Backup Service
The Backup Service schedules full and incremental data backups and merges of previous data-backups.
Overview
The Backup Service lets you schedule full and incremental data backups for individual buckets or for all buckets in the cluster. It supports backing up both Couchbase and Ephemeral buckets. The Backup Service also supports scheduled merges of previous backups. You can choose what data to back up by service. For example, you can choose to back up the data for just the Data and Index Services.
You can configure and administer the Backup Service using the Couchbase Server Web Console, the command-line tools, or the REST API.
The Backup Service and cbbackupmgr
The Backup Service uses the cbbackupmgr command-line tool to perform backups.
You can also directly use this tool to perform backups and merges.
Either backup method lets you perform incremental backups and merge incremental backups to deduplicate data.
They use the same backup archive structure.
You can list the contents of backed up data and search for specific documents no matter how you back up the data.
When choosing whether to use the Backup Service or to directly call cbbackupmgr, consider these differences between these methods:
-
The Backup Service backs up, restores, and archives buckets only on the cluster it runs on. You can use
cbbackupmgrto backup, restore, and archive buckets on either the local or a remote cluster. -
The Backup Service lets you perform backup, restore, and archive tasks on a regular schedule. Calling
cbbackupmgrruns a backup, restore, or archive task a single time. To use it on a regular schedule, you must rely on an external scheduling system such ascron.
See cbbackupmgr for more information about using the command-line tool.
Backup Service Architecture
When there are multiple Backup Service nodes in the cluster, the Cluster Manager elects one of them to be the leader. The leader is responsible for:
-
Dispatching backup tasks.
-
Adding and removing nodes from the Backup Service.
-
Cleaning orphaned tasks.
-
Ensuring that all Backup Service nodes can reach the global storage locations.
If the leader becomes unresponsive or fails over, the Backup Service stops until a rebalance takes place. During the rebalance, the Cluster Manager elects a new leader. The Backup Service then resumes running on the surviving Backup Service nodes.
Plans
To automate backups using the Backup Service, you must create a plan that tells the service what you want it to do. A plan contains the following information:
-
The data to back up.
-
Where to store the backup. You associate a plan with a repository where it stored backup data (see the next section).
-
The schedule for the Backup Service to run backup tasks.
-
The type of backup to perform. Backups can be full or incremental. In addition to just backing up data, a backup task can also merge backups.
Repositories
A repository is a location where the Backup Service can store backup data. You associate a repository with a plan. You must set several options to define the repository, including:
-
Whether the repository is for all buckets, or a specific bucket.
-
Whether the repository is in
filesystemorcloudstorage. -
The repository’s location—a path for filesystem repositories or the cloud provider details plus a local staging directory for cloud repositories. All nodes in the cluster must be able to access the repository location.
Once you define the repository, the Backup Service performs backups and optionally merges of the data in the bucket or buckets on the schedule in the plan.
The cbbackupmgr tool takes a lock on the repository to which it’s backing up data.
This lock can cause Backup Service tasks to fail if they attempt to back up data to the repository.
If you see backup tasks failing due to lock issues, a common cause is that a cbbackupmgr task (either one started directory or by the Backup Service) is using the repository.
|
Inspecting and Restoring
After the Backup Service has backed up data, you can inspect it in several ways. You can view the history of backups the Backup Service has performed in a repository. You can also search the repositories for individual documents that have been backed up.
When restoring data from a backup, you can define filters to choose a subset of the data to restore. You can restore data to its original keyspace or apply a mapping to restore it to a different keyspace.
You do not have to restore backed up data to a bucket using the same storage engine as the original bucket. For example, you can restore data backed up from a bucket that used the Couchstore storage engine to a bucket using Magma.
Archiving and Importing
If you no longer need a repository to perform backups, you can archive it. You can still read the backed-up data in an archived repository. However, the Backup Service cannot perform further backups to the repository.
If you delete a repository but do not delete the data it contains, you can import the data back into the cluster. After importing the data, you can read the data, but as with archived repositories, the Backup Service cannot write backups to it.
Avoiding Task Overlap
The Backup Service allows you to schedule automated tasks at intervals as small as one minute. However, you should be cautious about using intervals under fifteen minutes. You must make sure the interval is large enough to allow each task enough time to finish before the next task is scheduled to start.
Several conditions can cause a backup task to take longer than expected. Having many backups in the same repository can make the process of populating the backup’s staging directory slower. Spikes in network latency can also cause a backup to take longer than usual.
The Backup Service runs only a single task at a time. If another instance a task is scheduled to start while a previous instance is still running, the Backup Service refuses to start the new instance. Instead, the instance of the task fails to start. If a backup task is scheduled to start while a different task is already running, the Backup Service queues the new task until the existing task finishes.
A backup task can also fail if the underlying cbbackupmgr process it calls to perform the backup fails.
When run directly or by a Backup Service task, the cbbackupmgr tool takes a lock on the repository into which it’s backing up data.
This lock prevents any other instance of the cbbackupmgr tool to storing data into the repository.
If the instance of cbbackupmgr started by a Backup Service task exits due to a lock on its repository, the backup task fails.
For example, suppose you have a repository whose plan defines two tasks named TaskA and TaskB:
-
If a new instance of TaskA is scheduled to start while a prior instance of TaskA is still running, the Backup Service does not start the new instance of TaskA.
-
If there’s a single Backup Service node and TaskB is scheduled to start while an instance of TaskA is still running, the Backup Service places TaskB in a queue until TaskA ends.
