
"Landmark_Count": 2
},
...
]| 1 | The offset is pushed to the indexer because the GROUP BY key matched with the leading index key. |
Aggregate without GROUP BY key
This is a case of aggregation over a range without groups. If the index can be used for computing the aggregate, the indexer will return a single aggregate value. To use Aggregate Pushdown, use the following syntax for index and queries:
CREATE INDEX idx_expr ON named_keyspace_ref (a, b, c);
SELECT aggregate_function(c) FROM named_keyspace_ref WHERE a IS NOT MISSING;
SELECT SUM(a) FROM named_keyspace_ref WHERE a IS NOT MISSING;
SELECT SUM(a), COUNT(a), MIN(a) FROM named_keyspace_ref WHERE a IS NOT MISSING;
SELECT SUM(a), COUNT(b), MIN(c) FROM named_keyspace_ref WHERE a IS NOT MISSING;
CREATE INDEX idx9 ON route
(distance, stops, sourceairport);SELECT SUM(ROUND(distance)) AS Total_Distance,
SUM(stops) AS Total_Stops,
COUNT(sourceairport) AS Total_Airports
FROM route
WHERE distance IS NOT MISSING;[
{
"Total_Airports": 24024,
"Total_Distance": 53538071,
"Total_Stops": 6
}
]SELECT SUM(ROUND(distance)) AS Total_Distance
FROM route;[
{
"Total_Distance": 53538071
}
]SELECT SUM(ROUND(distance)) AS Total_Distance,
COUNT(ROUND(distance)) AS Count_of_Distance,
MIN(ROUND(distance)) AS Min_of_Distance
FROM route
WHERE distance IS NOT MISSING;[
{
"Count_of_Distance": 24024,
"Min_of_Distance": 3,
"Total_Distance": 53538071
}
]SELECT SUM(ROUND(distance)) AS Total_Distance,
COUNT(stops) AS Count_of_Stops,
MIN(sourceairport) AS Min_of_Airport
FROM route
WHERE distance IS NOT MISSING;[
{
"Count_of_Stops": 24024,
"Min_of_Airport": "AAE",
"Total_Distance": 53538071
}
]Expression in Aggregate function
Aggregations with scalar expressions can be speeded up even if the index key does not have the matching expression on the key. To use Aggregate Pushdown, use the following syntax for the index and query statement:
CREATE INDEX idx_expr ON named_keyspace_ref (a, b, c); SELECT aggregate_function1(expression(c)) FROM named_keyspace_ref WHERE a IS NOT MISSING GROUP BY a, b;
Use the MAX() operator to find the highest landmark latitude in each state, group the results by country and state, and then sort in reverse order by the highest latitudes.
CREATE INDEX idx10 ON landmark
(country, state, ABS(ROUND(geo.lat)));SELECT country, state, SUM(ABS(ROUND(geo.lat))) AS SumAbs_Latitude
FROM landmark
USE INDEX (idx10) (1)
WHERE country IS NOT MISSING
GROUP BY country, state
ORDER BY SumAbs_Latitude DESC;| 1 | Specifies that the query must use idx10 rather than the similar idx1 |
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan3",
"bucket": "travel-sample",
"covers": [
"cover ((`landmark`.`country`))",
"cover ((`landmark`.`state`))",
"cover (abs(round(((`landmark`.`geo`).`lat`))))",
"cover ((meta(`landmark`).`id`))",
"cover (sum(cover (abs(round(((`landmark`.`geo`).`lat`))))))"
],
"index": "idx10",
"index_group_aggs": {
"aggregates": [
{
"aggregate": "SUM",
"depends": [
2
],
"expr": "cover (abs(round(((`landmark`.`geo`).`lat`))))",
"id": 4,
"keypos": 2
}
],
"depends": [
0,
1,
2
],
"group": [
{
"depends": [
0
],
"expr": "cover ((`landmark`.`country`))",
"id": 0,
"keypos": 0
},
{
"depends": [
1
],
"expr": "cover ((`landmark`.`state`))",
"id": 1,
"keypos": 1
}
...
]
}
}
]
}
]
}
}The query plan shows that aggregates are executed by the indexer. This is detailed in Table 3.

