Adaptive Index
Adaptive Indexes are a special type of GSI array index that can index all or specified fields of a document. Such an index is generic in nature, and it can efficiently index and lookup any of the index-key values. This enables efficient ad hoc queries (that may have WHERE clause predicates on any of the index-key fields) without requiring to create various composite indexes for different combinations of fields. Adaptive Index is a functional array index created using the SQL++ function PAIRS().
Basically, the idea is to be able to simply load data and start querying:
-
using a single secondary index, and
-
not worrying about creating appropriate secondary indexes for each query.
Note that without Adaptive Indexes:
-
Only primary index can help run any ad hoc query. But using primary index can be expensive for queries with predicates on any of the non-key fields of the document.
-
Each query will need a compatible secondary index that can qualify for the predicates in the WHERE clause. See section Contrast with Composite Indexes for details.
For instance, consider a user profile or hotel reservation search use case. A person’s profile may need to be searched based on any of the personal attributes such as first name, last name, age, city, address, job, title, company, etc. Similarly, a hotel room availability may be searched based on wide criteria, such as room facilities, amenities, price, and other features. In this scenario, traditional secondary indexes or composite indexes can’t be used effectively — see section Contrast with Composite Indexes to understand some of the concerns. Adaptive indexes can help effectively and efficiently run such ad hoc search queries.
Syntax
An adaptive index is a type of array index. To create an adaptive index, the overall syntax is the same as for an array index.
Refer to the CREATE INDEX statement for details of the syntax.
Index Key
simple-array-expr ::= ( 'ALL' | 'DISTINCT' ) expr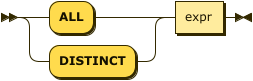
To create an adaptive index, the index key must be a simple array expression containing a PAIRS() function.
PAIRS() Function
pairs-function ::= 'PAIRS' '(' ( 'SELF' | index-key-object ) ')'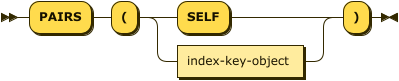
When the SELF keyword is used, the adaptive index is created with all fields in the documents of the keyspace.
If you want to create an adaptive index on selected fields only, you must specify an index key object.
Index Key Object
object ::= '{' ( ( name-expr ':' )? expr (',' ( name-expr ':' )? expr)* )? '}'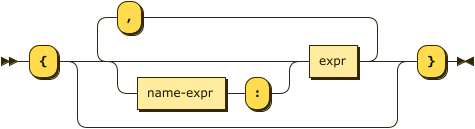
For the purposes of an adaptive index, the index key object should be an object constructor that generates an object of name-value pairs from the document fields to be indexed.
- name-expr
-
The field name that corresponds to
expr. - expr
-
A SQL++ expression that is allowed in CREATE INDEX. This must be an expression over any document fields.
When the value expression is an identifier directly referring to a named document field, then you may omit the name expression. In this case, the name of the field in the data source will be used as the name of the field in the object constructor.
|
When using PAIRS() with an object constructor, you need to keep in mind:
|
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Consider the following indexes, which are included with the travel-sample data that is shipped with the product.
To install sample data, see Sample Buckets.
CREATE INDEX `def_inventory_airport_airportname`
ON `travel-sample`.`inventory`.`airport`(`airportname`) WITH { "defer_build":true }CREATE INDEX `def_inventory_airport_city`
ON `travel-sample`.`inventory`.`airport`(`city`) WITH { "defer_build":true }CREATE INDEX `def_inventory_airport_faa`
ON `travel-sample`.`inventory`.`airport`(`faa`) WITH { "defer_build":true }Here, three different indexes are needed to help different queries whose WHERE clause predicates may refer to different fields. For instance, the following queries Q1, Q2, and Q3 will use the indexes created in C1, C2, and C3, respectively:
SELECT * FROM airport WHERE airportname LIKE "San Francisco%";SELECT * FROM airport WHERE city = "San Francisco";SELECT * FROM airport WHERE faa = "SFO";However, the following single adaptive index C4 can serve all three of the following queries Q1A, Q2A, and Q3A:
CREATE INDEX `ai_airport_day_faa`
ON airport(DISTINCT PAIRS({airportname, city, faa, type}));SELECT * FROM airport
USE INDEX (ai_airport_day_faa)
WHERE airportname LIKE "San Francisco%";SELECT * FROM airport
USE INDEX (ai_airport_day_faa)
WHERE city = "San Francisco";SELECT * FROM airport
USE INDEX (ai_airport_day_faa)
WHERE faa = "SFO";Similarly, the following adaptive index over SELF in C5 is also qualified for these queries.
In fact, an adaptive index that includes all fields in the documents can serve any query on the keyspace, though it might have different performance characteristics when compared to specific indexes created for a particular query.
