QueryBuilder
Description — How to use QueryBuilder to build effective queries with Couchbase Lite on Java
Related Content — Predictive Queries | Live Queries | Indexing
| The examples used here are based on the Travel Sample app and data introduced in the Couchbase Mobile Workshop tutorial |
Introduction
Couchbase Lite for Java provides two ways to build and run database queries; the QueryBuilder API described in this topic and SQL++ for Mobile.
Database queries defined with the QueryBuilder API use the query statement format shown in Example 1. The structure and semantics of the query format are based on Couchbase’s SQL++ query language.
SELECT ____
FROM 'data-source'
WHERE ____,
JOIN ____
GROUP BY ____
ORDER BY ____- Query Components
| Component | Description |
|---|---|
The document properties that will be returned in the result set |
|
FROM |
The data source to query the documents from - the collection of the database. |
The query criteria |
|
The criteria for joining multiple documents |
|
The criteria used to group returned items in the result set |
|
The criteria used to order the items in the result set |
| We recommend working through the query section of the Couchbase Mobile Workshop tutorial as a good way to build your skills in this area. |
SELECT statement
- In this section
- Related
Use the SELECT statement to specify which properties you want to return from the queried documents.
You can opt to retrieve entire documents, or just the specific properties you need.
Return All Properties
Use the SelectResult.all() method to return all the properties of selected documents — see: Example 2.
This query shows how to retrieve all properties from all documents in your database.
Query query = QueryBuilder
.select(SelectResult.all())
.from(DataSource.collection(collection))
.where(Expression.property("type").equalTo(Expression.string("hotel")));The query.execute statement returns the results in a dictionary, where the key is the database name — see Example 3.
[
{
"travel-sample": { (1)
"callsign": "MILE-AIR",
"country": "United States",
"iata": "Q5",
"icao": "MLA",
"id": 10,
"name": "40-Mile Air",
"type": "airline"
}
},
{
"travel-sample": { (2)
"callsign": "ALASKAN-AIR",
"country": "United States",
"iata": "AA",
"icao": "AAA",
"id": 10,
"name": "Alaskan Airways",
"type": "airline"
}
}
]| 1 | The result for the first document matching the query criteria. |
| 2 | The result for the next document matching the query criteria. |
See: Result Sets for more on processing query results.
Return Selected Properties
To access only specific properties, specify a comma-separated list of SelectResult expressions, one for each property, in the select statement of your query — see: Example 4
In this query we retrieve and then print the _id, type and name properties of each document.
Query query = QueryBuilder
.select(
SelectResult.expression(Meta.id),
SelectResult.property("name"),
SelectResult.property("type"))
.from(DataSource.collection(collection))
.where(Expression.property("type").equalTo(Expression.string("hotel")))
.orderBy(Ordering.expression(Meta.id));
try (ResultSet resultSet = query.execute()) {
for (Result result: resultSet) {
Logger.log("hotel id -> " + result.getString("id"));
Logger.log("hotel name -> " + result.getString("name"));
}
}The query.execute statement returns one or more key-value pairs, one for each SelectResult expression, with the property-name as the key — see Example 5
[
{ (1)
"id": "hotel123",
"type": "hotel",
"name": "Hotel Ghia"
},
{ (2)
"id": "hotel456",
"type": "hotel",
"name": "Hotel Deluxe",
}
]| 1 | The result for the first document matching the query criteria. |
| 2 | The result for the next document matching the query criteria. |
See: Result Sets for more on processing query results.
WHERE statement
- In this section
-
Comparison Operators | Collection Operators | Like Operator | Regex Operator | Deleted Document
Like SQL, you can use the WHERE statement to choose which documents are returned by your query.
The select statement takes in an Expression.
You can chain any number of Expressions in order to implement sophisticated filtering capabilities.
Comparison Operators
The Expression Comparators can be used in the WHERE statement to specify on which property to match documents.
In the example below, we use the equalTo operator to query documents where the type property equals "hotel".
[
{ (1)
"id": "hotel123",
"type": "hotel",
"name": "Hotel Ghia"
},
{ (2)
"id": "hotel456",
"type": "hotel",
"name": "Hotel Deluxe",
}
]Query query = QueryBuilder
.select(SelectResult.all())
.from(DataSource.collection(collection))
.where(Expression.property("type").equalTo(Expression.string("hotel")))
.limit(Expression.intValue(10));
try (ResultSet resultSet = query.execute()) {
for (Result result: resultSet) {
Dictionary all = result.getDictionary(collectionName);
Logger.log("name -> " + all.getString("name"));
Logger.log("type -> " + all.getString("type"));
}
}Collection Operators
ArrayFunction Collection Operators are useful to check if a given value is present in an array.
CONTAINS Operator
The following example uses the ArrayFunction to find documents where the public_likes array property contains a value equal to "Armani Langworth".
{
"_id": "hotel123",
"name": "Apple Droid",
"public_likes": ["Armani Langworth", "Elfrieda Gutkowski", "Maureen Ruecker"]
}Query query = QueryBuilder
.select(
SelectResult.expression(Meta.id),
SelectResult.property("name"),
SelectResult.property("public_likes"))
.from(DataSource.collection(collection))
.where(Expression.property("type").equalTo(Expression.string("hotel"))
.and(ArrayFunction
.contains(Expression.property("public_likes"), Expression.string("Armani Langworth"))));
try (ResultSet results = query.execute()) {
for (Result result: results) {
Logger.log("public_likes -> " + result.getArray("public_likes").toList());
}
}IN Operator
The IN operator is useful when you need to explicitly list out the values to test against.
The following example looks for documents whose first, last or username property value equals "Armani".
