List of Architecture Diagrams
A quick reference to some of the architecture diagrams in Couchbase documentation.
Throughout the Couchbase documentation-set, explanations of the architecture of Couchbase Server are supported diagrammatically. Each diagram is co-located with its textual description. This page provides a quick-reference, whereby some of the most important diagrams can be directly accessed.
Diagrams are provided for the following topics. Click on the thumbnails or other links to access the full-size diagrams and accompanying, detailed descriptions.
Multidimensional Scaling
Couchbase Server supports multidimensional scaling, whereby services can be distributed and resourced with the greatest flexibility, across the designated nodes of a cluster.
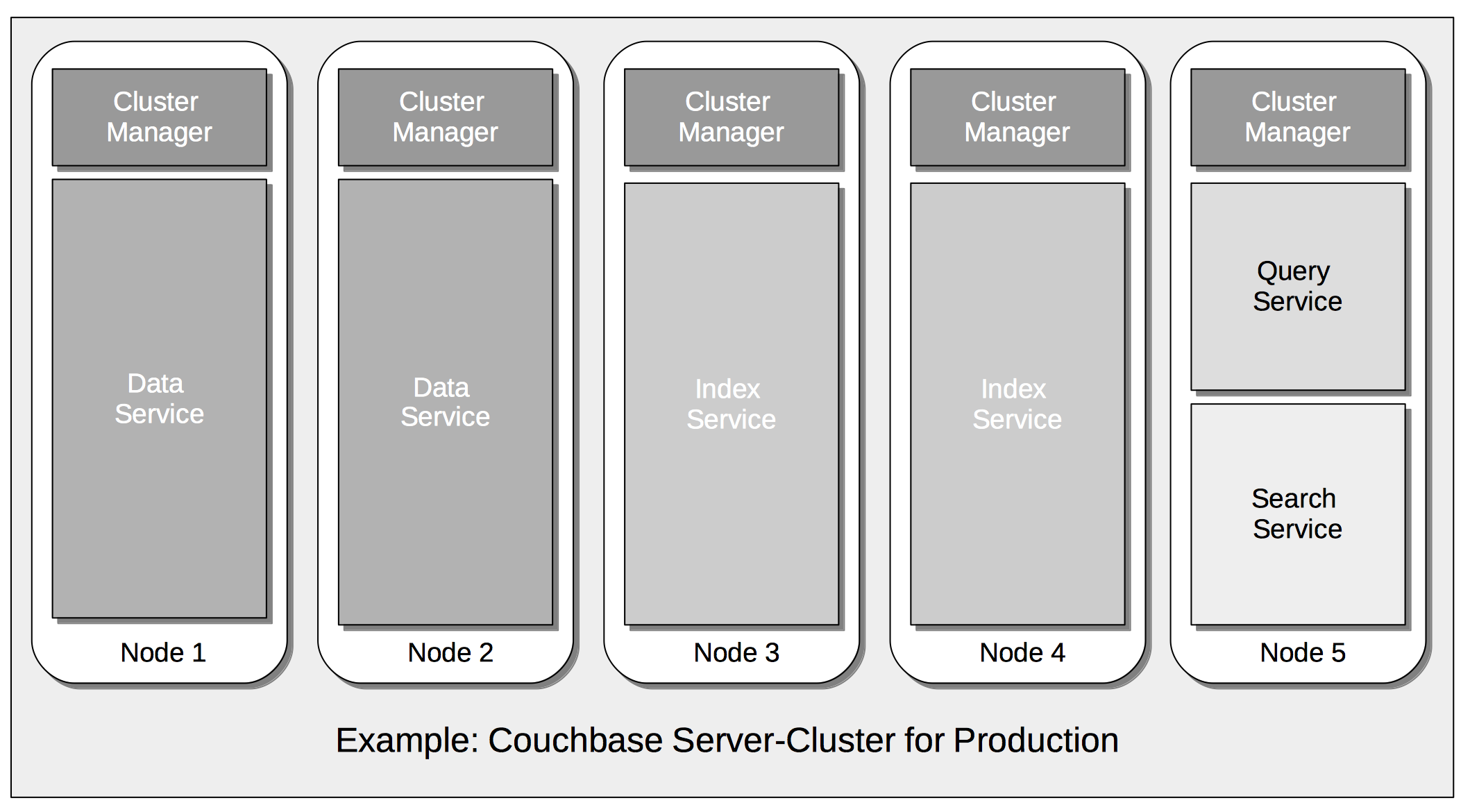
This is explained in Setting Up Services.
Data Service
The Couchbase Data Service is the most fundamental of all Couchbase services, providing access to data in memory and on disk.
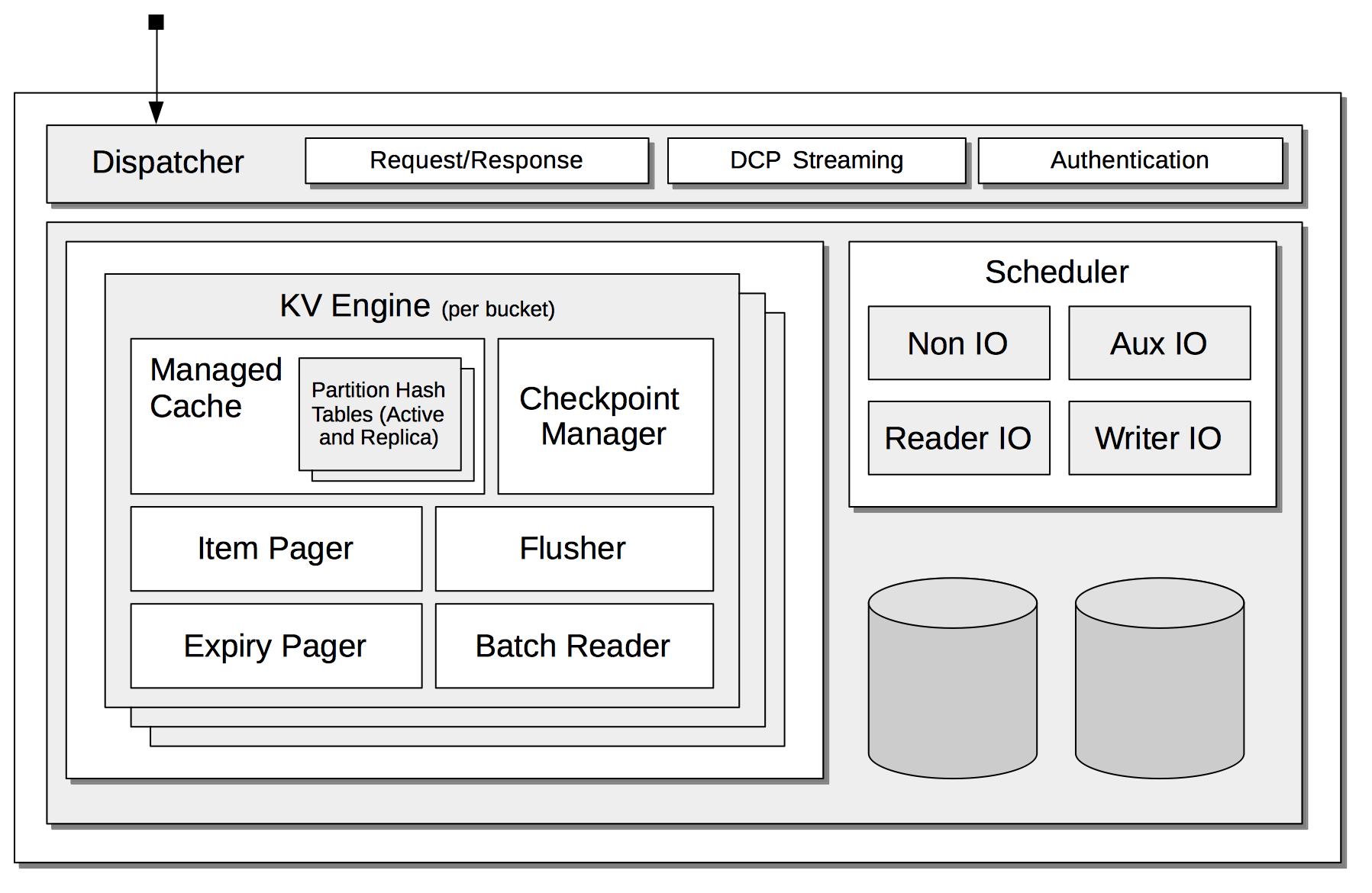
See Data Service for a description of the Data Service' architecture, and the interactions of its inner components.
Data-Service Rebalance Stages
Rebalance redistributes data, indexes, event processing and query processing among available nodes. Data is moved in stages, the progress through which is observable, allowing rates of progress to be determined.
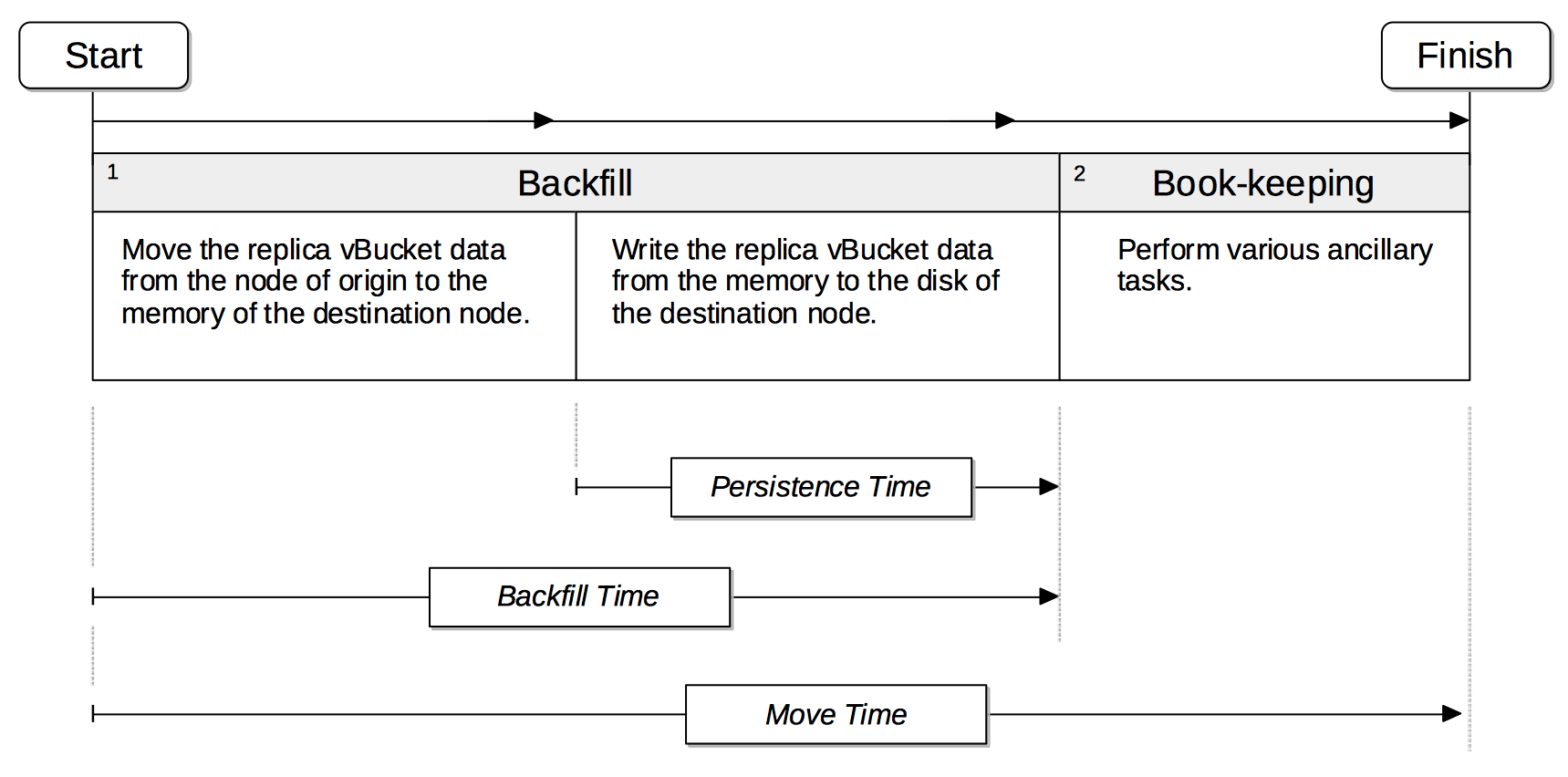
See Rebalance, for an overview of rebalance and its significance to different services.
Durability
Couchbase Server provides durability, which ensures the greatest likelihood of data-writes surviving unexpected anomalies, such as node-outages.
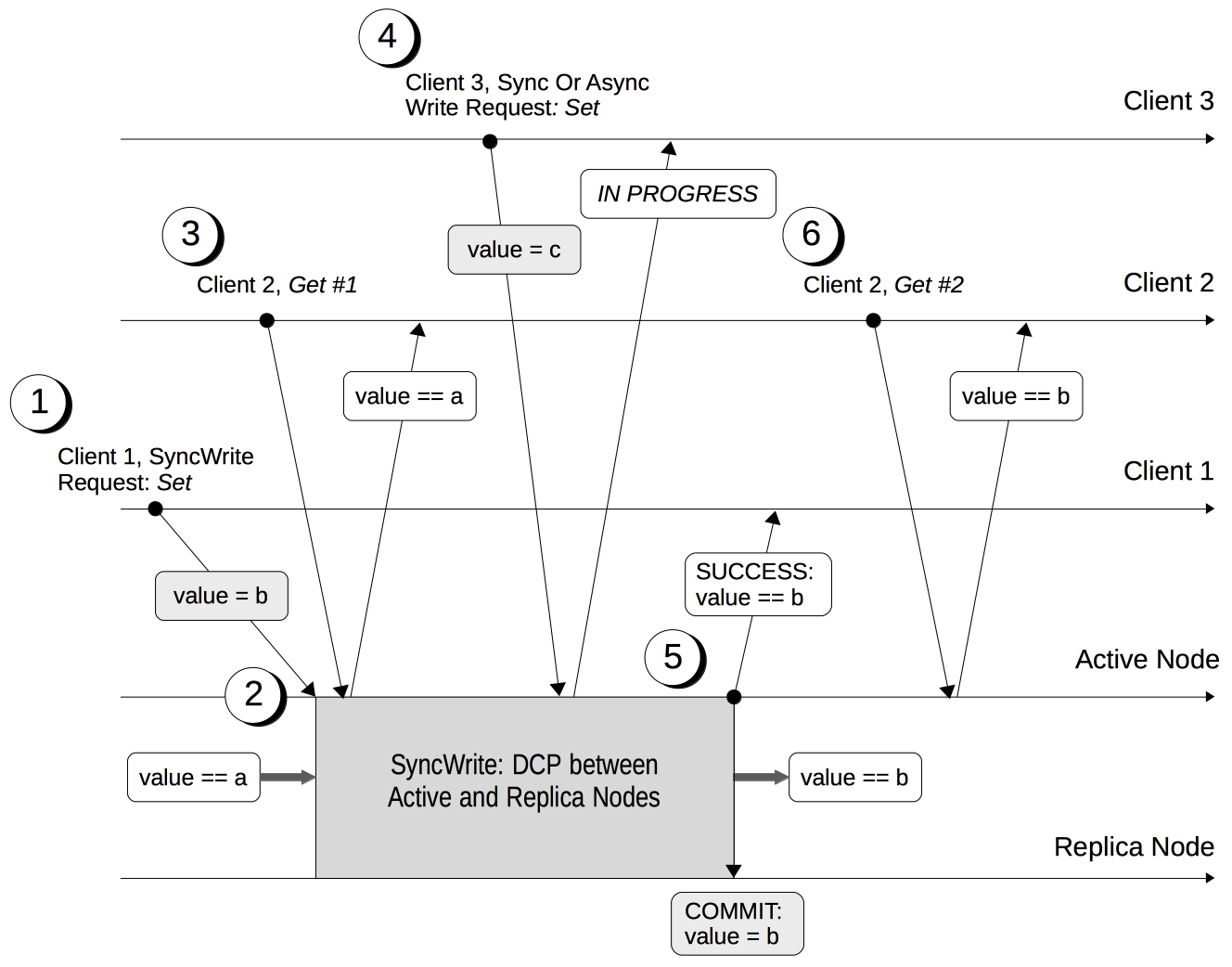
See Durability for a full description, including the protection guarantees provided.
