Search Response
Full Text Search provides a response object, which contains detailed information on the results of the search. Prior to the search, a facet can be add to the response object, and information on aggregations thereby returned.
Response-Object Structure
A Full Text Search Response Object is itself composed of multiple child-objects, each of which provides important information. Each child-object is listed and explained below.
Pagination
The number of results obtained for a Full Text Search request can be large. Pagination of these results becomes essential for sorting and displaying a subset of these results.
There are multiple ways to achieve pagination with settings within a search request. Pagination will fetch a deterministic set of results when the results are sorted in a certain fashion.
Pagination provides the following options:
Size/from or offset/limit
This pagination settings can be used to obtain a subset of results and works deterministically when combined with a certain sort order.
Using size/limit and offset/from would fetch at least size + from ordered results from a partition and then return the size number of results starting at offset from.
Deep pagination can therefore get pretty expensive when using size + from on a sharded index due to each shard having to possibly return large resultsets (at least size + from) over the network for merging at the coordinating node before returning the size number of results starting at offset from.
The default sort order is based on score (relevance) where the results are ordered from the highest to the lowest score.
search_after, search_before
For an efficient pagination, you can use the search_after/search_before settings.
search_after is designed to fetch the size number of results after the key specified and search_before is designed to fetch the size number of results before the key specified.
These settings allow for the client to maintain state while paginating - the sort key of the last result (for search_after) or the first result (for search_before) in the current page.
Both the attributes accept an array of strings (sort keys) - the length of this array will need to be the same length of the "sort" array within the search request.
You cannot use both search_after and search_before in the same search request.
|
Example
Here are some examples using search_after/search_before over sort key "_id" (an internal field that carries the document ID).
{
"query": {
"match": "California",
"field": "state"
},
"sort": ["_id"],
"search_after": ["hotel_10180"],
"size": 3
}{
"query": {
"match": "California",
"field": "state"
},
"sort": ["_id"],
"search_before": ["hotel_17595"],
"size": 4
}
A Full Text Search request that doesn’t carry any pagination settings will return the first 10 results ("size: 10", "from": 0) ordered by score sequentially from the highest to lowest.
|
Pagination tips and recommendations
The pagination of search results can be done using the 'from' and 'size' parameters in the search request. But as the search gets into deeper pages, it starts consuming more resources.
To safeguard against any arbitrary higher memory requirements, FTS provides a configurable limit bleveMaxResultWindow (10000 default) on the maximum allowable page offsets. However, bumping this limit to higher levels is not a scalable solution.
To circumvent this problem, the concept of key set pagination in FTS, is introduced.
Instead of providing from as a number of search results to skip, the user will provide the sort value of a previously seen search result (usually, the last result shown on the current page). The idea is that to show the next page of the results, we just want the top N results of that sort after the last result from the previous page.
This solution requires a few preconditions be met:
-
The search request must specify a sort order.
| The sort order must impose a total order on the results. Without this, any results which share the same sort value might be left out when handling the page navigation boundaries. |
A common solution to this is to always include the document ID as the final sort criteria.
For example, if you want to sort by [“name”, “-age”], instead of sort by [“name”, “-age”, "_id”].
With search_after/search_before paginations, the heap memory requirement of deeper page searches is made proportional to the requested page size alone. So it reduces the heap memory requirement of deeper page searches significantly down from the offset+from values.
Fields
You can search multi-Collection indexes using the same old search requests. Since a multi-Collection index contains data from multiple source Collections, it’s useful to know the source Collection of their relevant hits.
With multi-Collection indexes, each hit in the search results contains information about the Collection to which it belongs. This source Collection detail is available in the Fields section of each hit under the key _$c. See the image below for an example.

multi-Collection index search results in Couchbase 7.0
You can also narrow your full-text search requests to only specific Collection(s) within the multi-Collection index. This focus speeds up your searches on a large index.
Sorting Query Results
The FTS results are returned as objects. FTS query includes options to order the results.
Sorting Result Data
FTS sorting is sorted by descending order of relevance. It can, however, be customized to sort by different fields, depending on the application.
On query-completion, sorting allows specified members of the result-set to be displayed prior to others: this facilitates a review of the most significant data.
Within a JSON query object, the required sort-type is specified by using the sort field.
This takes an array of either strings, objects, or numeric as its value.
Sorting with Strings
You can specify the value of the sort field as an array of strings.
These can be of three types:
-
field name: Specifies the name of a field.
If multiple fields are included in the array, the sorting of documents begins according to their values for the field whose name is first in the array.
If any number of these values are identical, their documents are sorted again, this time according to their values for the field whose name is second; then, if any number of these values are identical, their documents are sorted a third time, this time according to their values for the field whose name is third; and so on.
Any document-field may be specified to hold the value on which sorting is to be based, provided that the field has been indexed in some way, whether dynamically or specifically.