[
{
"SumAbs_Latitude": 117513,
"country": "United Kingdom",
"state": null
},
{
"SumAbs_Latitude": 68503,
"country": "United States",
"state": "California"
},
{
"SumAbs_Latitude": 10333,
"country": "France",
"state": "Île-de-France"
},
...
]SUM, COUNT, MIN, MAX, or AVG Aggregate functions
Currently, the only aggregate functions that are supported are SUM(), COUNT(), MIN(), MAX(), and AVG() with or without the DISTINCT modifier.
To use Aggregate Pushdown, use the below syntax for the index and query statement:
CREATE INDEX idx_expr ON named_keyspace_ref (a, b, c, d);
SELECT aggregate_function(a), aggregate_function(b),
aggregate_function(c), aggregate_function(d)
FROM named_keyspace_ref
WHERE a IS NOT MISSING
GROUP BY a;
CREATE INDEX idx11 ON airport
(geo.lat, geo.alt, city, geo.lon);SELECT MIN(ROUND(geo.lat)) AS Min_Lat,
SUM(geo.alt) AS Sum_Alt,
COUNT(city) AS Count_City,
MAX(ROUND(geo.lon)) AS Max_Lon
FROM airport
WHERE geo.lat IS NOT MISSING
GROUP BY (ROUND(geo.lat))
ORDER BY (ROUND(geo.lat)) DESC;[
{
"Count_City": 1,
"Max_Lon": 43,
"Min_Lat": 72,
"Sum_Alt": 149
},
{
"Count_City": 3,
"Max_Lon": -157,
"Min_Lat": 71,
"Sum_Alt": 120
},
{
"Count_City": 6,
"Max_Lon": -144,
"Min_Lat": 70,
"Sum_Alt": 292
},
...
]DISTINCT aggregates
There are four cases when DISTINCT aggregates can use this feature:
-
If the DISTINCT aggregate is on the leading GROUP BY key(s).
-
If the DISTINCT aggregate is on the leading GROUP By key(s) + 1 (the immediate next key).
-
If the DISTINCT aggregate is on a constant expression (GROUP BY can be on any key).
-
If there is no GROUP BY and the DISTINCT aggregate is on the first key only or in a constant expression.
To use Aggregate Pushdown, use one of the following syntaxes of the index and query statements:
Case 1
If the DISTINCT aggregate is on the leading GROUP BY key(s).
CREATE INDEX idx_expr ON named_keyspace_ref (a, b, c);
SELECT SUM(DISTINCT a) FROM named_keyspace_ref WHERE a IS NOT MISSING GROUP BY a;
SELECT COUNT(DISTINCT a), SUM(DISTINCT b) FROM named_keyspace_ref WHERE a IS NOT MISSING GROUP BY a, b;
CREATE INDEX idx12_1 ON airport
(geo.lat, geo.lon, country);SELECT SUM(DISTINCT ROUND(geo.lat)) AS Sum_Lat
FROM airport
WHERE geo.lat IS NOT MISSING
GROUP BY ROUND(geo.lat);[
{
"Sum_Lat": 27
},
{
"Sum_Lat": 36
},
{
"Sum_Lat": 71
},
...
]SELECT COUNT(DISTINCT ROUND(geo.lat)) AS Count_Lat,
SUM(DISTINCT ROUND(geo.lon)) AS Sum_Lon
FROM airport
WHERE geo.lat IS NOT MISSING
GROUP BY ROUND(geo.lat), ROUND(geo.lon);[
{
"Count_Lat": 1,
"Sum_Lon": -166
},
{
"Count_Lat": 1,
"Sum_Lon": -107
},
{
"Count_Lat": 1,
"Sum_Lon": -159
},
...
]Case 2
If the DISTINCT aggregate is on the leading GROUP BY key(s) + 1 (the next key).
