Durability
Understanding Durability
Couchbase Server allows you to set durability requirements for writes to buckets. These requirements make sure that Couchbase Server updates data in memory, on disk, or both on multiple nodes before it decides the write succeeded. The more replicas of data that Couchbase Server writes, the greater the level of data durability.
After a write meets its durability requirements, Couchbase Server notifies the client of success. If the write cannot meet the durability requirements, Couchbase Server notifies the client that the write failed. In this case, the original data remains unchanged throughout the cluster.
Couchbase Server supports durability for up to two replicas. It does not support durability for buckets with three or more replicas.
Durability is essential for features like Transactions that require atomicity across multiple document mutations.
Either or both the client and the bucket can set durability requirements. When both specify durability, Couchbase Server enforces the greater of the two values.
You can set durability requirements for both Couchbase and Ephemeral buckets. However, Ephemeral buckets only allow durability settings that do not require persistence to disk.
Benefits and Costs
Durability lets you choose between regular and durable writes.
-
A regular write is asynchronous and does not provide durability guarantees. This type of write may be suitable for data where occasional loss is acceptable, such as a single sensor reading among thousands collected continuously.
-
A durable write is synchronous and provides durability guarantees. Use this type of write for data where the loss could have significant negative consequences, such as financial transactions.
Durable writes typically take longer to complete than regular writes because they require additional replication or persistence steps. When deciding whether to use durability, consider the trade-off between higher throughput with regular writes and stronger data protection with durable writes.
Majority
For a write to be durable, it must meet a majority requirement. The majority requirement depends on the number of replicas defined for the bucket.
The following table shows the majority requirement for each replica setting:
| Number of Replicas | Number of Nodes Required for Majority |
|---|---|
0 |
1 |
1 |
2 |
2 |
2 |
3 or more |
Not supported |
|
As shown by the table, if you configure a bucket with one replica and a node fails, you cannot perform a durable write to any vBucket that has data on the failed node. |
Durability Requirements
When enabling durability, you set two parameters:
- Level
-
This setting controls what Couchbase Server considers a successful durable write. The valid settings are:
-
majority: A majority of Data Service nodes must store the mutation to memory for the write to be durable. You can use this level with both Couchbase and Ephemeral buckets. -
majorityAndPersistActive: A majority of Data Service nodes must store the mutation in-memory. Also, the node that hosts the active vBucket must write and synchronize the mutation to disk. You can choose this level only for Couchbase buckets. -
persistToMajority: A majority of Data Service nodes must save and synchronize the mutation to disk. You can choose this level only for Couchbase buckets.
-
- Timeout
-
Set the number of milliseconds Couchbase Server allows for a write to meet durability requirements. By default, the SDK sets the default to 10,000 milliseconds (10 seconds).
Specifying Levels
You can set durability levels for a client connection, a bucket, or both. If both a client connection and a bucket have a durability level setting, Couchbase Server enforces the highest level.
Process and Communication
Durable writes are atomic. If you read a value that’s undergoing a durable write, Couchbase Server returns the value that existed before the durable write. If you try to write to a key that’s undergoing a durable write, Couchbase Server returns an error message. You can retry the operation after receiving this error.
The following diagram shows the lifecycle of a durable write. It illustrates multiple clients attempting to update and read a value.