Expression[] values = new Expression[] {
Expression.property("first"),
Expression.property("last"),
Expression.property("username")
};
Query query = QueryBuilder.select(SelectResult.all())
.from(DataSource.collection(collection))
.where(Expression.string("Armani").in(values));Like Operator
- In this section
String Matching
The like operator performs case sensitive matches.To perform case insensitive matching, use Function.lower or Function.upper to ensure all comparators have the same case, thereby removing the case issue.
|
This query returns landmark type documents where the name matches the string "Royal Engineers Museum", regardless of how it is capitalized (so, it selects "royal engineers museum", "ROYAL ENGINEERS MUSEUM" and so on).
Query query = QueryBuilder
.select(
SelectResult.expression(Meta.id),
SelectResult.property("country"),
SelectResult.property("name"))
.from(DataSource.collection(collection))
.where(Expression.property("type").equalTo(Expression.string("landmark"))
.and(Function.lower(Expression.property("name")).like(Expression.string("royal engineers museum"))));
try (ResultSet resultSet = query.execute()) {
for (Result result: resultSet) {
Logger.log("name -> " + result.getString("name"));
}
}Note the use of Function.lower to transform name values to the same case as the literal comparator.
Wildcard Match
We can use % sign within a like expression to do a wildcard match against zero or more characters.
Using wildcards allows you to have some fuzziness in your search string.
In Example 8 below, we are looking for documents of type "landmark" where the name property matches any string that begins with "eng" followed by zero or more characters, the letter "e", followed by zero or more characters.
Once again, we are using Function.lower to make the search case insensitive.
So "landmark" documents with names such as "Engineers", "engine", "english egg" and "England Eagle". Notice that the matches may span word boundaries.
Query query = QueryBuilder
.select(
SelectResult.expression(Meta.id),
SelectResult.property("country"),
SelectResult.property("name"))
.from(DataSource.collection(collection))
.where(Expression.property("type").equalTo(Expression.string("landmark"))
.and(Function.lower(Expression.property("name")).like(Expression.string("eng%e%"))));
try (ResultSet resultSet = query.execute()) {
for (Result result: resultSet) {
Logger.log("name -> " + result.getString("name"));
}
}Wildcard Character Match
We can use an _ sign within a like expression to do a wildcard match against a single character.
In Example 9 below, we are looking for documents of type "landmark" where the name property matches any string that begins with "eng" followed by exactly 4 wildcard characters and ending in the letter "r".
The query returns "landmark" type documents with names such as "Engineer", "engineer" and so on.
Query query = QueryBuilder
.select(
SelectResult.expression(Meta.id),
SelectResult.property("country"),
SelectResult.property("name"))
.from(DataSource.collection(collection))
.where(Expression.property("type").equalTo(Expression.string("landmark"))
.and(Function.lower(Expression.property("name")).like(Expression.string("eng____r"))));
try (ResultSet resultSet = query.execute()) {
for (Result result: resultSet) {
Logger.log("name -> " + result.getString("name"));
}
}Regex Operator
Similar to the wildcards in like expressions, regex based pattern matching allow you to introduce an element of fuzziness in your search string — see the code shown in Example 10.
The regex operator is case sensitive, use upper or lower functions to mitigate this if required.
|
This example returns documents with a `type` of "landmark" and a `name` property that matches any string that begins with "eng" and ends in the letter "e".
Query query = QueryBuilder
.select(
SelectResult.expression(Meta.id),
SelectResult.property("country"),
SelectResult.property("name"))
.from(DataSource.collection(collection))
.where(Expression.property("type").equalTo(Expression.string("landmark"))
.and(Function.lower(Expression.property("name")).regex(Expression.string("\\beng.*r\\b"))));
try (ResultSet resultSet = query.execute()) {
for (Result result: resultSet) {
Logger.log("name -> " + result.getString("name"));
}
}| 1 | The \b specifies that the match must occur on word boundaries. |
| For more on the regex spec used by Couchbase Lite see cplusplus regex reference page |
Deleted Document
You can query documents that have been deleted (tombstones) [1] as shown in Example 11.
This example shows how to query deleted documents in the database. It returns is an array of key-value pairs.
// Query documents that have been deleted
Query query = QueryBuilder
.select(SelectResult.expression(Meta.id))
.from(DataSource.collection(collection))
.where(Meta.deleted);JOIN statement
The JOIN clause enables you to select data from multiple documents that have been linked by criteria specified in the JOIN statement. For example to combine airline details with route details, linked by the airline id — see Example 12.
This example JOINS the document of type route with documents of type airline using the document ID (id) on the _airline document and airlineid on the route document.
Query query = QueryBuilder.select(
SelectResult.expression(Expression.property("name").from("airline")),
SelectResult.expression(Expression.property("callsign").from("airline")),
SelectResult.expression(Expression.property("destinationairport").from("route")),
SelectResult.expression(Expression.property("stops").from("route")),
SelectResult.expression(Expression.property("airline").from("route")))
.from(DataSource.collection(collection).as("airline"))
.join(Join.join(DataSource.collection(collection).as("route"))
.on(Meta.id.from("airline").equalTo(Expression.property("airlineid").from("route"))))
.where(Expression.property("type").from("route").equalTo(Expression.string("route"))
.and(Expression.property("type").from("airline").equalTo(Expression.string("airline")))
.and(Expression.property("sourceairport").from("route").equalTo(Expression.string("RIX"))));
try (ResultSet resultSet = query.execute()) {
for (Result result: resultSet) {
Logger.log(result.toMap().toString());
}
}GROUP BY statement
You can perform further processing on the data in your result set before the final projection is generated.
The following example looks for the number of airports at an altitude of 300 ft or higher and groups the results by country and timezone.