CREATE INDEX idx_expr ON named_keyspace_ref (a, b, c);
SELECT SUM(DISTINCT b) FROM named_keyspace_ref WHERE a IS NOT MISSING GROUP BY a;
SELECT COUNT(DISTINCT c) FROM named_keyspace_ref WHERE a IS NOT MISSING GROUP BY a, b;
CREATE INDEX idx12_2 ON airport
(country, ROUND(geo.lat), ROUND(geo.lon));SELECT COUNT(DISTINCT country) AS Count_Country,
SUM(DISTINCT ROUND(geo.lat)) AS Sum_Lat
FROM airport
WHERE country IS NOT MISSING
GROUP BY country;[
{
"Count_Country": 1,
"Sum_Lat": 483
},
{
"Count_Country": 1,
"Sum_Lat": 591
},
{
"Count_Country": 1,
"Sum_Lat": 2290
}
]SELECT COUNT(DISTINCT country) AS Count_Country,
SUM(DISTINCT ROUND(geo.lat)) AS Sum_Lat,
COUNT(DISTINCT ROUND(geo.lon)) AS Count_Lon
FROM airport
WHERE country IS NOT MISSING
GROUP BY country, ROUND(geo.lat);[
{
"Count_Country": 1,
"Count_Lon": 1,
"Sum_Lat": 18
},
{
"Count_Country": 1,
"Count_Lon": 1,
"Sum_Lat": 42
},
{
"Count_Country": 1,
"Count_Lon": 9,
"Sum_Lat": 43
},
...
]Case 3
If the DISTINCT aggregate is on a constant expression — GROUP BY can be on any key.
CREATE INDEX idx_expr ON named_keyspace_ref (a, b, c); SELECT a, COUNT(DISTINCT 1) FROM named_keyspace_ref WHERE a IS NOT MISSING GROUP BY b;
The results will be pre-aggregated if the GROUP BY key is non-leading, as in this case and example.
|
CREATE INDEX idx12_3 ON airport
(country, geo.lat, geo.lon);SELECT MIN(country) AS Min_Country,
COUNT(DISTINCT 1) AS Constant_Value,
MIN(ROUND(geo.lon)) AS Min_Longitude
FROM airport
WHERE country IS NOT MISSING
GROUP BY geo.lat;[
{
"Constant_Value": 1,
"Min_Country": "United States",
"Min_Longitude": -103
},
{
"Constant_Value": 1,
"Min_Country": "France",
"Min_Longitude": 3
},
{
"Constant_Value": 1,
"Min_Country": "United States",
"Min_Longitude": -105
},
...
]Case 4
If the DISTINCT aggregate is on the first key only or in a constant expression, and there is no GROUP BY clause.
CREATE INDEX idx_expr ON named_keyspace_ref (a, b, c);
SELECT aggregate_function(DISTINCT a) FROM named_keyspace_ref; (1)
SELECT aggregate_function(DISTINCT 1) FROM named_keyspace_ref; (2)
SELECT aggregate_function(DISTINCT c) FROM named_keyspace_ref; (3)
| 1 | OK |
| 2 | OK |
| 3 | Not OK |
All other cases of DISTINCT pushdown will return an error.
A DISTINCT aggregate on the first key only, where there is no GROUP BY clause.
CREATE INDEX idx12_4 ON airport
(geo.alt, geo.lat, geo.lon);SELECT SUM(DISTINCT ROUND(geo.alt)) AS Sum_Alt
FROM airport
WHERE geo.alt IS NOT MISSING;[
{
"Sum_Alt": 1463241
}
]A DISTINCT aggregate on a constant expression, where there is no GROUP BY clause.
This query pushes the aggregation down to the indexer, but does not necessarily use the index idx12_4.
SELECT COUNT(DISTINCT 1) AS Const_expr
FROM airport;[
{
"Const_expr": 1
}
]A DISTINCT aggregate on a non-leading key, where there is no GROUP BY clause.
This query uses the index idx12_4, but does not push the aggregation down to the indexer.
SELECT SUM(DISTINCT ROUND(geo.lon)) AS Sum_Lon
FROM airport
WHERE geo.alt IS NOT MISSING;[
{
"Sum_Lon": -11412
}
]HAVING with an aggregate function inside
To use Aggregate Pushdown when a HAVING clause has an aggregate function inside, use the following syntax of index and query statement:
CREATE INDEX idx_expr ON named_keyspace_ref (k0, k1); SELECT k0, COUNT(k1) FROM named_keyspace_ref WHERE k0 IS NOT MISSING GROUP BY k0 HAVING aggregate_function(k1);
List the cities that have more than 180 landmarks.