See the section Performance Implications for details.
For example, the following queries Q5 and Q5A show how the generic adaptive index C5 is used to query predicates on different fields of the "airport" documents.
CREATE INDEX `ai_self`
ON airport(DISTINCT PAIRS(self));EXPLAIN SELECT * FROM airport
USE INDEX (ai_self)
WHERE faa = "SFO";[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "DistinctScan",
"scan": {
"#operator": "IndexScan3",
"bucket": "travel-sample",
"index": "ai_self",
"index_id": "1243095ed73061b5",
"index_projection": {
"primary_key": true
},
"keyspace": "airport",
"namespace": "default",
"scope": "inventory",
"spans": [
{
"exact": true,
"range": [
{
"high": "[\"faa\", \"SFO\"]",
"inclusion": 3,
"low": "[\"faa\", \"SFO\"]"
}
]
}
],
"using": "gsi"
}
// ...EXPLAIN SELECT *
FROM airport
USE INDEX (ai_self)
WHERE tz = "Europe/Paris";[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "DistinctScan",
"scan": {
"#operator": "IndexScan3",
"bucket": "travel-sample",
"index": "ai_self",
"index_id": "1243095ed73061b5",
"index_projection": {
"primary_key": true
},
"keyspace": "airport",
"namespace": "default",
"scope": "inventory",
"spans": [
{
"exact": true,
"range": [
{
"high": "[\"tz\", \"Europe/Paris\"]",
"inclusion": 3,
"low": "[\"tz\", \"Europe/Paris\"]"
}
]
}
],
"using": "gsi"
}
// ...Contrast with Composite Indexes
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Traditionally, composite secondary indexes are used to create indexes with multiple index keys. For example, consider the following index in C6:
CREATE INDEX `idx_city_faa_airport`
ON airport(city, faa, airportname);Such composite indexes are very different from the adaptive index in C4 in many ways:
-
Order of index keys is vital for composite indexes. When an index key is used in the WHERE clause, all prefixing index keys in the index definition must also be specified in the WHERE clause. For example, to use the index C6, a query to "find details of airports with FAA code SFO", must specify the prefixing index key
cityalso in the WHERE clause just to qualify the index C6. Contrast the following query Q6 with Q3 above that uses the adaptive index in C3.Q6SELECT * FROM airport WHERE faa = "SFO" AND city IS NOT MISSING;The problem is not just the addition of an extraneous predicate, but the performance. The predicate on the first index key
city IS NOT MISSINGis highly selective (i.e. most of the index entries in the index will match it) and hence, it will result in almost a full index scan. -
Complication in Queries. If a document has many fields to index, then the composite index will end up with all those fields as index keys. Subsequently, queries that only need to use index keys farther in the index key order will need many unnecessary predicates referring to all the preceding index keys. For example, if the index is:
CREATE INDEX idx_name ON `travel-sample`(field1, field2, ..., field9);A query that has a predicate on
field9will get unnecessarily complicated, as it needs to use all preceding index keys fromfield1tofield8. -
Explosion of number of indexes for ad hoc queries. At some point, it becomes highly unnatural and overly complicated to write ad hoc queries using composite indexes. For instance, consider a user profile or inventory search use case where a person or item may need to be searched based on many criteria.
One approach is to create indexes on all possible attributes. If that query can include any of the attributes, then it may require creation of innumerable indexes. For example, a modest 20 attributes will result in 20 factorial (2.43×1018) indexes in order to consider all combinations of sort orders of the 20 attributes.
Partial Adaptive Indexes
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
An adaptive index may also be a partial index. For a partial adaptive index, you must ensure that any fields filtered by the WHERE clause in the index definition are also referenced by the PAIRS() function.
CREATE INDEX ai_geo ON landmark
(DISTINCT PAIRS({geo.alt, geo.lat, geo.lon}))
WHERE activity = "see"; (1)| 1 | The WHERE clause filters on activity, but the PAIRS() function does not include the activity field. |
EXPLAIN SELECT META(t).id FROM landmark t
WHERE t.geo.alt > 1000 AND t.activity = "see";[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "PrimaryScan3",
"as": "t",
"bucket": "travel-sample",
"index": "def_inventory_landmark_primary", (1)
// ...| 1 | The query does not use the incorrectly-defined partial adaptive index. |
CREATE INDEX ai_geo_activity ON landmark
(DISTINCT PAIRS({geo.alt, geo.lat, geo.lon, activity}))
WHERE activity = "see"; (1)| 1 | The WHERE clause filters on activity, and the PAIRS() function includes the activity field. |
[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "IntersectScan",
"scans": [
{
"#operator": "DistinctScan",
"scan": {
"#operator": "IndexScan3",
"as": "t",
"bucket": "travel-sample",
"index": "ai_geo_activity", (1)
"index_id": "29640ebd837e32fb",
"index_projection": {
"primary_key": true
},
// ...| 1 | The query does an IntersectScan, including the correct partial adaptive index. |
Alternatively, you can use the SELF keyword to ensure that the fields used in the WHERE clause are included in the PAIRS() function.