The default sort-order is ascending. If a field-name is prefixed with the
-character, that field’s results are sorted in descending order. -
_id: Refers to the document identifier. Whenever encountered in the array, causes sorting to occur by document identifer. -
_score: Refers to the score assigned the document in the result-set. Whenever encountered in the array, causes sorting to occur by score.
Example
"sort": ["country", "state", "city","-_score"]
This sort statement specifies that results will first be sorted by country.
If some documents are then found to have the same value in their country fields, they are re-sorted by state.
Next, if some of these documents are found to have the same value in their state fields, they are re-sorted by city.
Finally, if some of these documents are found to have the same value in their city fields, they are re-sorted by score, in descending order.
The following JSON query demonstrates how and where the sort property can be specified:
{
"explain": false,
"fields": [
"title"
],
"highlight": {},
"sort": ["country", "-_score","-_id"],
"query":{
"query": "beautiful pool"
}
}The following example shows how the sort field accepts combinations of strings and objects as its value.
{
...
"sort": [
"country",
{
"by" : "field",
"field" : "reviews.ratings.Overall",
"mode" : "max",
"missing" : "last",
"type": "number"
},
{
"by" : "field",
"field" : "reviews.ratings.Location",
"mode" : "max",
"missing" : "last",
"type": "number"
},
"-_score"
]
}Sorting with Objects
Fine-grained control over sort-procedure can be achieved by specifying objects as array-values in the sort field.
Each object can have the following fields:
-
by: Sorts results onid,score, or a specifiedfieldin the Full Text Index. -
field: Specifies the name of a field on which to sort. Used only iffieldhas been specified as the value for thebyfield; otherwise ignored. -
missing: Specifies the sort-procedure for documents with a missing value in a field specified for sorting. The value ofmissingcan befirst, in which case results with missing values appear before other results; orlast(the default), in which case they appear after. -
mode: Specifies the search-order for index-fields that contain multiple values (in consequence of arrays or multi-token analyzer-output). Thedefaultorder is undefined but deterministic, allowing the paging of results fromfrom (offset), with reliable ordering. To sort using the minimum or maximum value, the value ofmodeshould be set to eitherminormax. -
type: Specifies the type of the search-order field value. For example,stringfor text fields,datefor DateTime fields, ornumberfor numeric/geo fields.
To fetch more accurate sort results, we strongly recommend specifying the type of the sort fields in the sort section of the search request.
Example
The example below shows how to specify the object-sort.
{
"explain": false,
"fields": [
"*"
],
"highlight": {},
"query": {
"match": "bathrobes",
"field": "reviews.content",
"analyzer": "standard"
},
"size" : 10,
"sort": [
{
"by" : "field",
"field" : "reviews.ratings.Overall",
"mode" : "max",
"missing" : "last",
"type": "number"
}
]
}
The above sample assumes that the travel-sample bucket has been loaded, and a default index has been created on it.
|
For information on loading sample buckets, see Sample Buckets. For instructions on creating a default Full Text Index by means of the Couchbase Web Console, see Creating Index from UI.
This query sorts search-results based on reviews.ratings.Overall — a field that is normally multi-valued because it contains an array of different users' ratings.
When there are multiple values, the highest Overall ratings are used for sorting.
Hotels with no Overall rating are placed at the end.
The following example shows how the sort field accepts combinations of strings and objects as its value.
{
"sort": [
"country",
{
"by" : "field",
"field" : "reviews.ratings.Overall",
"mode" : "max",
"missing" : "last",
"type": "number"
},
{
"by" : "field",
"field" : "reviews.ratings.Location",
"mode" : "max",
"missing" : "last",
"type": "number"
},
"-_score"
]
}Sorting with Numeric
You can specify the value of the sort field as a numeric type. You can use the type field in the object that you specify with the sort.
With type field, you can specify the type of the search order to numeric, string, or DateTime.
Example
The example below shows how to specify the object-sort with type field as number.
{
"explain": false,
"fields": [
"*"
],
"highlight": {},
"query": {
"match": "bathrobes",
"field": "reviews.content",
"analyzer": "standard"
},
"size" : 10,
"sort": [
{
"by" : "field",
"field" : "reviews.ratings.Overall",
"mode" : "max",
"missing" : "last",
"type": "number"
}
]
}Tips for Sorting with fields
When you sort results on a field that is not indexed, or when a particular document is missing a value for that field, you will see the following series of Unicode non-printable characters appear in the sort field:
\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd
The same characters may render differently when using a graphic tool or command line tools like jq.
"sort": [
"����������",
"hotel_9723",
"_score"
]Check your index definition to confirm that you are indexing all the fields you intend to sort by. You can control the sort behavior for missing attributes using the missing field.
Scoring
Search result scoring occurs at a query time. The result of the search request is ordered by score (relevance), with the descending sort order unless explicitly set not to do so.
Couchbase uses a slightly modified version of the standard tf-idf algorithm. This deviation is to normalize the score and is based on tf-idf algorithm.
