Index Service
The Index Service supports the creation of primary and secondary indexes on items stored within the Data Service.
Index Service Architecture
Components essential for the Index Service reside not only on each node to which the Index Service is assigned, but also on each node to which the Data Service is assigned, as shown by the following illustration:
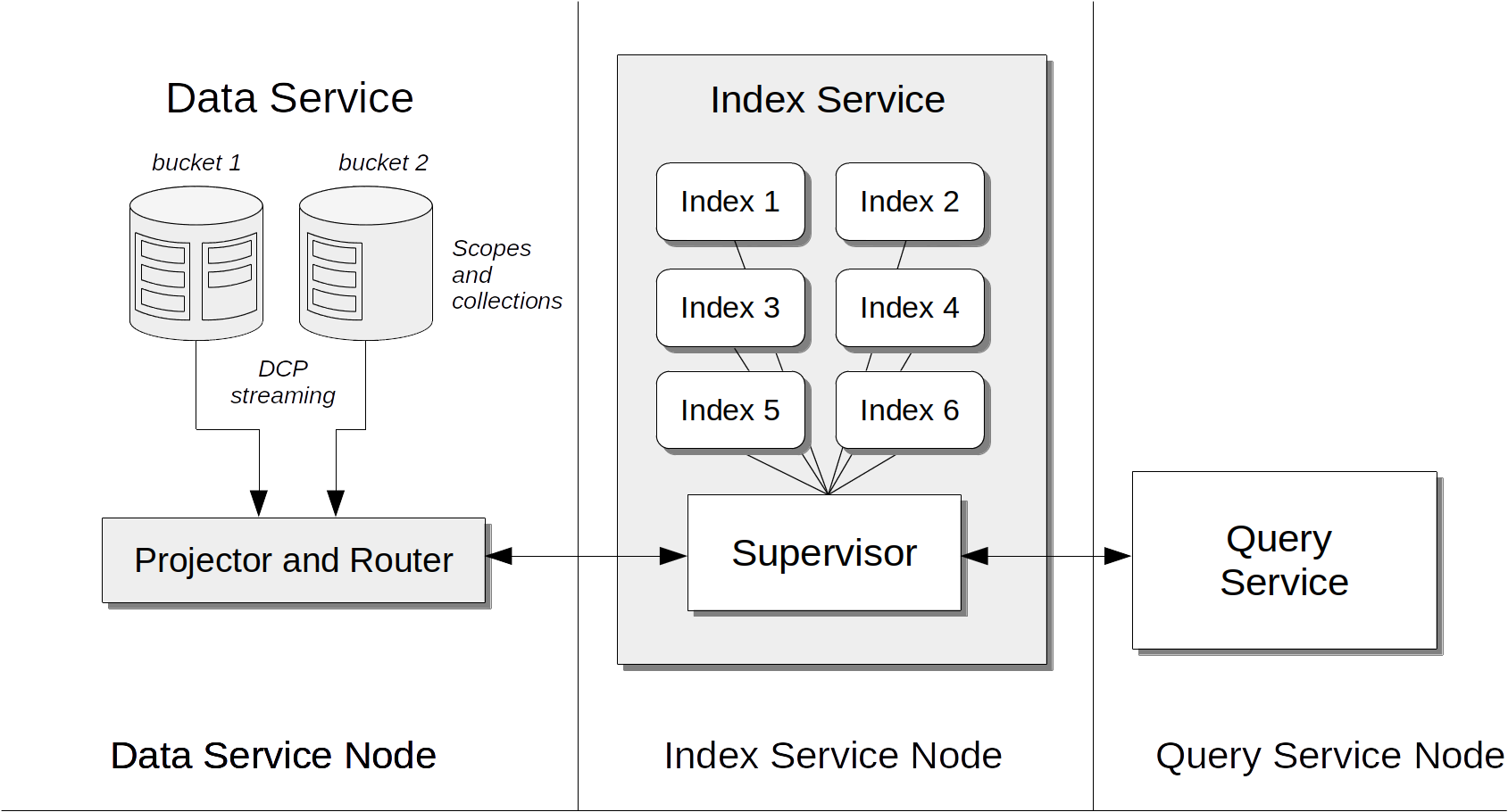
The illustration depicts the following:
-
Data Service: Uses the DCP protocol to stream data-mutations to the Projector and Router process, which runs as part of the Index Service, on each Data Service node.
-
Projector and Router: Provides data to the Index Service, according to the index-definitions provided by the Index Service Supervisor.
When the Projector and Router starts running on the Data Service-node, the Data Service streams to the Projector and Router copies of all mutations that occur to documents. Prior to the creation of any indexes, the Projector and Router takes no action.
When an index is first created, the Index Service Supervisor contacts the Projector and Router; and passes to it the corresponding index-definitions. The Projector and Router duly contacts the Data Service, and extracts data from the fields specified by the index-definitions. It then sends the data to the Supervisor, so that the index can be populated.
Subsequently, the Projector and Router continuously examines the stream of mutations provided by the Data Service. When this includes a mutation to an indexed field, the mutated data is passed by the Projector and Router to the Supervisor, and the index thereby updated.
-
Supervisor: The main program of the Index Service; which passes index-definitions to the Projector and Router, creates and stores indexes, and handles mutations sent from the Projector and Router.
-
Query Service: Passes to the Supervisor clients' create-requests and queries, and handles the responses.
Saving Indexes
By default, an index is saved on the node on which it is created. Each index is created on one keyspace (collection) only; but multiple indexes may be created on a single keyspace (collection).
The Index Service can be configured to use either standard or memory-optimized storage:
- Standard
-
The supervisor process persists to disk all changes made to individual indexes.
-
In Couchbase Server Community Edition, writes can either be append-only or write with circular reuse, depending on the write mode selected for global secondary indexes. Each index gets a dedicated file.
-
In Couchbase Server Enterprise Edition, compaction is handled automatically. As of Couchbase Server 7.0, multiple indexes are stored in a given file.
-
- Memory-Optimized
-
Only available in Couchbase Server Enterprise Edition. Indexes are saved in-memory. This provides increased efficiency for maintenance, scanning, and mutation. A snapshot of the index is maintained on disk, to permit rapid recovery if node-failures are experienced. A skiplist (rather than a conventional B-tree) structure is used; optimizing memory consumption. Lock-free index-processing enhances concurrency.
For more information, see Index Storage Settings.
Primary and Global Secondary Indexes
Primary Indexes are based on the unique key of every item in a specified collection. A primary index is intended to be used for simple queries, which have no filters or predicates.
Secondary Indexes, often referred to as Global Secondary Indexes or GSIs, constitute the principal means of indexing documents to be accessed by the Query Service. Secondary Indexes can be created on specified fields; placed on specific cluster-nodes; and replicated.
For information on using the Indexing Service, see Primary and Secondary Index Reference.
See Also
-
For more information about adding or removing the Index Service on an existing node of a cluster, see Modify Services and Rebalance.