CREATE PRIMARY INDEX
- reference
The CREATE PRIMARY INDEX statement allows you to create a primary index.
Primary indexes contain a full set of keys in a given keyspace.
Primary indexes are optional — they enable you to run ad hoc queries on a keyspace that’s not supported by a secondary index.
Purpose
CREATE PRIMARY INDEX allows you to make multiple concurrent index creation requests.
The command starts a task to create the primary index definition in the background.
If there is an index creation task already running, the Index Service queues the incoming index creation request.
CREATE PRIMARY INDEX returns as soon as the index creation phase is complete.
By default, when the index creation phase is complete, the Index Service triggers the index build phase.
If you lose connectivity, the index build operation continues in the background.
You can defer the index build phase using the defer_build clause.
In deferred build mode, CREATE PRIMARY INDEX creates the index definition, but does not trigger the index build phase.
You can then build the index using the BUILD INDEX command.
You can create multiple identical primary indexes on a keyspace and place them on separate nodes for better index availability.
In Couchbase Server Enterprise Edition, the recommended way to do this is using the num_replicas option.
In Couchbase Server Community Edition, you need to create multiple identical indexes and place them using the nodes option.
See WITH Clause for more details.
Prerequisites
RBAC Privileges
To execute the CREATE PRIMARY INDEX statement, you must have the Query Manage Index privilege granted on the keyspace.
For more information about user roles, see
Authorization.
Syntax
create-primary-index ::= 'CREATE' 'PRIMARY' 'INDEX' ( index-name? ( 'IF' 'NOT' 'EXISTS' )? |
'IF' 'NOT' 'EXISTS' index-name )
'ON' keyspace-ref index-partition? index-using? index-with?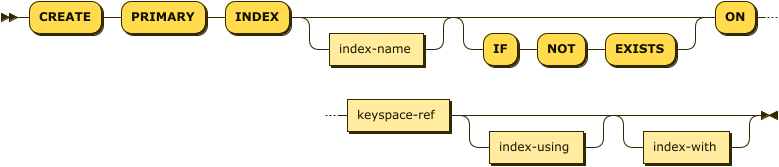
| index-name |
(Optional) A unique name that identifies the index.
If a name is not specified, the default name of Valid GSI index names can contain any of the following characters: |
| keyspace-ref |
[Required] Specifies the keyspace where the index is created. See Keyspace Reference. |
| index-partition |
(Optional) Specifies index partitions. See PARTITION BY HASH Clause. |
| index-using |
(Optional) Specifies the index type. See USING Clause. |
| index-with |
(Optional) Specifies options for the index. See WITH Clause. |
IF NOT EXISTS Clause
The optional IF NOT EXISTS clause enables the statement to complete successfully when the specified primary index already exists.
If a primary index with the same name already exists within the specified keyspace, then:
-
If this clause is not present, an error is generated.
-
If this clause is present, the statement does nothing and completes without error.
Keyspace Reference
keyspace-ref ::= keyspace-path | keyspace-partial
Specifies the keyspace for which the index needs to be created. The keyspace reference may be a keyspace path or a keyspace partial.
| If there is a hyphen (-) inside any part of the keyspace reference, you must wrap that part of the keyspace reference in backticks (` `). See the examples on this page. |
Keyspace Path
keyspace-path ::= ( namespace ':' )? bucket ( '.' scope '.' collection )?
If the keyspace is a named collection, or the default collection in the default scope within a bucket, the keyspace reference may be a keyspace path. In this case, the query context should not be set.
| namespace |
(Optional) An identifier that refers to the namespace of the keyspace.
Currently, only the |
| bucket |
(Required) An identifier that refers to the bucket name of the keyspace. |
| scope |
(Optional) An identifier that refers to the scope name of the keyspace. If omitted, the bucket’s default scope is used. |
| collection |
(Optional) An identifier that refers to the collection name of the keyspace. If omitted, the default collection in the bucket’s default scope is used. |
For example, default:`travel-sample` indicates the default collection in the default scope in the travel-sample bucket in the default namespace.
Similarly, default:`travel-sample`.inventory.airline indicates the airline collection in the inventory scope in the travel-sample bucket in the default namespace.