For more details on tf-idf, refer tf-idf
By selecting the explain score option within the search request, you can obtain the explanation of how the score was calculated for a result alongside it.
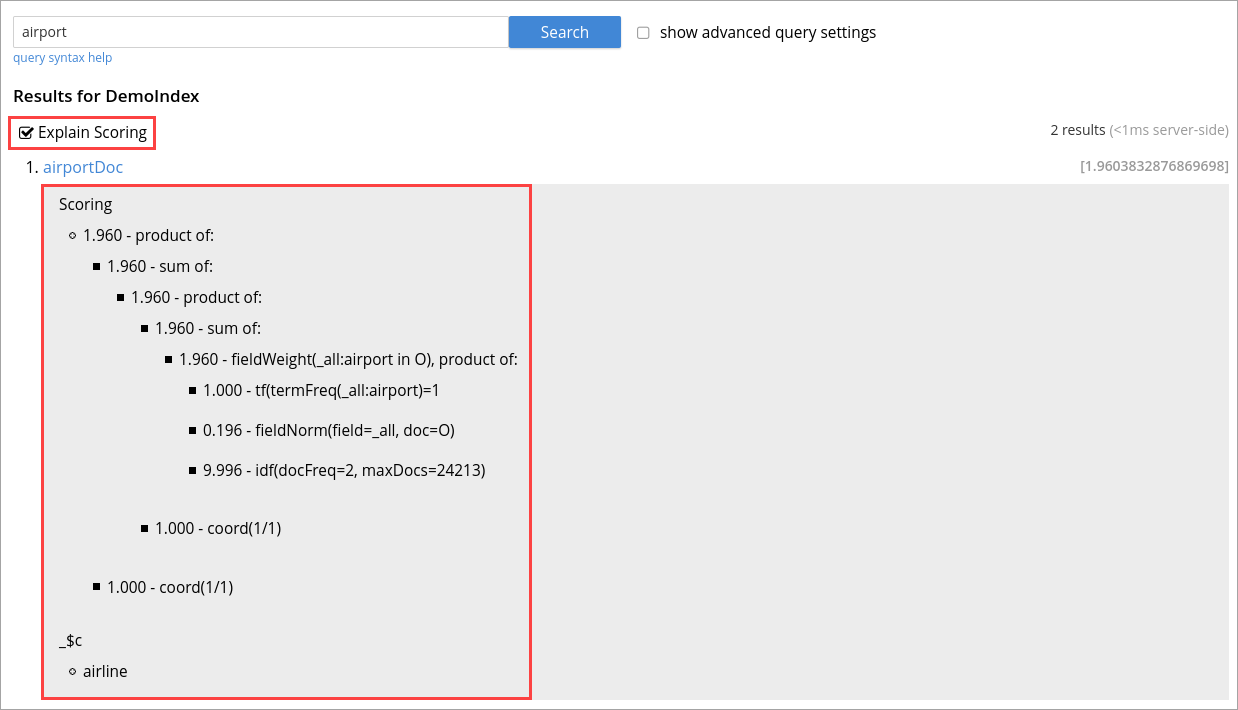
Search query scores all the qualified documents for relevance and applies relevant filters.
In a search request, you can set score to none to disable scoring by. See Score:none
Example
The following sample query response shows the score field for each document retrieved for the query request:
"hits": [
{
"index": "DemoIndex_76059e8b3887351c_4c1c5584",
"id": "hotel_10064",
"score": 10.033205341869529,
"sort": [
"_score"
],
"fields": {
"_$c": "hotel"
}
},
{
"index": "DemoIndex_76059e8b3887351c_4c1c5584",
"id": "hotel_10063",
"score": 10.033205341869529,
"sort": [
"_score"
],
"fields": {
"_$c": "hotel"
}
}
],
"total_hits": 2,
"max_score": 10.033205341869529,
"took": 284614211,
"facets": null
}tf-idf
tf-idf, a short form of term frequency-inverse document frequency, is a numerical statistical value that is used to reflect how important a word is to a document in collection or scope.
tf-idf is used as a weighting factor in a search for information retrieval and text mining. The tf–idf value increases proportionally to the number of times a word appears in the document, and it is offset by the number of documents in the collection or scope that contains the word.
Search engines often use the variations of tf-idf weighting scheme as a tool in scoring and ranking a document’s relevance for a given query. The tf-idf scoring for a document relevancy is done on the basis of per-partition index, which means that documents across different partitions may have different scores.
When bleve scores a document, it sums a set of sub scores to reach the final score. The scores across different searches are not directly comparable as the scores are directly dependent on the search criteria. So, changing the search criteria, like terms, boost factor etc. can vary the score.
The more conjuncts/disjuncts/sub clauses in a query can influence the scoring. Also, the score of a particular search result is not absolute, which means you can only use the score as a comparison to the highest score from the same search result.
FTS does not provide any predefined range for valid scores.
In Couchbase application, you get an option to explore the score computations during any search in FTS.