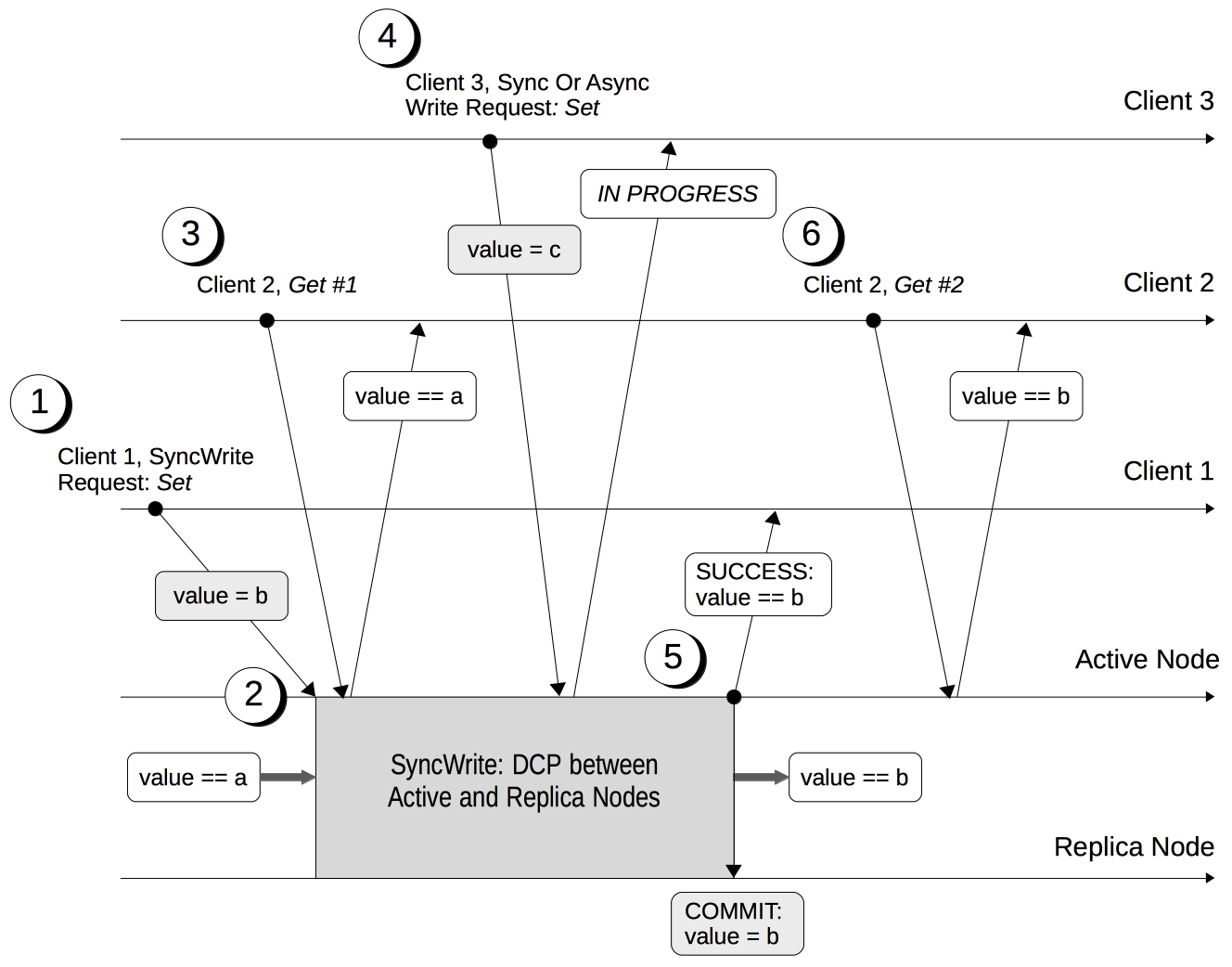
The key points in the write sequence are:
-
Client 1 sets durability requirements for a durable write to change a key’s value from
atob. -
The Active Node (the node that Client 1 is connected to) receives the request and starts the durable write process. Couchbase Server tries to meet the durability requirements Client 1 specified.
-
During the durable write process, Client 2 reads the value that’s undergoing the durable write. Couchbase Server returns the previous value,
a. -
During the durable write process, Client 3 tries to perform either a durable write or a regular write on the value that’s already undergoing a durable write. Couchbase Server returns a
SYNC_WRITE_IN_PROGRESSmessage telling Client 3 that its write attempt cannot occur. -
When the mutation meets the durability requirements, the Active Node commits the durable write and sends a
SUCCESSstatus response to Client 1. -
After the durable write process, Client 2 reads the value again. Couchbase Server returns the new value,
b, committed by the durable write. From this point, all clients see the valueb.
If Couchbase Server stops a durable write, it rolls back all mutations to active and replica vBuckets in memory and on disk. All copies of the data revert to their previous value. Couchbase Server informs the client of the rollback. See Durable Write Failure Scenarios.