{
"_id": "airport123",
"type": "airport",
"country": "United States",
"geo": { "alt": 456 },
"tz": "America/Anchorage"
}This example shows a query that selects all airports with an altitude above 300ft. The output (a count, $1) is grouped by country, within timezone.
Query query = QueryBuilder.select(
SelectResult.expression(Function.count(Expression.string("*"))),
SelectResult.property("country"),
SelectResult.property("tz"))
.from(DataSource.collection(collection))
.where(Expression.property("type").equalTo(Expression.string("airport"))
.and(Expression.property("geo.alt").greaterThanOrEqualTo(Expression.intValue(300))))
.groupBy(
Expression.property("country"),
Expression.property("tz"))
.orderBy(Ordering.expression(Function.count(Expression.string("*"))).descending());
try (ResultSet resultSet = query.execute()) {
for (Result result: resultSet) {
Logger.log(String.format(
"There are %d airports on the %s timezone located in %s and above 300ft",
result.getInt("$1"),
result.getString("tz"),
result.getString("country")));
}
}The query shown in Example 13 generates the following output:
There are 138 airports on the Europe/Paris timezone located in France and above 300 ft
There are 29 airports on the Europe/London timezone located in United Kingdom and above 300 ft
There are 50 airports on the America/Anchorage timezone located in United States and above 300 ft
There are 279 airports on the America/Chicago timezone located in United States and above 300 ft
There are 123 airports on the America/Denver timezone located in United States and above 300 ft
ORDER BY statement
It is possible to sort the results of a query based on a given expression result — see Example 14
This example shows a query that returns documents of type equal to "hotel" sorted in ascending order by the value of the title property.
Query query = QueryBuilder
.select(
SelectResult.expression(Meta.id),
SelectResult.property("name"))
.from(DataSource.collection(collection))
.where(Expression.property("type").equalTo(Expression.string("hotel")))
.orderBy(Ordering.property("name").ascending())
.limit(Expression.intValue(10));
try (ResultSet resultSet = query.execute()) {
for (Result result: resultSet) {
Logger.log(result.toMap().toString());
}
}The query shown in Example 14 generates the following output:
Aberdyfi
Achiltibuie
Altrincham
Ambleside
Annan
Ardèche
Armagh
AvignonDate/Time Functions
Couchbase Lite documents support a date type that internally stores dates in ISO 8601 with the GMT/UTC timezone.
Couchbase Lite’s Query Builder API [1] includes four functions for date comparisons.
Function.StringToMillis(Expression.Property("date_time"))-
The input to this will be a validly formatted ISO 8601
date_timestring. The end result will be an expression (with a numeric content) that can be further input into the query builder. Function.StringToUTC(Expression.Property("date_time"))-
The input to this will be a validly formatted ISO 8601
date_timestring. The end result will be an expression (with string content) that can be further input into the query builder. Function.MillisToString(Expression.Property("date_time"))-
The input for this is a numeric value representing milliseconds since the Unix epoch. The end result will be an expression (with string content representing the date and time as an ISO 8601 string in the device’s timezone) that can be further input into the query builder.
Function.MillisToUTC(Expression.Property("date_time"))-
The input for this is a numeric value representing milliseconds since the Unix epoch. The end result will be an expression (with string content representing the date and time as a UTC ISO 8601 string) that can be further input into the query builder.
Result Sets
- In this section
-
Processing | Select All Properties | Select Specific Properties | Select Document Id Only | Select Count-only | Handling Pagination
Processing
This section shows how to handle the returned result sets for different types of SELECT statements.
The result set format and its handling varies slightly depending on the type of SelectResult statements used. The result set formats you may encounter include those generated by :
-
SelectResult.all — see: All Properties
-
SelectResult.expression(property("name")) — see: Specific Properties
-
SelectResult.expression(meta.id) — Metadata (such as the
_id) — see: Document ID Only -
SelectResult.expression(Function.count(Expression.all())).as("mycount") — see: Select Count-only
To process the results of a query, you first need to execute it using Query.execute.
The execution of a Couchbase Lite for Java’s database query typically returns an array of results, a result set.
-
The result set of an aggregate, count-only, query is a key-value pair — see Select Count-only — which you can access using the count name as its key.
-
The result set of a query returning document properties is an array.
Each array row represents the data from a document that matched your search criteria (theWHEREstatements) The composition of each row is determined by the combination ofSelectResultexpressions provided in theSELECTstatement. To unpack these result sets you need to iterate this array.
Select All Properties
Query
The Select statement for this type of query, returns all document properties for each document matching the query criteria — see Example 15
Query listQuery = QueryBuilder.select(SelectResult.all())
.from(DataSource.collection(collection));Result Set Format
The result set returned by queries using SelectResult.all is an array of dictionary objects — one for each document matching the query criteria.
For each result object, the key is the database name and the 'value' is a dictionary representing each document property as a key-value pair — see: Example 16.
[
{
"travel-sample": { (1)
"callsign": "MILE-AIR",
"country": "United States",
"iata": "Q5",
"icao": "MLA",
"id": 10,
"name": "40-Mile Air",
"type": "airline"
}
},
{
"travel-sample": { (2)
"callsign": "ALASKAN-AIR",
"country": "United States",
"iata": "AA",
"icao": "AAA",
"id": 10,
"name": "Alaskan Airways",
"type": "airline"
}
}
]| 1 | The result for the first document matching the query criteria. |
| 2 | The result for the next document matching the query criteria. |
Result Set Access
In this case access the retrieved document properties by converting each row’s value, in turn, to a dictionary — as shown in Example 17.