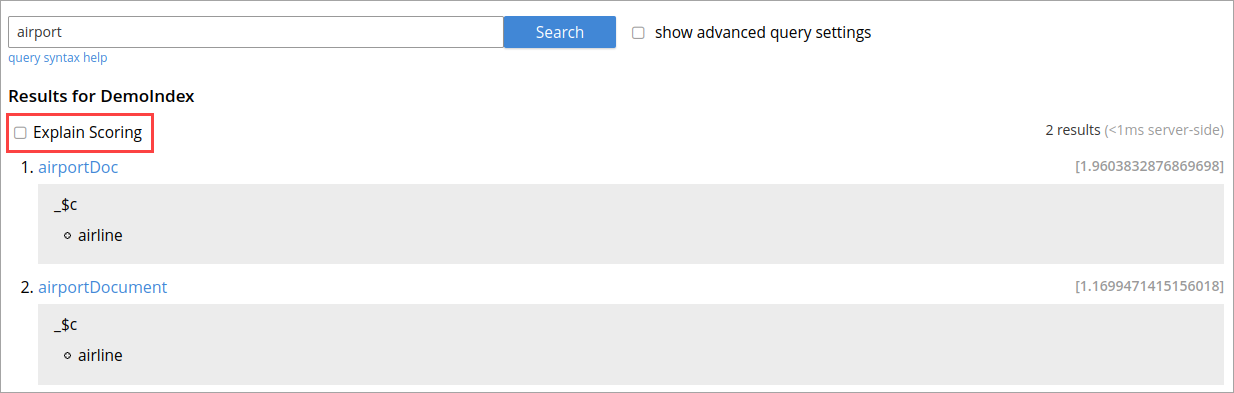
On the Search page, you can search for a term in any index. The search result displays the search records along with the option Explain Scoring to view the score deriving details for search hits and which are determined by using the tf-idf algorithm.
Score:none
You can disable the scoring by setting score to none in the search request. This is recommended in a situation where scoring (document relevancy) is not needed by the application.
Using "score": "none" is expected to boost query performance in certain situations.
|
Scoring Tips and Recommendations
For a select term, FTS calculates the relevancy score. So, the documents having a higher relevancy score automatically appear at the top in the result.
It is often observed that users are using Full-Text Search for the exact match queries with a bit of fuzziness or other search-specific capabilities like geo.
Text relevancy score does not matter when the user is looking for exact or more targeted searches with many predicates or when the dataset size is small.
In such a case, FTS unnecessarily uses more resources in calculating the relevancy score. Users can, however, optimize the query performance by skipping the scoring. Users may skip the scoring by passing a “score”: “none” option in the search request.
Consistency
A mechanism to ensure that the Full Text Search (FTS) index can obtain the most up-to-date version of the document written to a collection or a bucket.
The consistency mechanism provides Consistency Vectors as objects in the search query that ensures FTS index searches all your last data written to the vBucket.
The search service does not respond to the query until the designated vBucket receives the correct sequence number.
The search query remains blocked while continuously polling the vBucket for the requested data. Once the sequence number of the data is obtained, the query is executed over the data written to the vBucket.
When using this consistency mode, the query service will ensure that the indexes are synchronized with the data service before querying.
Workflow to understand Consistency
-
Create an FTS index in Couchbase.
-
Write a document to the Couchbase cluster.
-
Couchbase returns the associate vector to the app, which needs to issue a query request with the vector.
-
The FTS index starts searching the data written to the vBucket.
In this workflow, it is possible that the document written to vBucket is not yet indexed. So, when FTS starts searching that document, the most up-to-date document versions are not retrieved, and only the indexed versions are queried.
Therefore, the Couchbase server provides a consistency mechanism to overcome this issue and ensures that the FTS index can search the most up-to-date document written to vBucket.
Consistency Level
The consistency level is a parameter that either takes an empty string indicating the unbounded (not_bounded) consistency or at_plus indicating the bounded consistency.
at_plus
Executes the query, requiring indexes first to be updated to the timestamp of the last update.
This implements bounded consistency. The request includes a scan_vector parameter and value, which is used as a lower bound. This can be used to implement read-your-own-writes (RYOW).
If index-maintenance is running behind, the query waits for it to catch up.
not_bounded
Executes the query immediately, without requiring any consistency for the query. No timestamp vector is used in the index scan.
This is the fastest mode, because it avoids the costs of obtaining the vector and waiting for the index to catch up to the vector.
If index-maintenance is running behind, out-of-date results may be returned.
Consistency Vectors
The consistency vectors supporting the consistency mechanism in Couchbase contain the mapping of the vbucket and sequence number of the data stored in the vBucket.
For more information about consistency mechanism, see Consistency
Example
{
"ctl": {
"timeout": 10000,
"consistency": {
"vectors": {
"index1": {
"607/205096593892159": 2,
"640/298739127912798": 4
}
},
"level": "at_plus"
}
},
"query": {
"match": "jack",
"field": "name"
}
}In the example above, this is the set of consistency vectors.