-
If TaskB is scheduled to start while an instance of TaskA is still running on a cluster with multiple Backup-Service nodes, TaskB fails. In this case, the Backup Service passes a new instance of TaskB to the Backup Service on a different node from the one that’s running TaskA. This Backup Service node starts TaskB immediately. However, TaskA’s instance of
cbbackupmgrholds a lock on the repository. This lock prevents TaskB’scbbackupmgrprocess from getting a lock on the repository, causing it to fail.
When a task fails to start, the next successful backup task backs up the data it would have backed up.
Choosing the Number of Backup Service Nodes
As explained in the previous section, backup tasks can fail to start if tasks that are already running use the same repository. You have several options to configure your cluster to avoid having backup tasks fail due to these conflicts.
The simplest option is to have a single Backup Service node. This configuration is useful if you have multiple backup tasks that target the same repository. If one task is scheduled to start while another task is running, the Backup Service adds the scheduled task to a queue instead of causing it to fail. One drawback of this configuration is that it reduces resiliency. If the single Backup Service node fails over, then there is no other Backup Service available to handle backups.
If you want greater resiliency for your backups, you can add multiple Backup Service nodes to the cluster. This increases the risk of having backup tasks fail due to overlap if backing up into the same repository.
In either of these cases, you still need to schedule the tasks so that the same task does not overlap with itself.
Setting Merge Offsets
As explained in the Schedule Merges section, the Backup Service lets you set a schedule for automatically merging previous backups. To schedule merges, you define a past time range within which the Backup Service automatically merges backups.
You set this time range by specifying two offsets, each representing a number of days.
The merge_offset_start integer indicates the beginning of the time range and the merge_offset_end indicates its end.
These are offsets from different points in time:
-
merge_offset_startis an offset from today, represented by the integer 0. For example, settingmerge_offset_startto 90 means the start of the merge offset is 90 days ago from today. -
merge_offset_endsets the number of days before the day you selected withmerge_offset_start. For example, suppose you setmerge_offset_startto 90 and setmerge_offset_endto 30. Then the end of the offset is 120 days before today because 90 + 30 = 120.
The following diagram shows two examples of settings offsets:
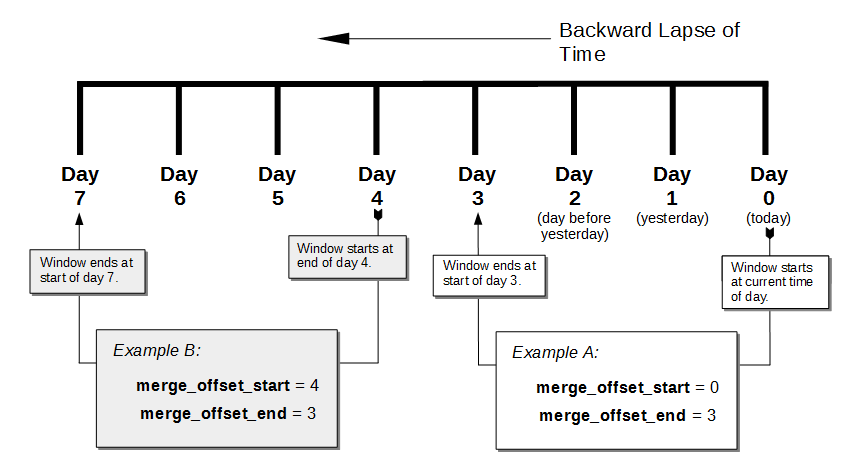
In this diagram, days are numbered from right to left, with today as 0, yesterday as 1, the day before yesterday as 2, and so on. The choice of eight days in the diagram is arbitrary. The Backup Service does not limit the size of the integer when setting the time range.
The diagram contains two examples:
-
Example A sets
merge_offset_startto 0 (today) andmerge_offset_endto 3 (three days before today). If today is June 30, the time range is from June 30 to June 27. The end of the range includes the entire last day. When you use 0 to indicate today, the range starts from the time the scheduled merge process begins running. -
Example B sets
merge_offset_startto 4 (four days before today) andmerge_offset_endto 3 (7 days ago, which is three days before the specifiedmerge_offset_start). Therefore, if today is March 15, the time range is from March 11 to March 8, with both the start and end days included entirely.
Thread Usage Couchbase Server 7.6.2
By default, the Backup Service chooses the number of threads it uses based on the number of CPU cores in the node. The Backup Service creates one client connection per thread to connect in parallel to nodes when retrieving their data. The more threads the service uses, the faster it retrieves data. The formula for the number of threads it uses is \(\max(1, cpu\_cores \times 0.75)\) (\(\frac{3}{4}\) the number of CPU cores in the system or 1, whichever is larger).
In some cases, you may find that the default number of threads the Backup Service is using is too high.
Depending on resources, a large number of threads can cause performance issues or out-of-memory errors.
If your cluster is experiencing these issues during backup, you can change the number of threads a Backup Service node uses.
You change this setting using the nodesThreadsMap REST API endpoint.
See Manage Backup Service Threads for details on setting the number of threads the Backup Service uses.
Reducing the number of threads the Backup Service uses increases the time it takes to backup data. You may want to experiment with different thread settings to find a balance between resource use and backup duration for your cluster.
See Also
-
See Manage Backup and Restore to learn how to configure the Backup Service with the Couchbase Web Console.
-
See Backup Service API for information about using the Backup Service from the REST API.
-
To learn about the port numbers the Backup Service uses, see Couchbase Server Ports.
-
For a list of Backup Service audit events, see Audit Event Reference.