Map<String, Hotel> hotels = new HashMap<>();
try (ResultSet resultSet = listQuery.execute()) {
for (Result result: resultSet) {
// get the k-v pairs from the 'hotel' key's value into a dictionary
Dictionary docsProp = result.getDictionary(0); (1)
String docsId = docsProp.getString("id");
String docsName = docsProp.getString("Name");
String docsType = docsProp.getString("Type");
String docsCity = docsProp.getString("City");
// Alternatively, access results value dictionary directly
final Hotel hotel = new Hotel();
hotel.setId(result.getDictionary(0).getString("id")); (2)
hotel.setType(result.getDictionary(0).getString("Type"));
hotel.setName(result.getDictionary(0).getString("Name"));
hotel.setCity(result.getDictionary(0).getString("City"));
hotel.setCountry(result.getDictionary(0).getString("Country"));
hotel.setDescription(result.getDictionary(0).getString("Description"));
hotels.put(hotel.getId(), hotel);
}
}| 1 | The dictionary of document properties using the database name as the key. You can add this dictionary to an array of returned matches, for processing elsewhere in the app. |
| 2 | Alternatively you can access the document properties here, by using the property names as keys to the dictionary object. |
Select Specific Properties
Query
Here we use SelectResult.expression(property("<property-name>"))) to specify the document properties we want our query to return — see: Example 18.
Query listQuery =
QueryBuilder.select(
SelectResult.expression(Meta.id),
SelectResult.property("name"),
SelectResult.property("Name"),
SelectResult.property("Type"),
SelectResult.property("City"))
.from(DataSource.collection(collection));Result Set Format
The result set returned when selecting only specific document properties is an array of dictionary objects — one for each document matching the query criteria.
Each result object comprises a key-value pair for each selected document property — see Example 19
[
{ (1)
"id": "hotel123",
"type": "hotel",
"name": "Hotel Ghia"
},
{ (2)
"id": "hotel456",
"type": "hotel",
"name": "Hotel Deluxe",
}
]| 1 | The result for the first document matching the query criteria. |
| 2 | The result for the next document matching the query criteria. |
Result Set Access
Access the retrieved properties by converting each row into a dictionary — as shown in Example 20.
HashMap<String, Hotel> hotels = new HashMap<>();
try (ResultSet resultSet = listQuery.execute()) {
for (Result result: resultSet) {
// get data direct from result k-v pairs
final Hotel hotel = new Hotel();
hotel.setId(result.getString("id"));
hotel.setType(result.getString("Type"));
hotel.setName(result.getString("Name"));
hotel.setCity(result.getString("City"));
// Store created hotel object in a hashmap of hotels
hotels.put(hotel.getId(), hotel);
// Get result k-v pairs into a 'dictionary' object
Map<String, Object> thisDocsProps = result.toMap();
String docId =
thisDocsProps.getOrDefault("id", null).toString();
String docName =
thisDocsProps.getOrDefault("Name", null).toString();
String docType =
thisDocsProps.getOrDefault("Type", null).toString();
String docCity =
thisDocsProps.getOrDefault("City", null).toString();
}
}Select Document Id Only
Query
You would typically use this type of query if retrieval of document properties directly would consume excessive amounts of memory and-or processing time — see: Example 21.
Query listQuery =
QueryBuilder.select(SelectResult.expression(Meta.id).as("metaID"))
.from(DataSource.collection(collection));Result Set Format
The result set returned by queries using a SelectResult expression of the form SelectResult.expression(meta.id) is an array of dictionary objects — one for each document matching the query criteria.
Each result object has id as the key and the ID value as its value — -see Example 22.
[
{
"id": "hotel123"
},
{
"id": "hotel456"
},
]Result Set Access
In this case, access the required document’s properties by unpacking the id and using it to get the document from the database — see: Example 23.
try (ResultSet rs = listQuery.execute()) {
for (Result result: rs.allResults()) {
// get the ID form the result's k-v pair array
String thisDocsId = result.getString("metaID"); (1)
// Get document from DB using retrieved ID
Document thisDoc = collection.getDocument(thisDocsId);
// Process document as required
String thisDocsName = thisDoc.getString("Name");
}
}| 1 | Extract the Id value from the dictionary and use it to get the document from the database |
Select Count-only
Query
Query listQuery = QueryBuilder.select(
SelectResult.expression(Function.count(Expression.string("*"))).as("mycount")) (1)
.from(DataSource.collection(collection));| 1 | The alias name, mycount, is used to access the count value. |
Result Set Format
The result set returned by a count such as Select.expression(Function.count(Expression.all))) is a key-value pair.
The key is the count name, as defined using SelectResult.as — see: Example 25 for the format and Example 24 for the query.
{
"mycount": 6
}| 1 | The key-value pair returned by a count. |
Result Set Access
Access the count using its alias name (mycount in this example) — see Example 26
try (ResultSet resultSet = listQuery.execute()) {
for (Result result: resultSet) {
// Retrieve count using key 'mycount'
Integer altDocId = result.getInt("mycount");
// Alternatively, use the index
Integer orDocId = result.getInt(0);
}
}
// Or even leave out the for-loop altogether
int resultCount;
try (ResultSet resultSet = listQuery.execute()) {
resultCount = resultSet.next().getInt("mycount");
}| 1 | Get the count using the SelectResult.as alias, which is used as its key. |
Handling Pagination
One way to handle pagination in high-volume queries is to retrieve the results in batches.
Use the limit and offset feature, to return a defined number of results starting from a given offset — see: Example 27.
int thisOffset = 0;
int thisLimit = 20;
Query listQuery =
QueryBuilder
.select(SelectResult.all())
.from(DataSource.collection(collection))
.limit(
Expression.intValue(thisLimit),
Expression.intValue(thisOffset)); (1)| 1 | Return a maximum of limit results starting from result number offset |
| For more on using the QueryBuilder API, see our blog: Introducing the Query Interface in Couchbase Mobile |
JSON Result Sets
Couchbase Lite for Java provides a convenience API to convert query results to JSON strings.
Use Result.toJSON() to transform your result string into a JSON string, which can easily be serialized or used as required in your application. See <
ObjectMapper mapper = new ObjectMapper();
ArrayList<Hotel> hotels = new ArrayList<>();
HashMap<String, Object> dictFromJSONstring;
try (ResultSet resultSet = listQuery.execute()) {
for (Result result: resultSet) {
// Get result as JSON string
String thisJsonString = result.toJSON(); (1)
// Get Java Hashmap from JSON string
dictFromJSONstring =
mapper.readValue(thisJsonString, HashMap.class); (2)
// Use created hashmap
String hotelId = dictFromJSONstring.get("id").toString();
String hotelType = dictFromJSONstring.get("type").toString();
String hotelname = dictFromJSONstring.get("name").toString();
// Get custom object from Native 'dictionary' object
Hotel thisHotel =
mapper.readValue(thisJsonString, Hotel.class); (3)
hotels.add(thisHotel);
}
}
// Uses Jackson JSON processor
ObjectMapper mapper = new ObjectMapper();
List<Hotel> hotels = new ArrayList<>();
try (ResultSet rs = listQuery.execute()) {
for (Result result: rs) {
String json = result.toJSON();
Map<String, String> dictFromJSONstring = mapper.readValue(json, HashMap.class);
String hotelId = dictFromJSONstring.get("id");
String hotelType = dictFromJSONstring.get("type");
String hotelname = dictFromJSONstring.get("name");
// Get custom object from JSON string
Hotel thisHotel = mapper.readValue(json, Hotel.class);
hotels.add(thisHotel);
}
}
}
public List<Map<String, Object>> docsOnlyQuerySyntaxN1QL(Database thisDb) throws CouchbaseLiteException {
// For Documentation -- N1QL Query using parameters
// Declared elsewhere: Database thisDb
Query thisQuery =
thisDb.createQuery(
"SELECT META().id AS thisId FROM _ WHERE type = \"hotel\""); (4)
List<Map<String, Object>> results = new ArrayList<>();
try (ResultSet rs = thisQuery.execute()) {
for (Result result: rs) { results.add(result.toMap()); }
}
return results;
}
public List<Map<String, Object>> docsonlyQuerySyntaxN1QLParams(Database thisDb) throws CouchbaseLiteException {
// For Documentation -- N1QL Query using parameters
// Declared elsewhere: Database thisDb
Query thisQuery =
thisDb.createQuery(
"SELECT META().id AS thisId FROM _ WHERE type = $type"); // <.
thisQuery.setParameters(
new Parameters().setString("type", "hotel")); (5)
List<Map<String, Object>> results = new ArrayList<>();
try (ResultSet rs = thisQuery.execute()) {
for (Result result: rs) { results.add(result.toMap()); }
}
return results;
}
}
//
// Copyright (c) 2023 Couchbase, Inc All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
package com.couchbase.codesnippets;
import androidx.annotation.NonNull;
import java.net.URI;
import java.net.URISyntaxException;
import java.security.KeyStore;
import java.security.KeyStoreException;
import java.security.cert.X509Certificate;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import com.couchbase.codesnippets.utils.Logger;
import com.couchbase.lite.BasicAuthenticator;
import com.couchbase.lite.Collection;
import com.couchbase.lite.CollectionConfiguration;
import com.couchbase.lite.CouchbaseLiteException;
import com.couchbase.lite.Database;
import com.couchbase.lite.DatabaseEndpoint;
import com.couchbase.lite.DocumentFlag;
import com.couchbase.lite.Endpoint;
import com.couchbase.lite.ListenerToken;
import com.couchbase.lite.ReplicatedDocument;
import com.couchbase.lite.Replicator;
import com.couchbase.lite.ReplicatorConfiguration;
import com.couchbase.lite.ReplicatorProgress;
import com.couchbase.lite.ReplicatorStatus;
import com.couchbase.lite.ReplicatorType;
import com.couchbase.lite.SessionAuthenticator;
import com.couchbase.lite.URLEndpoint;
@SuppressWarnings({"unused"})
public class ReplicationExamples {
private Replicator thisReplicator;
private ListenerToken thisToken;
public void activeReplicatorExample(Set<Collection> collections)
throws URISyntaxException {
// Create replicator
// Consider holding a reference somewhere
// to prevent the Replicator from being GCed
Replicator repl = new Replicator( (6)
// initialize the replicator configuration
new ReplicatorConfiguration(new URLEndpoint(new URI("wss://listener.com:8954"))) (7)
.addCollections(collections, null)
// Set replicator type
.setType(ReplicatorType.PUSH_AND_PULL)
// Configure Sync Mode
.setContinuous(false) // default value
// set auto-purge behavior
// (here we override default)
.setAutoPurgeEnabled(false) (8)
// Configure Server Authentication --
// only accept self-signed certs
.setAcceptOnlySelfSignedServerCertificate(true) (9)
// Configure the credentials the
// client will provide if prompted
.setAuthenticator(new BasicAuthenticator("Our Username", "Our Password".toCharArray())) (10)
);
// Optionally add a change listener (11)
ListenerToken token = repl.addChangeListener(change -> {
CouchbaseLiteException err = change.getStatus().getError();
if (err != null) { Logger.log("Error code :: " + err.getCode(), err); }
});
// Start replicator
repl.start(false); (12)
thisReplicator = repl;
thisToken = token;
}
public void replicatorSimpleExample(Set<Collection> collections) throws URISyntaxException {
Endpoint theListenerEndpoint
= new URLEndpoint(new URI("wss://10.0.2.2:4984/db")); (13)
ReplicatorConfiguration thisConfig =
new ReplicatorConfiguration(theListenerEndpoint) (14)
.addCollections(collections, null) // default configuration
.setAcceptOnlySelfSignedServerCertificate(true) (15)
.setAuthenticator(new BasicAuthenticator(
"valid.user",
"valid.password".toCharArray())); (16)
Replicator repl = new Replicator(thisConfig); (17)
// Start the replicator
repl.start(); (18)
// (be sure to hold a reference somewhere that will prevent it from being GCed)
thisReplicator = repl;
}
public void replicationBasicAuthenticationExample(
Set<Collection> collections,
CollectionConfiguration collectionConfig)
throws URISyntaxException {
// Create replicator (be sure to hold a reference somewhere that will prevent the Replicator from being GCed)
Replicator repl = new Replicator(
new ReplicatorConfiguration(new URLEndpoint(new URI("ws://localhost:4984/mydatabase")))
.addCollections(collections, collectionConfig)
.setAuthenticator(new BasicAuthenticator("username", "password".toCharArray())));
repl.start();
thisReplicator = repl;
}
public void replicationSessionAuthenticationExample(
Set<Collection> collections,
CollectionConfiguration collectionConfig)
throws URISyntaxException {
// Create replicator (be sure to hold a reference somewhere that will prevent the Replicator from being GCed)
Replicator repl = new Replicator(
new ReplicatorConfiguration(new URLEndpoint(new URI("ws://localhost:4984/mydatabase")))
.addCollections(collections, collectionConfig)
.setAuthenticator(new SessionAuthenticator("904ac010862f37c8dd99015a33ab5a3565fd8447")));
repl.start();
thisReplicator = repl;
}
public void replicationCustomHeaderExample(
Set<Collection> collections,
CollectionConfiguration collectionConfig)
throws URISyntaxException {
Map<String, String> headers = new HashMap<>();
headers.put("CustomHeaderName", "Value");
// Create replicator (be sure to hold a reference somewhere that will prevent the Replicator from being GCed)
Replicator repl = new Replicator(
new ReplicatorConfiguration(new URLEndpoint(new URI("ws://localhost:4984/mydatabase")))
.addCollections(collections, collectionConfig)
.setHeaders(headers));
repl.start();
thisReplicator = repl;
}
public void replicationPushFilterExample(Set<Collection> collections) throws URISyntaxException {
CollectionConfiguration collectionConfig = new CollectionConfiguration()
.setPushFilter((document, flags) -> flags.contains(DocumentFlag.DELETED)); (1)
// Create replicator (be sure to hold a reference somewhere that will prevent the Replicator from being GCed)
Replicator repl = new Replicator(
new ReplicatorConfiguration(new URLEndpoint(new URI("ws://localhost:4984/mydatabase")))
.addCollections(collections, collectionConfig));
repl.start();
thisReplicator = repl;
}
public void replicationPullFilterExample(Set<Collection> collections) throws URISyntaxException {
CollectionConfiguration collectionConfig = new CollectionConfiguration()
.setPullFilter((document, flags) -> "draft".equals(document.getString("type"))); (1)
// Create replicator (be sure to hold a reference somewhere that will prevent the Replicator from being GCed)
Replicator repl = new Replicator(
new ReplicatorConfiguration(new URLEndpoint(new URI("ws://localhost:4984/mydatabase")))
.addCollections(collections, collectionConfig));
repl.start();
thisReplicator = repl;
}
public void replicationResetCheckpointExample(Set<Collection> collections) throws URISyntaxException {
// Create replicator (be sure to hold a reference somewhere that will prevent the Replicator from being GCed)
Replicator repl = new Replicator(
new ReplicatorConfiguration(new URLEndpoint(new URI("ws://localhost:4984/mydatabase")))
.addCollections(collections, null));
repl.start(true);
// ... at some later time
repl.stop();
}
public void handlingNetworkErrorsExample(Set<Collection> collections) throws URISyntaxException {
// Create replicator (be sure to hold a reference somewhere that will prevent the Replicator from being GCed)
Replicator repl = new Replicator(
new ReplicatorConfiguration(new URLEndpoint(new URI("ws://localhost:4984/mydatabase")))
.addCollections(collections, null));
repl.addChangeListener(change -> {
CouchbaseLiteException error = change.getStatus().getError();
if (error != null) { Logger.log("Error code:: " + error); }
});
repl.start();
thisReplicator = repl;
}
public void certificatePinningExample(Set<Collection> collections, String keyStoreName, String certAlias)
throws URISyntaxException, KeyStoreException {
// Create replicator (be sure to hold a reference somewhere that will prevent the Replicator from being GCed)
Replicator repl = new Replicator(
new ReplicatorConfiguration(new URLEndpoint(new URI("ws://localhost:4984/mydatabase")))
.addCollections(collections, null)
.setPinnedServerX509Certificate(
(X509Certificate) KeyStore.getInstance(keyStoreName).getCertificate(certAlias)));
repl.start();
thisReplicator = repl;
}
public void replicatorConfigExample(Set<Collection> collections) throws URISyntaxException {
// initialize the replicator configuration
ReplicatorConfiguration thisConfig = new ReplicatorConfiguration(
new URLEndpoint(new URI("wss://10.0.2.2:8954/travel-sample"))) (19)
.addCollections(collections, null);
}
public void p2pReplicatorStatusExample(Replicator repl) {
ReplicatorStatus status = repl.getStatus();
ReplicatorProgress progress = status.getProgress();
Logger.log(
"The Replicator is " + status.getActivityLevel()
+ "and has processed " + progress.getCompleted()
+ " of " + progress.getTotal() + " changes");
}
public void p2pReplicatorStopExample(Replicator repl) {
// Stop replication.
repl.stop(); (20)
}
public void customRetryConfigExample(Set<Collection> collections) throws URISyntaxException {
Replicator repl = new Replicator(
new ReplicatorConfiguration(new URLEndpoint(new URI("ws://localhost:4984/mydatabase")))
.addCollections(collections, null)
// other config as required . . .
.setHeartbeat(150) (21)
.setMaxAttempts(20) (22)
.setMaxAttemptWaitTime(600)); (23)
repl.start();
thisReplicator = repl;
}
public void replicatorDocumentEventExample(Set<Collection> collections) throws URISyntaxException {
// Create replicator (be sure to hold a reference somewhere that will prevent the Replicator from being GCed)
Replicator repl = new Replicator(
new ReplicatorConfiguration(new URLEndpoint(new URI("ws://localhost:4984/mydatabase")))
.addCollections(collections, null));
ListenerToken token = repl.addDocumentReplicationListener(replication -> {
Logger.log("Replication type: " + ((replication.isPush()) ? "push" : "pull"));
for (ReplicatedDocument document: replication.getDocuments()) {
Logger.log("Doc ID: " + document.getID());
CouchbaseLiteException err = document.getError();
if (err != null) {
// There was an error
Logger.log("Error replicating document: ", err);
return;
}
if (document.getFlags().contains(DocumentFlag.DELETED)) {
Logger.log("Successfully replicated a deleted document");
}
}
});
repl.start();
thisReplicator = repl;
token.remove();
}
public void replicationPendingDocumentsExample(Collection collection)
throws CouchbaseLiteException, URISyntaxException {
Replicator repl = new Replicator(
new ReplicatorConfiguration(new URLEndpoint(new URI("ws://localhost:4984/mydatabase")))
.addCollection(collection, null)
.setType(ReplicatorType.PUSH));
Set<String> pendingDocs = repl.getPendingDocumentIds(collection);
if (!pendingDocs.isEmpty()) {
Logger.log("There are " + pendingDocs.size() + " documents pending");
final String firstDoc = pendingDocs.iterator().next();
repl.addChangeListener(change -> {
Logger.log("Replicator activity level is " + change.getStatus().getActivityLevel());
try {
if (!repl.isDocumentPending(firstDoc, collection)) {
Logger.log("Doc ID " + firstDoc + " has been pushed");
}
}
catch (CouchbaseLiteException err) {
Logger.log("Failed getting pending docs", err);
}
});
repl.start();
this.thisReplicator = repl;
}
}
public void databaseReplicatorExample(@NonNull Set<Collection> srcCollections, @NonNull Database targetDb) {
// This is an Enterprise feature:
// the code below will generate a compilation error
// if it's compiled against CBL Android Community Edition.
// Note: the target database must already contain the
// source collections or the replication will fail.
final Replicator repl = new Replicator(
new ReplicatorConfiguration(new DatabaseEndpoint(targetDb))
.addCollections(srcCollections, null)
.setType(ReplicatorType.PUSH));
// Start the replicator
// (be sure to hold a reference somewhere that will prevent it from being GCed)
repl.start();
thisReplicator = repl;
}
public void replicationWithCustomConflictResolverExample(Set<Collection> srcCollections, URI targetUri) {
Replicator repl = new Replicator(
new ReplicatorConfiguration(new URLEndpoint(targetUri))
.addCollections(
srcCollections,
new CollectionConfiguration()
.setConflictResolver(new LocalWinConflictResolver())));
// Start the replicator
// (be sure to hold a reference somewhere that will prevent it from being GCed)
repl.start();
thisReplicator = repl;
}
}If your query selects ALL then the JSON format will be:
{
database-name: {
key1: "value1",
keyx: "valuex"
}
}If your query selects a sub-set of available properties then the JSON format will be:
{
key1: "value1",
keyx: "valuex"
}Predictive Query
|
Enterprise Edition only
Predictive Query is an Enterprise Edition feature.
|
Predictive Query enables Couchbase Lite queries to use machine learning, by providing query functions that can process document data (properties or blobs) via trained ML models.
Let’s consider an image classifier model that takes a picture as input and outputs a label and probability.
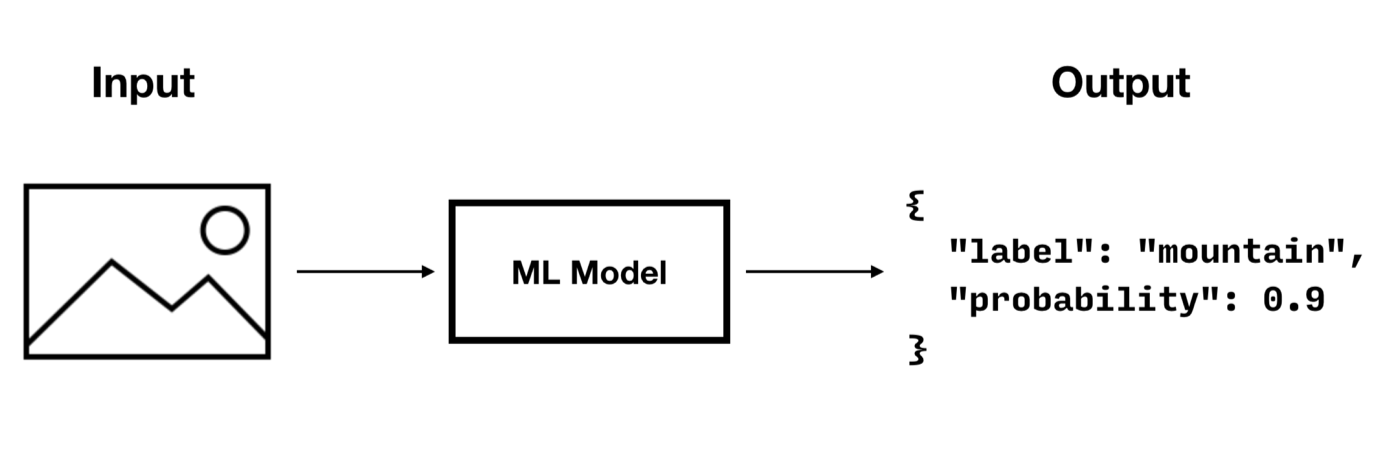
To run a predictive query with a model as the one shown above, you must implement the following steps.