In some cases, instead of confirming that the durable write succeeded, Couchbase Server reports an ambiguous outcome. This can happen if the client-specified timeout elapses. See Handling Ambiguous Results.
After Couchbase Server commits a durable write and acknowledges it, the server continues to replicate and persist the data. This process continues until Couchbase Server has updated the active and replica vBuckets both in-memory and on disk on all servers.
Regular Writes
A regular write occurs when neither the client nor the bucket require durability. Couchbase Server acknowledges a successful write as soon as it stores the data in the memory of the node that hosts the active vBucket. Couchbase Server does not confirm that it has propagated the write to any replica. A regular write does not guarantee durability. However, it’s faster than a durable write because it does not require the overhead of replication or persistence. Regular writes are asynchronous. If a node fails after a regular write, the data could be lost.
Durable Write Failure Scenarios
A durable write can fail for the following reasons:
- The durable write timeout elapses
-
If a timeout occurs, the active node aborts the durable write. It also instructs all replica nodes to stop the pending write. Then it notifies the client that the durable write had an ambiguous result. See Handling Ambiguous Results.
- A replica node fails during a pending Synchronous Write (SyncWrite) and before the active node can identify if it hosted a replica
-
If enough alternative replica nodes exist, the durable write can proceed. Otherwise, the active node waits until the server-side timeout expires, then aborts the durable write and informs you that the result was ambiguous.
- The active node fails while a SyncWrite is pending
-
This disconnects your client, so you must assume the result of the durable write is ambiguous. If the active node fails over, Couchbase Server promotes a replica from a replica node. Depending on how advanced the durable write was at the time of failure, the durable write may proceed.
- A client tries to write while SyncWrite is pending
-
If a client attempts a durable or regular write on a key that’s undergoing a durable write, Couchbase Server returns a
SYNC_WRITE_IN_PROGRESSmessage to indicate that the new write cannot proceed. The client can retry the write operation. - During a rebalance, Couchbase Server moves the active vBucket to a different node
-
If a durable write is taking place on the active vBucket as Couchbase Server moves it to a new node, it reports the write as ambiguous. See Durable Writes During Rebalance for more information.
Handling Ambiguous Results
Couchbase Server informs the client of an ambiguous result whenever it cannot confirm that a durable write was successful. A node or network failure or a timeout can cause this issue.
If a client receives an ambiguous result notification, it can choose to retry the durable write. It should only retry if the durable write is idempotent (can be performed multiple times without changing the initial result). If the attempted durable write is not idempotent, the client has the following options:
-
Verify the current state of the saved data. If the saved values are not what it attempted to write, then the client can choose to retry the durable write.
-
Return an error to the user.
Durable Writes During Rebalance
The rebalance process moves active and replica vBuckets between nodes to maintain optimal data availability. During rebalance, clients can read and mutate data without interruption. Durable writes also continue without interruption during the rebalance process.
In rare circumstances, a durable write can return an ambiguous result during rebalance. This can happen if Couchbase Server moves an active vBucket to a new node while a durable write is taking place to that vBucket. If this happens, Couchbase Server returns an ambiguous result to the client. See Handling Ambiguous Results for possible steps your application can take in this case.
Performance
You can optimize the performance of durable writes by allocating enough writer threads. For more information, see Threading for concepts and Data Settings for configuration steps.
Protection Guarantees
After Couchbase Server commits the durable write, it notifies clients that the write succeeded. From the point of commitment until the new data has fully propagated throughout the cluster, Couchbase Server guarantees protection from data loss within some constraints. These constraints depend on the durability level you set, the type of outage, and the number of replicas. You can find the guarantees and related constraints in the following sections.
Replica-Count Restriction
Couchbase Server supports durability for buckets with up to two replicas.
You cannot use durability with buckets that have three replicas.
If you try to perform a durable write on a bucket with three replicas, Couchbase Server returns an EDurabilityImpossible error.
Protection Guarantees and Failover
Failover removes a node from the cluster. You can manually failover a node through either a graceful failover (when the node is responsive) or a hard failover (when the node is unresponsive). See Failover for more information about these types of failovers.