"index1": {
"607/205096593892159": 2,
"640/298739127912798": 4
}
The query is looking within the FTS index "index1" - for:
-
vbucket 607 (with UUID 205096593892159) to contain sequence number 2
-
vbucket 640 (with UUID 298739127912798) to contain sequence number 4
Consistency Timeout
It is the amount of time (in milliseconds) the search service will allow for a query to execute at an index partition level.
If the query execution surpasses this timeout value, the query is canceled. However, at this point if some of the index partitions have responded, you might see partial results, otherwise no results at all.
{
"ctl": {
"timeout": 10000,
"consistency": {
"vectors": {
"index1": {
"607/205096593892159": 2,
"640/298739127912798": 4
}
},
"level": "at_plus"
}
},
"query": {
"match": "jack",
"field": "name"
}
}Consistency Results
Consistency result is the attribute that you can use to set the query result option, such as complete.
The "Complete" option
The complete option allows you to set the query result as "complete" which indicates that if any of the index partitions are unavailable due to the node not being reachable, the query will display an error in response instead of partial results.
Consistency Tips and Recommendations
Consistency vectors provide "read your own writes" functionality where the read operation waits for a specific time until the write operation is finished.
When users know that their queries are complex which require more time in completing the write operations, they can set the timeout value higher than the default timeout of 10 seconds so that consistency can be obtained in the search operations.
However, if this consistency is not required, the users can optimize their search operations by using the default timeout of 10 seconds.
Facets
Facets are aggregate information collected on a particular result set.
In Facets, you already have a search in mind, and you want to collect additional facet information along with it.
Facet-query results may not equal the total number of documents across all buckets if:
-
There is more than one pindex.
-
Facets_size is less than the possible values for the field.
Facets Results
For each facet that you build, a FacetResult is returned containing the following:
-
Field: The name of the field the facet was built on.
-
Total: The total number of values encountered (if each document had one term, this should match the total number of documents in the search result)
-
Missing: The number of documents which do not have any value for this field
-
Other: The number of documents for which a value exists, but it was not in the top N number of facet buckets requested
-
Array of Facets: Each Facet contains the count indicating the number of items in this facet range/bucket:
-
Term: Terms Facets include the name of the term.
-
Numeric Range: Numeric Range Facets include the range for this bucket.
-
DateTime Range: DateTime Range Facets include the datetime range for this bucket.
-
All of the facet examples given in this topic are for the query "water" on the beer-sample dataset.
FTS supports the following types of facets:
-
Term Facet - A term facet counts up how many of the matching documents have a particular term in a particular field.
Most of the time, this only makes sense for relatively low cardinality fields, like a type or tags.
It would not make sense to use it on a unique field like an ID.
-
Field: The field over which you want to gather the facet information.
-
Size: The number of top categories per partition to be considered for the facet results.
For example, size - 3 ⇒ facets results returns the top 3 categories across all partitions and merges them as the final result.
Varying size value varies the count value of each facet and the “others” value as well. This is due to the fact that when the size is varied, some of the categories fall out of the top “n” and into the “others” category.
It is recommended to keep the size reasonably large, close to the number of unique terms to get consistent results. -
Numeric Range Facet: A numeric range facet works by the user defining their own buckets (numeric ranges).
The facet then counts how many of the matching documents fall into a particular bucket for a particular field.
Along with the two fields from term facet, “numeric_ranges” field has to include all the numeric ranges for the faceted field.
“Numeric_ranges” could possibly be an array of ranges and each entry of it must specify either min, max or both for the range.
-
Name: Name for the facet.
-
Min: The lower bound value of this range.
-
Max: The upper bound value of this range.
-
-
Date Range Facet: The Date Range facet is same as numeric facet, but on dates instead of numbers. Full text search and Bleve expect dates to be in the format specified by RFC-3339, which is a specific profile of ISO-8601 that is more restrictive.
Along with the two fields from term facet, “date_ranges” field has to include all the numeric ranges for the faceted field.
The facet ranges go under a field named “date_ranges”.
“date_ranges” could possibly be an array of ranges and each entry of it must specify either start, end or both for the range.
-
Name: Name for the facet.
-
Start: Start date for this range.
-
End: End date for this range.
-
| Most of the time, when building a term facet, you must use the keyword analyzer. Otherwise, multi-term values are tokenized, which might cause unexpected results. |
Example
Term Facet
Computes facet on the type field which has 2 values: beer and brewery.
curl -X POST -H "Content-Type: application/json" \
http://localhost:8094/api/index/bix/query -d \
'{
"size": 10,
"query": {
"boost": 1,
"query": "water"
},
"facets": {
"type": {
"size": 5,
"field": "type"
}
}
}'Result:
The result snippet below, only shows the facet section for clarity. Run the curl command to see the HTTP response containing the full results.
