View Concepts
Views allow you to extract specific fields and information from data and create an index.
A view performs the following on the Couchbase unstructured (or semi-structured) data:
-
Extract specific fields and information from the data files.
-
Produce a view index of the selected information.
By using JSON, the process of selecting individual fields for output is easier. The resulting generated structure is a view on the stored data. The view that is created during this process lets you iterate, select and query the information in your database from the raw data objects.
The view definition specifies the format and content of the information generated for each document. Because the process relies on the JSON fields, if the document is not JSON or the requested field in the view does not exist, the information is ignored. This enables the view to be created, even if some documents have minor errors or lack the relevant fields altogether.
One of the benefits of a document database is the ability to change the format of documents stored in the database at any time, without requiring a wholesale change to applications or a costly schema update before doing so.
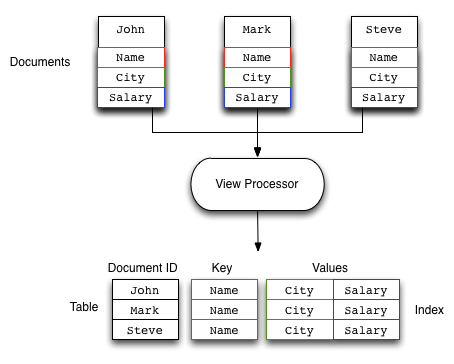
In the following example, the view takes the Name, City and Salary fields from the documents and creates an array of this information for each document in the view. A view is created by iterating over every single document within the Couchbase bucket and outputting the specified information. The resulting view file is stored for future use and updated with new data when the view is accessed. The process is incremental and therefore has a low ongoing impact on performance. Creating a new view on an existing large data set may take a long time to build but updates to the data are quick.
The following diagram shows a brief overview of this process: