Parquet
- Capella Analytics
- reference
This topic explains how to use the COPY TO statement to export data from a database to Amazon S3, Google Cloud Storage (GCS), or Azure Blob Storage in Parquet format.
Having results in Parquet format is highly efficient due to its Capella Analytics storage, which enables better compression and faster query performance.
Parquet files takes less storage space, making it cost-effective for large-scale data storage and analytics.
The optimized format is for read-heavy workloads making it ideal for big data processing, data warehousing, and machine learning pipelines.
For more information, see Amazon S3, Google Cloud Storage (GCS), and Azure Blob Storage.
| To be able to read or write data to or from external cloud storage, exclusive permissions are required. For more information see Cloud Read/Write Permissions. |
Supported Methods
You can copy data using one of the two methods:
-
User-Defined Schema: It’s a schema explicitly provided by the user in the
COPY TOstatement when the structure of the result or collection is known. -
Schema Inference: The system infers the schema from the data.
Syntax
CopyTo EBNF
CopyTo ::= "COPY" SourceDefinition
"TO" ContainerIdentifier
"AT" LinkQualifiedName
OutputClause WithClauseCopyTo Diagram

Show SourceDefinition Diagram

Show OutputClause Diagram

Show OutputPathExpr Diagram

Show OverClause Diagram

Show SchemaClause Diagram

Show TypeExpression Diagram
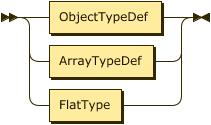
Show ObjectTypeDefinition Diagram
Show ArrayTypeDefinition Diagram

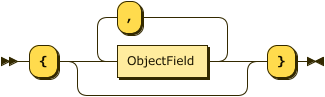
Show ObjectField Diagram

Show PartitionClause Diagram
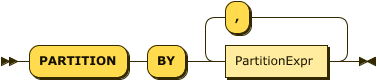
Show PartitionExpr Diagram

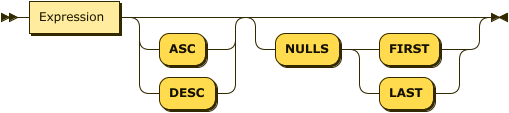
Show OrderClause Diagram
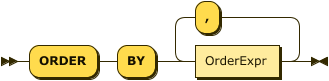
Show OrderExpr Diagram
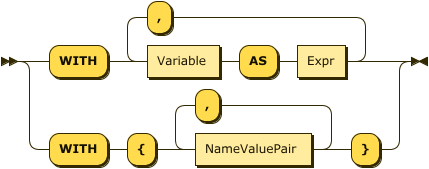
Show WithClause Diagram
Show NameValuePair Diagram
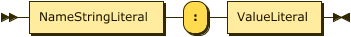
Examples
You can copy the Customer Data from Example Data in parquet format with gzip compression.
Example 1: Syntax for User-Defined Schema
COPY (
SELECT * from customers
) AS t
TO myS3Bucket AT myS3Link
PATH("commerce/Customers/zip=" || zip || "/")
OVER(PARTITION BY t.address.zipcode AS zip)
TYPE (
{
orderno : int ,
custid : string,
order_date : date,
ship_date : date,
items : [ { itemno:int, qty : int, price : double } ]
}
)
WITH {
"format": "parquet" ,
"compression": "gzip"
}Example 2: Syntax for Schema Inference
COPY (
SELECT * from customers
) AS t
TO myS3Bucket AT myS3Link
PATH("commerce/Customers/zip=" || zip || "/")
OVER(PARTITION BY t.address.zipcode AS zip)
WITH {
"format": "parquet",
"compression": "gzip"
}Arguments
- SourceDefinition
-
As the source, you specify either the fully qualified name of a collection or provide a query.
-
If you specify a collection name, then the whole collection—or view or synonym—is the source of data to copy.
-
If you specify a query, then the result of that query is the source of data.
-
- TO
-
The
TOclause identifies the bucket name on the external data source, an Amazon S3 bucket in this case.
- AT
-
The
ATclause specifies the name of the link that contains credentials for the S3 bucket name. The specified link must have a type of S3.
- OutputClause
-
The
OutputClausedefines the destination path for the output objects. You supply one or moreOutputPathExprexpressions to identify the path prefixes. You can include aliases. If you supply more than one expression, Capella Analytics concatenates the values of allOutputPathExprand supplies/characters as the path separators. As a result, you do not need to include slash characters betweenOutputPathExprexpressions.
| The target directory that you specify in the destination path must be empty. The operation fails if the target directory is not empty. |
- OverClause
-
You supply an optional
OverClauseto specify output partitioning with aPartitionClauseand ordering with anOrderClause. This is similar to theOVERclause of a WINDOW statement.-
If you specify a
PartitionClause, Capella Analytics evaluates theOutput_Path_Expronce per logical data partition and refers to aliases if defined by anASsub-clause. -
If you do not specify a
PartitionClause, Capella Analytics evaluates theOutputPathExpronce for the wholeCOPY TOoutput dataset. That’s, all of the files end up in the same directory.
-
You use the OrderClause to define output object order, either within each partition or for the whole dataset.
- SchemaClause
-
The
SchemaClausedefines the schema for the outputParquetfiles. You specify the schema using a JSON-like format: {field-name1:type1,field-name2:type2, … }. The types can be flat types, array types, or object types. Supported flat types are listed in the Supported Types section.
- WITH
-
You use the
WITHclause to specify the following additional parameters.
| Name | Description | Schema |
|---|---|---|
format (optional) |
Allowed values: "parquet" Default: JSON |
String Enum |
max-objects-per-file |
Maximum number of objects per file. Default: 10000. |
int |
max-schemas(optional) |
Maximum number of heterogeneous schemas allowed. This value cannot be greater than 10. This value is valid only for schemaless mode (with TYPE not provided). Default : 5 |
int |
compression (Optional) |
Allowed values: "none", "snappy", "gzip","lzo","brotli","lz4","zstd" Default: none |
String enum |
row-group-size(Optional) |
Row Group Size in parquet file in byte values. Default: 10 MB |
String |
page-size(Optional) |
Page Size in parquet file in byte values. Default: 8 KB |
String |
version(Optional) |
Parquet Writer Version. Allowed values : 1,2 Default: 1 |
String Enum |
Supported Data Types
The supported types and the corresponding parquet types are in the following table:
| Analytics Type | Parquet Type |
|---|---|
boolean |
BOOLEAN |
string |
BINARY(STRING) |
tinyint, smallint, int |
INT32 |
bigint |
INT64 |
float |
FLOAT |
double |
DOUBLE |
date |
INT32(DATE) |
time |
INT32(TIME_MILLIS) |
datetime |
INT64(TIMESTAMP_MILLIS) |
UUID |
FIXED_LEN_BYTE_ARRAY(UUID) |