Keyspace Partial
keyspace-partial ::= collection
Alternatively, if the keyspace is a named collection, the keyspace reference may be just the collection name with no path. In this case, you must set the query context to indicate the required namespace, bucket, and scope.
| collection |
(Required) An identifier that refers to the collection name of the keyspace. |
For example, airline indicates the airline collection, assuming the query context is set.
PARTITION BY HASH Clause
Used to partition the index. Index partitioning helps increase the query performance by dividing and spreading a large index of documents across multiple nodes, horizontally scaling out an index as needed. For more information, see Index Partitioning.
USING Clause
index-using ::= 'USING' 'GSI'
The index type for a primary index must be Global Secondary Index (GSI).
The USING GSI keywords are optional and may be omitted.
WITH Clause
index-with ::= 'WITH' expr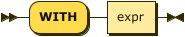
Use the WITH clause to specify additional options.
| expr |
An object with the following properties. |
| Name | Description | Schema |
|---|---|---|
nodes |
An array of strings, each of which represents a node name. In Couchbase Server Community Edition, a single primary index of type In Couchbase Server Enterprise Edition, you can specify multiple nodes to distribute replicas of an index across nodes running the indexing service: for example, If specifying both If A node name passed to the Example: |
String array |
defer_build |
Whether the index should be created in deferred build mode. When set to When set to Default: |
Boolean |
num_replica |
This property is only available in Couchbase Server Enterprise Edition. The number of replicas of the index to create. The indexer will automatically distribute these replicas amongst index nodes in the cluster for load-balancing and high availability purposes. The indexer will attempt to distribute the replicas based on the server groups in use in the cluster where possible. If the value of this property is not less than the number of index nodes in the cluster, then the index creation will fail. Default: |
Integer |
Partitioned indexes support further options. See Index Partitioning.
Usage
Monitoring Primary Indexes
Index metadata provides a state field.
You can query this state field and other index metadata using system:indexes.
The index state may be scheduled for creation, deferred, building, pending, online, offline, or abridged.
You can also monitor the index state using the Couchbase Web Console.
|
If you kick off multiple index creation operations concurrently, you may sometimes see transient errors similar to the following. If this error occurs, the Index Service tries to run the failed operation again in the background until it succeeds, up to a maximum of 1000 retries. If the Index Service still cannot create the index after the maximum number of retries, the index state is marked as |
Primary Scan Timeout
For a primary index scan on any keyspace size, the query engine guarantees that the client is not exposed to scan timeout if the indexer throws a scan timeout after it has returned a greater than zero sized subset of primary keys. To complete the scan, the query engine performs successive scans of the primary index until all the primary keys have been returned. It’s possible that the indexer may throw scan timeout without returning any primary keys, and in this event the query engine returns scan timeout to the client.
For example, if the indexer cannot find a snapshot that satisfies the consistency guarantee of the query within the timeout limit, it will timeout without returning any primary keys.
For secondary index scans, the query engine does not handle scan timeout, and returns index scan timeout error to the client. You can handle scan timeout on a secondary index by increasing the indexer timeout setting (see Query Settings) or preferably by defining and using a more selective index.
Examples
To try the examples in this section, you must set the query context as described in each example.
For this example, unset the query context. For more information, see Query Context.
Create a named primary index on the default collection in the default scope within the travel-sample bucket.
CREATE PRIMARY INDEX idx_default_primary ON `travel-sample` USING GSI;For this example, the path to the required keyspace is specified by the query, so you do not need to set the query context.
This example is similar to Example 1, but creates a named primary index on the airport collection.
CREATE PRIMARY INDEX idx_airport_primary ON `travel-sample`.inventory.airport USING GSI;For this example, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Create a named primary index using the defer_build option.
CREATE PRIMARY INDEX idx_hotel_primary
ON hotel
USING GSI
WITH {"defer_build":true};Query system:indexes for the status of the index.
SELECT * FROM system:indexes WHERE name="idx_hotel_primary";The output from system:indexes shows the idx_hotel_primary in the deferred state.
For this example, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Kick off the deferred build on the named primary index.
BUILD INDEX ON hotel(idx_hotel_primary) USING GSI;Query system:indexes for the status of the index.
SELECT * FROM system:indexes WHERE name="idx_hotel_primary";The output from system:indexes shows that the index has now been created.