Integrate the Model
To integrate a model with Couchbase Lite, you must implement the PredictiveModel interface which has only one function called predict() — see: Example 29.
class ImageClassifierModel implements PredictiveModel {
@Override
public Dictionary predict(@NonNull Dictionary input) {
Blob blob = input.getBlob("photo");
if (blob == null) { return null; }
// tensorFlowModel is a fake implementation
// this would be the implementation of the ml model you have chosen
return new MutableDictionary(TensorFlowModel.predictImage(blob.getContent())); (1)
}
}
@SuppressWarnings({"unused", "ConstantConditions"})
class ZipUtils {
public static void unzip(InputStream src, File dst) throws IOException {
byte[] buffer = new byte[1024];
try (InputStream in = src; ZipInputStream zis = new ZipInputStream(in)) {
ZipEntry ze = zis.getNextEntry();
while (ze != null) {
File newFile = new File(dst, ze.getName());
if (ze.isDirectory()) { newFile.mkdirs(); }
else {
new File(newFile.getParent()).mkdirs();
try (FileOutputStream fos = new FileOutputStream(newFile)) {
int len;
while ((len = zis.read(buffer)) > 0) { fos.write(buffer, 0, len); }
}
}
ze = zis.getNextEntry();
}
zis.closeEntry();
}
}
}
@SuppressWarnings("unused")
class LogTestLogger implements com.couchbase.lite.Logger {
@NonNull
private final LogLevel level;
public LogTestLogger(@NonNull LogLevel level) { this.level = level; }
@NonNull
@Override
public LogLevel getLevel() { return level; }
@Override
public void log(@NonNull LogLevel level, @NonNull LogDomain domain, @NonNull String message) {
}
}
@SuppressWarnings("unused")
class TensorFlowModel {
public static Map<String, Object> predictImage(byte[] data) {
return null;
}
}
// tensorFlowModel is a fake implementation
// this would be the implementation of the ml model you have chosen
public static class TensorFlowModel {
public static Map<String, Object> predictImage(byte[] data) {
return null;
}
}
public static class ImageClassifierModel implements PredictiveModel {
@Override
public Dictionary predict(@NonNull Dictionary input) {
Blob blob = input.getBlob("photo");
// tensorFlowModel is a fake implementation
// this would be the implementation of the ml model you have chosen
return (blob == null)
? null
: new MutableDictionary(TensorFlowModel.predictImage(blob.getContent())); (1)
}
}| 1 | The predict(input) -> output method provides the input and expects the result of using the machine learning model.
The input and output of the predictive model is a DictionaryObject.
Therefore, the supported data type will be constrained by the data type that the DictionaryObject supports. |
Register the Model
To register the model you must create a new instance and pass it to the Database.prediction.registerModel static method.
Database.prediction.registerModel("ImageClassifier", new ImageClassifierModel());Create an Index
Creating an index for a predictive query is highly recommended. By computing the predictions during writes and building a prediction index, you can significantly improve the speed of prediction queries (which would otherwise have to be computed during reads).
There are two types of indexes for predictive queries:
Value Index
The code below creates a value index from the "label" value of the prediction result. When documents are added or updated, the index will call the prediction function to update the label value in the index.
collection.createIndex(
"value-index-image-classifier",
IndexBuilder.valueIndex(ValueIndexItem.expression(Expression.property("label"))));Predictive Index
Predictive Index is a new index type used for predictive query. It differs from the value index in that it caches the predictive results and creates a value index from that cache when the predictive results values are specified.
Here we create a predictive index from the label value of the prediction result.
Map<String, Object> inputMap = new HashMap<>();
inputMap.put("numbers", Expression.property("photo"));
Expression input = Expression.map(inputMap);
PredictiveIndex index = IndexBuilder.predictiveIndex("ImageClassifier", input, null);
collection.createIndex("predictive-index-image-classifier", index);Run a Prediction Query
The code below creates a query that calls the prediction function to return the "label" value for the first 10 results in the database.
Map<String, Object> inputProperties = new HashMap<>();
inputProperties.put("photo", Expression.property("photo"));
Expression input = Expression.map(inputProperties);
PredictionFunction prediction = Function.prediction("ImageClassifier", input); (1)
Query query = QueryBuilder
.select(SelectResult.all())
.from(DataSource.collection(collection))
.where(Expression.property("label").equalTo(Expression.string("car"))
.and(prediction.propertyPath("probability").greaterThanOrEqualTo(Expression.doubleValue(0.8))));
// Run the query.
try (ResultSet result = query.execute()) {
Logger.log("Number of rows: " + result.allResults().size());
}| 1 | The PredictiveModel.predict() method returns a constructed Prediction Function object which can be used further to specify a property value extracted from the output dictionary of the PredictiveModel.predict() function.
|