UPSERT INTO Statements
- Capella Analytics
- reference
This topic describes how you use UPSERT INTO statements to insert and update objects in a standalone collection.
If any of the objects you’re adding has the same primary key as an object that’s already in the standalone collection, Capella Analytics replaces the existing object’s values with the new object’s values.
Syntax
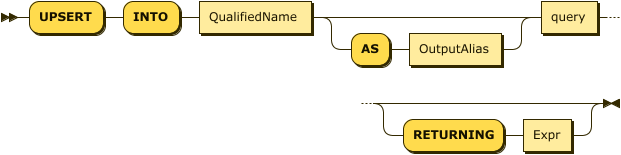
UpsertInto EBNF
UpsertInto ::= "UPSERT" "INTO" QualifiedName
("AS" OutputAlias)?
query ("RETURNING" Expr)?UpsertInto Diagram
Examples
The following example uses an UPSERT INTO statement to both insert a new order, 1010, into the sampleAnalytics.Commerce.orders collection and update existing order 1009 with more information.
Optionally, you can review the contents of the collection before and after you do the upsert to compare the results: SELECT * from sampleAnalytics.Commerce.orders LIMIT 10;
UPSERT INTO sampleAnalytics.Commerce.orders (
{
"orderno": 1010,
"custid": "C51",
"order_date": "2020-11-04",
"ship_date": "2020-11-08",
"items": [
{
"itemno": 410,
"qty": 120,
"price": 88.16
},
{
"itemno": 590,
"qty": 6,
"price": 217.75
}
]
},
{
"orderno": 1009,
"custid": "C13",
"order_date": "2020-10-13",
"items": [
{
"itemno": 460,
"qty": 240,
"price": 99.98
}
]
}
);After you use UPSERT INTO, you can run ANALYZE COLLECTION on the collection to update the data sample used by cost-based optimization (CBO).
See Cost-Based Optimizer for Capella Analytics Services.
Show an additional example
This example begins with two statements that create an external collection for data stored on S3 and a standalone collection.
In this example, the objects in the external collection have a primary key field named my_pk with a data type of string, which you then use as the standalone collection’s primary key.
They’re followed by an UPSERT INTO statement that copies all data from the external location—identified by the defined PATH clause—to the standalone collection as is.
CREATE EXTERNAL COLLECTION my_external_dataset
ON my_s3_bucket
AT my_s3_link
PATH "my/path";
CREATE COLLECTION my_standalone_dataset
PRIMARY KEY (my_pk:string);
UPSERT INTO my_standalone_dataset
SELECT VALUE d
FROM my_external_dataset AS d;Arguments
- RETURNING
-
Adding an optional
RETURNINGclause causes the statement to return a result for each object upserted, identified by theOutputAliasor the collection name. The clause can contain subqueries, although they cannot refer to any collections in their FROM clauses, making them object-local in nature.