"facets": {
"type": {
"field": "type",
"total": 91,
"missing": 0,
"other": 0,
"terms": [
{
"term": "beer",
"count": 70
},
{
"term": "brewery",
"count": 21
}
]
}
}Numeric Range Facet
Computes facet on the abv field with two buckets describing high (greater than 7) and low (less than 7).
curl -X POST -H "Content-Type: application/json" \
http://localhost:8094/api/index/bix/query -d \
'{
"size": 10,
"query": {
"boost": 1,
"query": "water"
},
"facets": {
"abv": {
"size": 5,
"field": "abv",
"numeric_ranges": [
{
"name": "high",
"min": 7
},
{
"name": "low",
"max": 7
}
]
}
}
}'Results:
facets": {
"abv": {
"field": "abv",
"total": 70,
"missing": 21,
"other": 0,
"numeric_ranges": [
{
"name": "high",
"min": 7,
"count": 13
},
{
"name": "low",
"max": 7,
"count": 57
}
]
}
}Date Range Facet
Computes facet on the ‘updated’ field that has 2 values old and new
curl -XPOST -H "Content-Type: application/json" -u username:password http://<node>:8094/api/index/bix/query -d '{
"ctl": {"timeout": 0},
"from": 0,
"size": 0,
"query": {
"field": "country",
"term": "united"
},
"facets": {
"types": {
"size": 10,
"field": "updated",
"date_ranges": [
{
"name": "old",
"end": "2010-08-01"
},
{
"name": "new",
"start": "2010-08-01"
}
]
}
}
}'Results:
"facets": {
"types": {
"field": "updated",
"total": 954,
"missing": 0,
"other": 0,
"date_ranges": [
{
"name": "old",
"end": "2010-08-01T00:00:00Z",
"count": 934
},
{
"name": "new",
"start": "2010-08-01T00:00:00Z",
"count": 20
}
]
}
}Highlighting
The Highlight object indicates whether highlighting was requested.
The pre-requisite includes term vectors and store options to be enabled at the field level to support Highlighting.
The highlight object contains the following fields:
-
style - (Optional) Specifies the name of the highlighter. For example, "html"or "ansi".
-
fields - Specifies an array of field names to which Highlighting is restricted.
Example 1
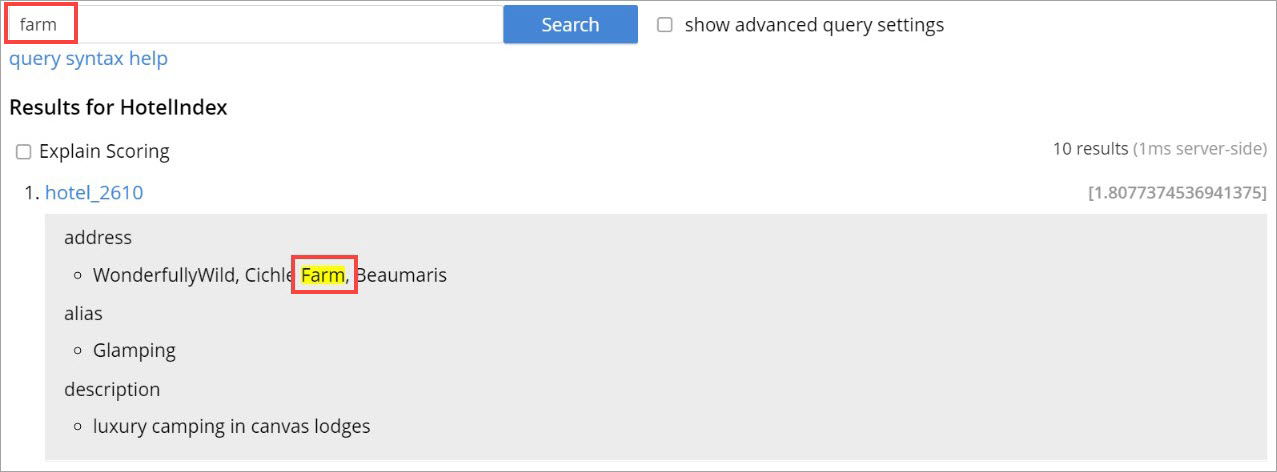
As per the following example, when you search the content in the index, the matched content in the address field is highlighted in the search response.