You can also configure Couchbase Server to perform automatic failovers to remove a node that has been unresponsive longer than a configurable timeout period. You can limit the number of sequential automatic failovers that Couchbase Server allows before requiring administrator intervention.
When a node fails, Couchbase Server promotes replica vBuckets on surviving nodes to replace the lost active vBuckets.
Both manual and automatic failovers can cause the loss of durably written data. If all of the majority nodes are failed over either manually or automatically before the data can propagate to other nodes beyond the majority, the durably written data can be lost. This loss happens because there are not enough up to date replica vBuckets in the cluster.
For example, suppose you configure a bucket with two replicas. The data resides on three nodes and the majority for persistence is two nodes. If the two nodes making up the majority for a durable write are failed over either automatically or manually after the write commits, the durable write can be lost. The failover can happen before the durable write has been replicated to the third node. In this case, Couchbase Server loses the durable write, and the application receives a false success message.
When performing manual failovers, you should be aware of the chance of losing durably written data. When possible, avoid manually failing over more data nodes at the same time than are required for the durable write’s majority.
For automatic failovers in Couchbase Server Enterprise Edition, you have ways to limit the possibility of failovers causing the loss of durably written data:
-
You can set the maximum number of sequential automatic failovers (
maxCount) to be less than the majority needed to write data durably. -
You can configure auto-failover to prevent it from causing the loss of durably written data.
The following sections explain these two options.
In Couchbase Server Community Edition, you cannot configure either of these settings.
The maxCount setting is always 1, and the setting to preserve durable writes is not available.
|
Limiting Sequential Automatic Failovers
The number of sequential automatic failovers Couchbase Server allows is controlled by the maxCount setting.
See maxCount in Enabling and Disabling Auto-Failover for more information about this setting.
To prevent auto-failovers jeopardizing durable writes, set maxCount to less than the majority needed to write data durably.
In the previous example, you would set the maximum number of sequential automatic failovers to 1 (the default value) to prevent both majority nodes from failing over automatically.
- Benefits
-
This setting prevents all of the majority nodes that contain the newly written durable data from failing over automatically. It’s less restrictive than the setting to preserve durable writes because it does not block failover in cases where a node could possibly be involved in a durable write. Therefore, can allow Couchbase Server to perform failovers in cases where the auto-failover preserve durable writes setting does not. This option may be better for you if you value node availability as highly as you do data durability.
- Drawbacks
-
Changing
maxCountaffects all nodes in the cluster, including nodes that do not run the Data Service. This setting can prevent automatic failover of non-data nodes such as index nodes where durability is not an issue.
Auto-failover’s Preserve Durable Writes Setting
In Couchbase Server Enterprise Edition, you can configure auto-failover to prevent it from causing the loss of durably written data.
This is a global setting that affects all buckets, regardless of their durability settings.
When you enable this setting, Couchbase Server limits the automatic failover of nodes running the Data Service to one less than the number required for a durable write’s majority.
It does not affect the automatic failover of nodes that do not run the Data Service.
It also does not allow more nodes to automatically failover than the maxCount setting allows.
This setting’s effect depends on the number of replicas the bucket has:
-
If you configure a bucket with one replica and run the Data Service on two nodes, only one node (either the active or the replica) can be a candidate for auto-failover.
-
If you configure a bucket with two replicas and run the Data Service on three nodes, only one node (either the active or one of the replicas) can be a candidate for auto-failover. Two nodes cannot auto-failover because data may exist only on the required majority, which is two nodes. Couchbase Server must protect one of these nodes from auto-failover.
-
If you configure a bucket with three replicas and run the Data Service on four nodes, only two nodes (either the active and a replica, or two replicas) can be candidates for auto-failover. Couchbase Server applies this constraint even though durability is not supported for buckets with three replicas.
You enable this setting in the Couchbase Server Web Console’s Node Availability settings.
You can also enable it using the REST API.
See failoverPreserveDurabilityMajority in Enabling and Disabling Auto-Failover for more information.