Refer to C5 for an example.
An IntersectScan does not eliminate redundant queries, and this may impact performance. Refer to Performance Implications for details.
Performance Implications
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
While Adaptive Indexes are very useful, there are performance implications you need to keep in mind:
-
If a query is not covered by a regular index, then an unnested index will not have any elimination of redundant indexes; and it will instead do an IntersectScan on all the indexes, which can impact performance.
CREATE INDEX idx_name ON hotel(name); (1) CREATE INDEX idx_self ON hotel(DISTINCT PAIRS(self)); (2) EXPLAIN SELECT * FROM hotel WHERE name IS NOT NULL;1 Index on the namefield.2 Adaptive index on the whole document. Results[ { "plan": { "#operator": "Sequence", "~children": [ { "#operator": "IntersectScan", (1) "scans": [ { "#operator": "IndexScan3", "bucket": "travel-sample", "index": "idx_name", // ... }, { "#operator": "DistinctScan", "scan": { "#operator": "IndexScan3", "bucket": "travel-sample", "index": "idx_self", // ...1 IntersectScan of idx_nameANDidx_self.Here’s another example with a partial Adaptive Index that uses IntersectScan on the index conditions:
CREATE INDEX idx_adpt ON landmark(DISTINCT PAIRS(self)) WHERE city="Paris"; CREATE INDEX idx_reg1 ON landmark(name) WHERE city="Paris"; CREATE INDEX idx_reg2 ON landmark(city); SELECT * FROM landmark WHERE city="Paris" AND name IS NOT NULL;The above query requires only a regular index, so it uses index
idx_reg1and ignores indexidx_reg2. When the adaptive indexidx_adpthas only the clausecity="Paris"and is used with the above query, then indexidx_adptwill still use IntersectScan. Here, we have only a single adaptive index instead of a reduction in the number of indexes. To fix this, you may need to remove the index condition from the predicate while spanning generations.
Functional Limitations
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
It is important to understand that adaptive indexes are not a panacea and that they have trade-offs compared to traditional composite indexes:
-
Adaptive Indexes are bound to the limitations of Array Indexes because they are built over Array Indexing technology. Index Joins can’t use Adaptive Indexes because Index Joins can’t use array indexes, and Adaptive Index is basically an array index.
-
Indexed entries of the Adaptive Index are typically larger in size compared to the simple index on respective fields because the indexed items are elements of the PAIRS() array, which are basically name-value pairs of the document fields. So, it may be relatively slower when compared with equivalent simple index. For example, in the following equivalent queries, C8/Q8 may perform better than C9/Q9.
This example uses the
def_inventory_hotel_cityindex, which is installed with thetravel-samplebucket.C8CREATE INDEX `def_inventory_hotel_city` ON `travel-sample`.`inventory`.`hotel`(`city`) WITH { "defer_build":true };Q8EXPLAIN SELECT city FROM hotel USE INDEX (def_inventory_hotel_city) WHERE city = "San Francisco";Result{ "plan": { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "bucket": "travel-sample", "covers": [ "cover ((`hotel`.`city`))", "cover ((meta(`hotel`).`id`))" ], "filter": "(cover ((`hotel`.`city`)) = \"San Francisco\")", "index": "def_inventory_hotel_city", "index_id": "581febfa2f2a8923", "index_projection": { "entry_keys": [ 0 ] }, "keyspace": "hotel", "namespace": "default", "scope": "inventory", "spans": [ { "exact": true, "range": [ { "high": "\"San Francisco\"", "inclusion": 3, "low": "\"San Francisco\"" } ] } ], "using": "gsi" }, // ...C9CREATE INDEX `ai_city` ON hotel(DISTINCT PAIRS({city}));Q9EXPLAIN SELECT city FROM hotel USE INDEX (ai_city) WHERE city = "San Francisco";Result{ "plan": { "#operator": "Sequence", "~children": [ { "#operator": "DistinctScan", "scan": { "#operator": "IndexScan3", "bucket": "travel-sample", "index": "ai_city", "index_id": "64e238e4686486d2", "index_projection": { "primary_key": true }, "keyspace": "hotel", "namespace": "default", "scope": "inventory", "spans": [ { "exact": true, "range": [ { "high": "[\"city\", \"San Francisco\"]", "inclusion": 3, "low": "[\"city\", \"San Francisco\"]" (1) } ] } ], "using": "gsi" } }, // ...1 Note how the index key values are represented in the spans. -
Adaptive index requires more storage and memory, especially in case of Memory Optimized Indexes.