curl -u username:password -XPOST -H "Content-Type: application/json" \
http://localhost:8094/api/index/travel-sample-index/query \
-d '{
"explain": true,
"fields": [
"*"
],
"highlight": {
"style":"html",
"fields": ["address"]
},
"query": {
"query": "address:farm"
}
}'
Example 2
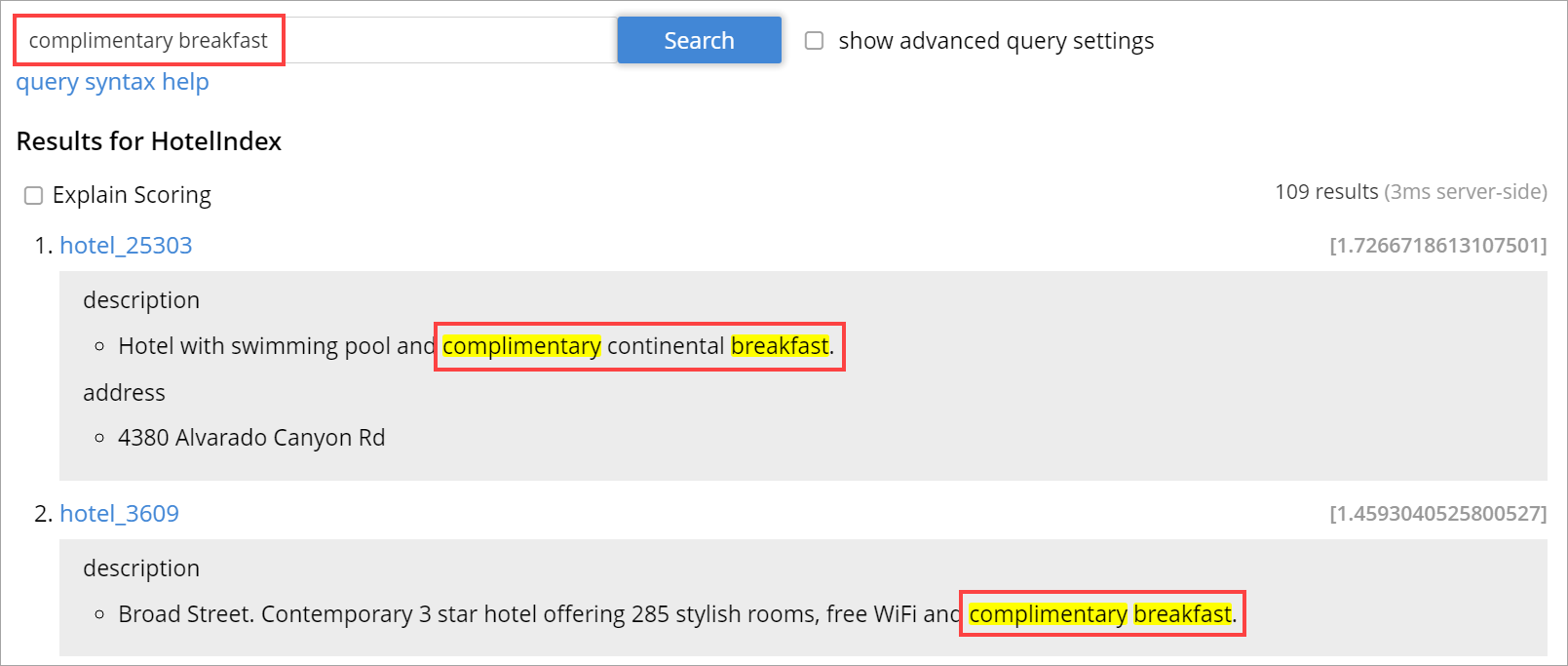
As per the following example, when you search the content in the index, the matched content in the description field is highlighted in the search response.
curl -u username:password -XPOST -H "Content-Type: application/json" \
http://localhost:8094/api/index/travel-sample-index/query \
-d '{
"explain": true,
"fields": [
"*"
],
"highlight": {
"style":"html",
"fields": ["description"]
},
"query": {
"query": "description:complementary breakfast"
}
}'
Hits
Hits return an array containing the matches for the executed query.
The length of the array is equal to or less than the size specified in the request.
- Index
-
The unique ID of the pindex. The index name always begins with a string.
- ID
-
The document ID that matched.
- Score
-
The document score.
- Locations
-
This object contains field names where matches were found. The "Locations" object depends on the term vectors being stored; if term vectors are not stored, locations are not returned in the result object.
{Field Name}
Lists the field names where the match was found. These fields are scoped so that "description: american" searches for "american" scoped to the "description" field. In the example below, there are two fields named "description" and "name".
{Term Found}
A name value pair whose name is the name of the term that was found and whose value is an array on objects representing the vector information that describes the position of the matched term in the field. This value is only present if the term vectors are calculated. For each match, the object contains the position (
pos), start, end, and array positions (array_positions).Sample Locations Fragment"locations": { "reviews.content": { "light": [ { "pos": 277, "start": 1451, "end": 1456, "array_positions": [ 0 ] }, { "pos": 247, "start": 1321, "end": 1326, "array_positions": [ 3 ] } ] } }, - Fragments
-
These objects, also known as snippets, contain field names that contain an array of one or more text strings. The text strings contain the "
<mark>" tags surrounding the term that was matched in order to render highlighting. - Fields
-
This object returns the value of the field that was matched. However, unlike the Fragments field, this does not have any tags to render highlighting.
- Sort
-
This field contains an array of one or more values that were used to sort the search results. Documents that don’t have a value in the index for a particular field used in sorting will return a series of non-printable Unicode characters:
\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd.