This example uses the idx7 index defined previously:
CREATE INDEX idx7 ON landmark
(city, name);SELECT city AS City, COUNT(DISTINCT name) AS Landmark_Count
FROM landmark
WHERE city IS NOT MISSING
GROUP BY city
HAVING COUNT(DISTINCT name) > 180;[
{
"City": "London",
"Landmark_Count": 443
},
{
"City": "Los Angeles",
"Landmark_Count": 284
},
{
"City": "San Diego",
"Landmark_Count": 197
},
{
"City": "San Francisco",
"Landmark_Count": 797
}
]LETTING with an aggregate function inside
To use Aggregate Pushdown when a LETTING clause has an aggregate function inside, use the following syntax of the index and query statement.
CREATE INDEX idx_expr ON named_keyspace_ref (k0, k1); SELECT k0, COUNT(k1) FROM named_keyspace_ref WHERE k0 IS NOT MISSING GROUP BY k0 LETTING var_expr = aggregate_function(k1) HAVING var_expr;
List cities that have more than half of all landmarks.
This example uses the idx7 index defined previously:
CREATE INDEX idx7 ON landmark
(city, name);SELECT city AS City, COUNT(DISTINCT name) AS Landmark_Count
FROM landmark
WHERE city IS NOT MISSING
GROUP BY city
LETTING MinimumThingsToSee = COUNT(DISTINCT name)
HAVING MinimumThingsToSee > 180;[
{
"City": "London",
"Landmark_Count": 443
},
{
"City": "Los Angeles",
"Landmark_Count": 284
},
{
"City": "San Diego",
"Landmark_Count": 197
},
{
"City": "San Francisco",
"Landmark_Count": 797
}
]Limitations
The following are currently not supported and not pushed to the indexer:
-
HAVINGorLETTINGclauses, unless there is an aggregate function inside. -
ORDER BYclauses. -
ARRAY_AGG()or any facility to add new Aggregate function, such as Median. -
LIMITpushdown withGROUP BYon non-leading keys. -
OFFSETpushdown withGROUP BYon non-leading keys. -
A subquery in a
GROUP BYor Aggregate pushdown. -
FILTERclauses on aggregate functions.
| Item | Aggregate on Non-Array Index Field | Aggregate on Array Index Field | DISTINCT Aggregate on Non-Array Index Field | DISTINCT Aggregate on Array Index Field |
|---|---|---|---|---|
Supports |
✓ |
✓ |
- |
- |
Supports |
- |
✓ |
✓ |
✓ |
Supports |
✓ |
✓ |
✓ |
✓ |
Supports |
- |
- |
- |
- |
FILTER Clause
If the query block contains an aggregate function which uses the FILTER clause, the aggregation is not pushed down to the indexer. As a workaround, if you require aggregation pushdown, you can use a comparison operator as the argument for the aggregate function. For example:
SELECT
SUM(d.c3) FILTER (WHERE d.c2 IN ['X']),
COUNT(1) FILTER (WHERE d.c2 IN ['Y'])
...SELECT
SUM (CASE WHEN d.c2 IN ['X'] THEN d.c3 ELSE 0 END),
COUNT (CASE WHEN d.c2 IN ['Y'] THEN 1 ELSE NULL END)
...Appendix: Query Plan Fields
Consider the example:
CREATE INDEX idx_landmark_activity
ON landmark(activity);
EXPLAIN SELECT activity, COUNT(activity)
FROM landmark
WHERE activity IS NOT MISSING
GROUP BY activity;In the query plan:
-
plan.`~children`[0.covers]shows that the index covers the query. -
plan.`~children`[0.index_group_aggs]shows the aggregation and groupings done by the indexer. -
index_group_aggsobject has details on the aggregate, index key position, expression dependency, and group expressions handled by the indexer. This object is present in the plan only when the indexer handles the grouping and aggregation.
| Item Name | Description | Explain Text in This Example |
|---|---|---|
|
Array of Aggregate objects, and each object represents one aggregate function. The absence of this item means there is no Aggregate function. |
|
|
Aggregate operation. |
|
|
List of index key positions the GROUP BY expression depends on, starting with 0. |
(because it’s the 1st item) |
|
Group expression or an aggregate expression. |
|
|
Unique ID given internally and will be used in |
|
|
Key Position to use the Index expr or the query expr.
|
(because it matches the 1st index key) |
|
List of index key positions the GROUP BY expression depends on, starting with 0. |
(because it’s the 1st item) |
|
Array of GROUP BY objects, and each object represents one group key. The absence of this item means there is no GROUP BY clause. |
|
|
Index key position of a single GROUP BY expression |
(because it’s the 1st GROUP BY key) |
|
Single GROUP BY expression. |
|
|
Unique ID given internally and will be used in |
|
|
Key Position to use the Index expr or the query expr.