- Benefits
-
Enabling the preserve durable writes setting is easier than setting the maximum number of sequential automatic failovers. This setting is more targeted because it applies to just the nodes running the Data Service. This means Couchbase Server could allow automatic failover of multiple non-data nodes which would not threaten durability, such as index nodes. In most cases, this is the best option to protect durably written data.
- Drawbacks
-
This setting is more restrictive, and can prevent automatic failover in some cases where adjusting the
maxCountsetting would allow it.
Protection Guarantees: One Replica
When you configure one replica, Couchbase Server provides the following protection guarantees from the point of commitment until the new data fully propagates across the cluster:
Level |
Failure(s) |
Description |
|
The active node fails and Couchbase Server automatically fails it over. |
The active node loses the data from memory, but it remains in the memory of the replica node. Couchbase Server promotes the replica vBucket to active status on the replica node, so the new data stays available. |
|
The active node fails and Couchbase Server automatically fails it over. |
The active node loses the new data from the memory and disk, but it remains in the memory of the replica node. Couchbase Server promotes the replica vBucket to active status on the replica node, so the new data stays available. |
The active node fails but restarts before auto-failover occurs. |
The new data disappears from the memory of the active node, but remains on the disk of the active node. Couchbase Server recovers the new data when the active node restarts. |
|
|
The active node fails and Couchbase Server automatically fails it over. |
The active node loses the new data from memory and disk, but it remains in the memory and disk of the replica node. Couchbase Server promotes the replica vBucket to active status on the replica node, so the new data stays available. |
The active node fails but restarts before auto-failover occurs. |
The new data disappears from the memory of the active node, but remains on the disk of the active node. Couchbase Server recovers the new data when the active node restarts. |
|
The active node fails and Couchbase Server automatically fails it over. Then, the promoted replica node fails and then restarts. |
The new data disappears from the memory and disk of the active node, but remains in the memory and on the disk of the replica node. Couchbase Server promotes the replica to active status. If the promoted replica node fails, the new data becomes temporarily unavailable. When the promoted replica node restarts, the new data becomes available again on disk. |
Protection Guarantees: Two Replicas
The durability protection guarantees for two replicas match those for one replica. The majority is 2 for both cases. See the table in Majority.
If you configure two replicas, set the maximum number of sequential automatic failovers to 1 without administrator intervention. This setting makes sure auto-failover does not conflict with the durable write’s guaranteed protection.
Maintaining Durable Writes During Replica Failovers
As described in Majority, a bucket must meet a majority requirement for a durable write to succeed. For example, suppose a bucket has a single replica. Then two nodes must acknowledge writing the data to either memory or disk (depending on the durability level) before Couchbase Server considers the write successful. If one node fails over, durable writes fail until the failed node rejoins the cluster.
In some cases, this restriction can be inconvenient. For example, suppose you want to perform an upgrade using the graceful failover followed by a delta recovery method in a three-node cluster. If you have a bucket with a single replica, performing the graceful failover causes durable writes to fail. This is because some vBuckets only have a single copy available in the cluster during the failover, so the write cannot achieve majority.
In these cases, you can have Couchbase Server report that durable writes succeeded even if the majority of nodes are unavailable.
To enable this behavior, set the durabilityImpossibleFallback setting for the bucket to true.
This setting has Couchbase Server report a success for a durable write, even if the majority of nodes are unavailable.
|
Potential Data Loss
Enabling Use this setting only in special cases such as when you’re performing a graceful failover and you still want durable writes to succeed. Always turn off this setting as soon as possible. |
When you enable durabilityImpossibleFallback, Couchbase Server reports a success for durable writes even if the majority of nodes are unavailable.
The following table shows the effects of the setting on durable writes in a three-node cluster for a bucket with a single replica.
| Situation | durabilityImpossibleFallback Disabled |
durabilityImpossibleFallback Enabled |
|---|---|---|
All nodes available |
Durable writes succeed |
Durable writes succeed |
One node fails over |
Durable writes fail due to lack of majority |
Couchbase Server reports the durable write succeeded without replication |
Two nodes fail over |
Durable writes fail |
Durable writes fail to vBuckets on failed-over nodes |
You can only change the durabilityImpossibleFallback setting using a REST API call.
See durabilityImpossibleFallback for details.