Error Information
| For all errors listed in the table below, the "status" in the search response always show "fail". |
| Error/Reason | Description | Response Status | Response Description |
|---|---|---|---|
success |
query was processed successfully. |
200 |
OK |
query request rejected |
high memory consumption, throttler steps in |
429 |
Too many requests |
authentication failure |
incorrect auth credentials or no permissions |
403 |
Forbidden |
malformed query request |
unrecognized/bad query |
400 |
Bad request |
page not found |
endpoint is invalid |
404 |
Not found |
pre-condition failed |
pre-condition not met - consistency error |
412 |
Precondition failed |
.* |
an error that the server can potentially recover from |
500 |
Internal server error |
Partial Errors
It is possible that when some of the index partitions have reported failures, the "status" in the response does not show fail. This is when the user will see a partial result set for their query.
Below is the sample response
{
"status": {
"total": 6,
"failed": 2,
"successful": 4,
"errors": {
"pindex_name_1": "xyz",
"pindex_name_2": "xyz"
}
},
"request": {
"query": {
...
},
"size": 10,
"from": 0,
"facets": {},
"sort": [
"-_score"
]
},
"hits": [...],
"total_hits": ...,
"max_score": ...,
"took": ...,
"facets": {}
}If one or more of the index partitions failed to cater to the request, the user can see partial results. In such a case, the response status is shown as 200 , and the errors object in the response will be a non-zero length value.
| Partial Error | Description |
|---|---|
context deadline exceeded |
request wasn’t processed/responded-to by the partition in the requested time period |
no planPIndexes for indexName |
FTS node in the process of a rebalance, partitions are being moved |
bleve: pindex_consistency mismatched partition |
RYOW failure - received data from a vbucket with a different UUID while waiting on a sequence number - possibly due to KV rebalance/failover |
pindex not available |
one or more primary index partitions (that do not have replicas) have been failed over (need to rebalance to set them up again) |
cannot perform operation on empty alias |
one or more index partitions are in the process of being set up during a rebalance |
Search Status Expect
A Full Text Search Response Object is composed of multiple child objects that provides important information.
Status
The status object includes the number of successful and failed partition indexes queries.
We recommend that the status object be checked for failures as a preferred alternative to relying on HTTP response codes alone. For example, FTS returns an HTTP 200 response in case of partition index failures or timeouts (not consistency timeouts). This is done so that you can choose to accept partial results in an application. However, this also means FTS returns an HTTP 200 response even when ALL partition indexes fail.
Refer to the following table for more information about the possible status messages.
| Status | Description |
|---|---|
HTTP 400 |
Returned when an error is detected when validating the inputs. The text error message accompanying the status describes the problem. |
HTTP 412 |
Returned when the consistency requirements are not satisfied within the specified timeout. The JSON structure accompanying the status provides information about the current consistency levels. |
HTTP 200 |
Returned when an error is detected during query execution. The errors might be contained in the JSON section named "status". |
- Total
-
The
totalfield returns an integer representing the total number of partition indexes queried. This value varies depending on how your index is configured, the platform you are running on, and whether you are querying an index or an index alias. Each index has a setting for the number of vBuckets per pindex. For example, when running on a cluster with 1024 vBuckets and with an index setting of 171 vBuckets per pindex, the total number of partition indexes is 6. When you query an index alias,totalis the sum of all the partition indexes in each index that is included in the definition of the index alias. - Successful
-
This field returns the total number of partition indexes successfully queried. This integer value can range from 0 to the total number of partition indexes.
Example Status: Successful"status": { "total": 6, "failed": 0, "successful": 6 }, - Failed
-
This field returns the total number of partition indexes with failed queries. This integer value can range from 0 to the total number of partition indexes. If the number is greater than 0, the response object contains an
errorsarray. - Errors
-
This field returns an array of error messages as reported by individual partition indexes. This array only appears if the field "failed" is greater than 0.
Example Status: Failure"status": { "total":6, "failed":3, "successful":6, "errors":{ "IndexClient - http://127.0.0.1:9201/api/pindex/beer-search_447fd6df2d6f4b54_0a44bddb":"context deadline exceeded", "IndexClient - http://127.0.0.1:9201/api/pindex/beer-search_447fd6df2d6f4b54_24e7ea2d":"context deadline exceeded", ... } }
Search Response Score
Scoring of results, according to relevancy, allows users to obtain result-sets that only contain documents awarded the highest scores. This keeps result-sets manageably small, even when the total number of documents returned is extremely large. The response returns the score of the search query.
Scores are directly dependent on the search criteria. Changing the search criteria can vary the score, and therefore, scores are not comparable across searches.
For more details on scores, follow the link Scoring
Array Positions
For each match, the object contains the position (pos), start, end, and array positions (array_positions).
"locations": {
"reviews.content": {
"light": [
{
"pos": 277,
"start": 1451,
"end": 1456,
"array_positions": [
0
]
},
{
"pos": 247,
"start": 1321,
"end": 1326,
"array_positions": [
3
]
}
]
}
},