-
The size of the index and the number of indexed items in an Adaptive Index grow rapidly with the number of fields in the documents, as well as, with the number of different values for various fields in the documents or keyspace.
-
Moreover, if the documents have nested sub-objects, then the adaptive index will index the sub-documents and related fields at each level of nesting.
-
Similarly, if the documents have array fields, then each of array elements are explored and indexed.
-
For example, the following queries show that a single route document in
travel-samplegenerates 103 index items and that all route documents produce ~2.3 million items.SELECT array_length(PAIRS(self)) FROM route LIMIT 1;Result[ { "$1": 103 } ]SELECT sum(array_length(PAIRS(self))) FROM route LIMIT 1;Result[ { "$1": 2285464 } ]
So, the generic adaptive indexes (with
SELF) should be employed carefully. Whenever applicable, it is recommended to use the following techniques to minimize the size and scope of the adaptive index:-
Instead of
SELF, use selective adaptive indexes by specifying the field names of interest to the PAIRS() function. For examples, refer to C4, Q1, Q2, and Q3 above. -
Use partial adaptive indexes with a WHERE clause that will filter the number of documents that will be indexed. For examples, refer to C5, Q5, and Q5A above.
-
-
A generic adaptive index (on SELF) will be qualified for all queries on the keyspace. So, when using with other GSI indexes, this will result in more IntersectScan operations for queries that qualify other non-adaptive indexes. This may impact query performance and overall load on query and indexer nodes. To alleviate the negative effects, you may want to specify the
USE INDEXclause inSELECTqueries whenever possible. -
Adaptive Indexes cannot be used as Covered Indexes for any queries. See example Q9 above.
-
Adaptive Indexes can be created only on document field identifiers, not on functional expressions on the fields. For example, the following query uses a default index, such as
def_inventory_hotel_city, instead of the specified adaptive indexai_city1:CREATE INDEX `ai_city1` ON hotel(DISTINCT PAIRS({"city" : LOWER(city)}));EXPLAIN SELECT city FROM hotel USE INDEX (ai_city1) WHERE LOWER(city) = "san francisco";Result[ { "plan": { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "bucket": "travel-sample", "covers": [ "cover ((`hotel`.`city`))", "cover ((meta(`hotel`).`id`))" ], "filter": "(lower(cover ((`hotel`.`city`))) = \"san francisco\")", "index": "def_inventory_hotel_city", (1) "index_id": "581febfa2f2a8923", // ...1 The query does not use the specified ai_city1index because the index uses a functional index expression on the fieldcity. -
Adaptive Indexes do not work with NOT LIKE predicates with a leading wildcard (see MB-23981). For example, the following query also uses a default index, such as
def_city, instead of the specified adaptive indexai_city. However, it works fine for LIKE predicates with a leading wildcard.Query: NOT LIKE with leading wildcardEXPLAIN SELECT city FROM hotel USE INDEX (ai_city) WHERE city NOT LIKE "%Francisco";Result[ { "plan": { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "bucket": "travel-sample", "covers": [ "cover ((`hotel`.`city`))", "cover ((meta(`hotel`).`id`))" ], "filter": "(not (cover ((`hotel`.`city`)) like \"%Francisco\"))", "index": "def_inventory_hotel_city", (1) "index_id": "581febfa2f2a8923", // ...1 Doesn’t use ai_citywithNOT LIKEand leading wildcard.Query: LIKE with leading wildcardEXPLAIN SELECT city FROM hotel USE INDEX (ai_city) WHERE city LIKE "%Francisco";Result[ { "plan": { "#operator": "Sequence", "~children": [ { "#operator": "DistinctScan", "scan": { "#operator": "IndexScan3", "bucket": "travel-sample", "index": "ai_city", (1) "index_id": "64e238e4686486d2", // ...1 Uses ai_citywithLIKEand leading wildcard. -
Adaptive indexes can’t use Covered Scans. An adaptive index can’t be a covering index, as seen in the following example:
CREATE INDEX `ai_city2` ON hotel(DISTINCT PAIRS({"city" : city}));EXPLAIN SELECT city FROM hotel WHERE city = "San Francisco"; (1)1 No index specified in query. Result[ { "plan": { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "bucket": "travel-sample", "covers": [ "cover ((`hotel`.`city`))", "cover ((meta(`hotel`).`id`))" ], "filter": "(cover ((`hotel`.`city`)) = \"San Francisco\")", "index": "def_inventory_hotel_city", (1) "index_id": "581febfa2f2a8923", // ...1 Doesn’t use ai_city2as a covering index.