|
(because it matches the 1st key in the index expression) |
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan3",
"bucket": "travel-sample",
"covers": [
"cover ((`landmark`.`activity`))",
"cover ((meta(`landmark`).`id`))",
"cover (count(cover ((`landmark`.`activity`))))"
],
"index": "idx_landmark_activity",
"index_group_aggs": { (1)
"aggregates": [
{
"aggregate": "COUNT",
"depends": [
0
],
"expr": "cover ((`landmark`.`activity`))",
"id": 2,
"keypos": 0
}
],
"depends": [
0
],
"group": [
{
"depends": [
0
],
"expr": "cover ((`landmark`.`activity`))",
"id": 0,
"keypos": 0
}
]
},
"index_id": "ba98a2af8f4e0f4d",
"index_projection": {
"entry_keys": [
0,
2
]
},
"keyspace": "landmark",
"namespace": "default",
"scope": "inventory",
"spans": [
{
"exact": true,
"range": [
{
"inclusion": 1,
"low": "null"
}
]
}
],
"using": "gsi"
},
{
"#operator": "Parallel",
"~child": {
"#operator": "Sequence",
"~children": [
{
"#operator": "InitialProject",
"result_terms": [
{
"expr": "cover ((`landmark`.`activity`))"
},
{
"expr": "cover (count(cover ((`landmark`.`activity`))))"
}
]
}
]
}
}
]
},
"text": "SELECT activity, COUNT(activity)\nFROM landmark\nWHERE activity IS NOT MISSING\nGROUP BY activity;"
}| 1 | When the index_group_aggs section is present, it means that the query is using Index Aggregations. |
| Item Name | Description | EXPLAIN Text in Example 1 (GROUP BY) |
|---|---|---|
|
Array of Aggregate objects, and each object represents one aggregate function. The absence of this item means there is no Aggregate function. |
|
|
Aggregate operation. |
|
|
List of index key positions the GROUP BY expression depends on, starting with 0. |
(because it’s the 3rd item) |
|
Group expression or an aggregate expression. |
|
|
Unique ID given internally and will be used in |
|
|
Key Position to use the Index expr or the query expr.
|
(because the index has the field |
|
List of index key positions the GROUP BY expression depends on, starting with 0. |
|
|
Array of GROUP BY objects, and each object represents one group key. The absence of this item means there is no GROUP BY clause. |
|
|
Index key position of a single GROUP BY expression, starting with 0. |
(because it’s the 1st GROUP BY key) |
|
Single GROUP BY expression. |
|
|
Unique ID given internally and will be used in |
|
|
Key Position to use the Index expr or the query expr.
|
(because it matches the first key in the index expression) |
The Query Plan sections of an Aggregate pushdown are slightly different than those used in a GROUP BY.
| Item Name | Description | EXPLAIN Text in Example 15 (Aggregate) |
|---|---|---|
|
Array of Aggregate objects, and each object represents one aggregate function. The absence of this item means there is no Aggregate function. |
|
|
Aggregate operation. |
|
|
List of index key positions the GROUP BY expression depends on, starting with 0. |
(because it’s the 3rd item) |
|
Group expression or an aggregate expression. |
|
|
Unique ID given internally and will be used in |
|
|
Key Position to use the Index expr or the query expr.
|
(because the query’s 3rd key exactly matches the index’s 3rd key) |
|
List of index key positions the GROUP BY expression depends on, starting with 0. |
|
|
Array of GROUP BY objects, and each object represents one group key. The absence of this item means there is no GROUP BY clause. |
|
|
Index key position of a single GROUP BY expression, starting with 0. |
(because it’s the 1st GROUP BY key) |
|
Single GROUP BY expression. |
|
|
Unique ID given internally and will be used in |
|
|
Key Position to use the Index expr or the query expr.
|
(because it matches the 1st key in the index expression) |
|
Index key position of a single GROUP BY expression, starting with 0. |
(because it’s the 2nd GROUP BY key) |
|
Single GROUP BY expression. |
|
|
Unique ID given internally and will be used in |
|
|
Key Position to use the Index expr or the query expr.
|
(because it matches the 2nd key in the index expression) |