Alternate Addresses
Couchbase Server allows an alternate address to be assigned to any individual cluster-node, and an alternate port number to be assigned to any service running on that node.
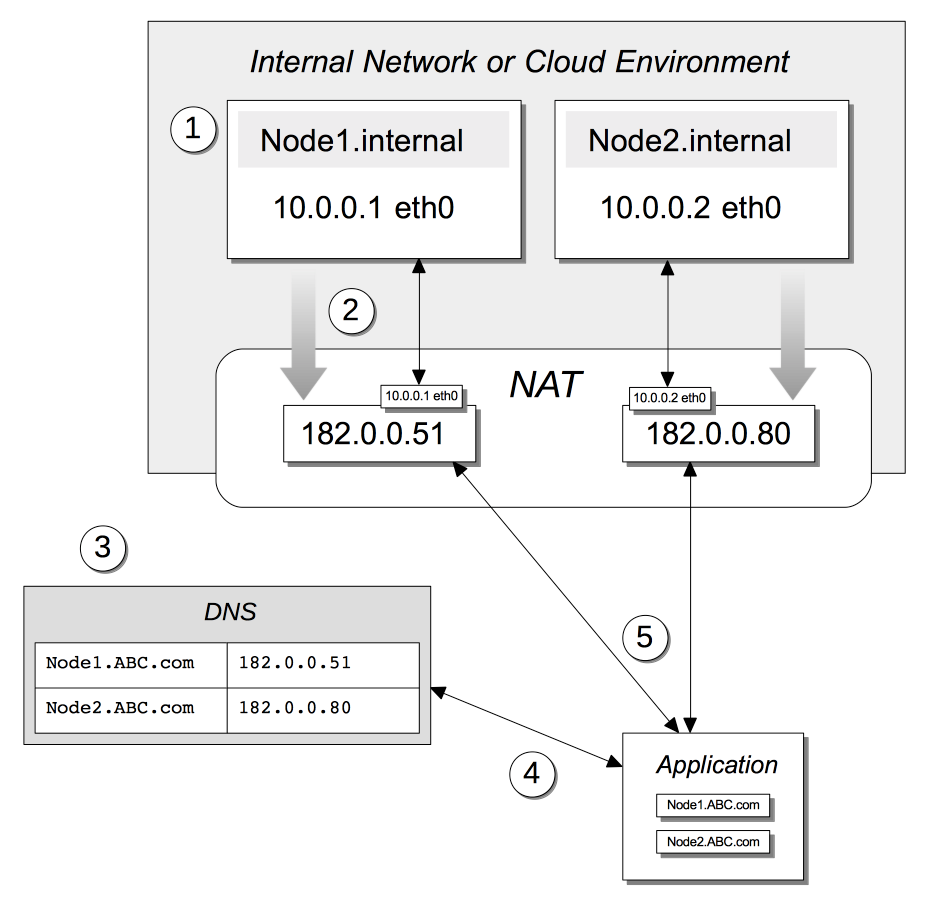
For information on use cases and pointers to procedures for applying alternate addresses, see Alternate Addresses.
Query Service
The Couchbase Query Service supports the querying of data by means of the N1QL query language.
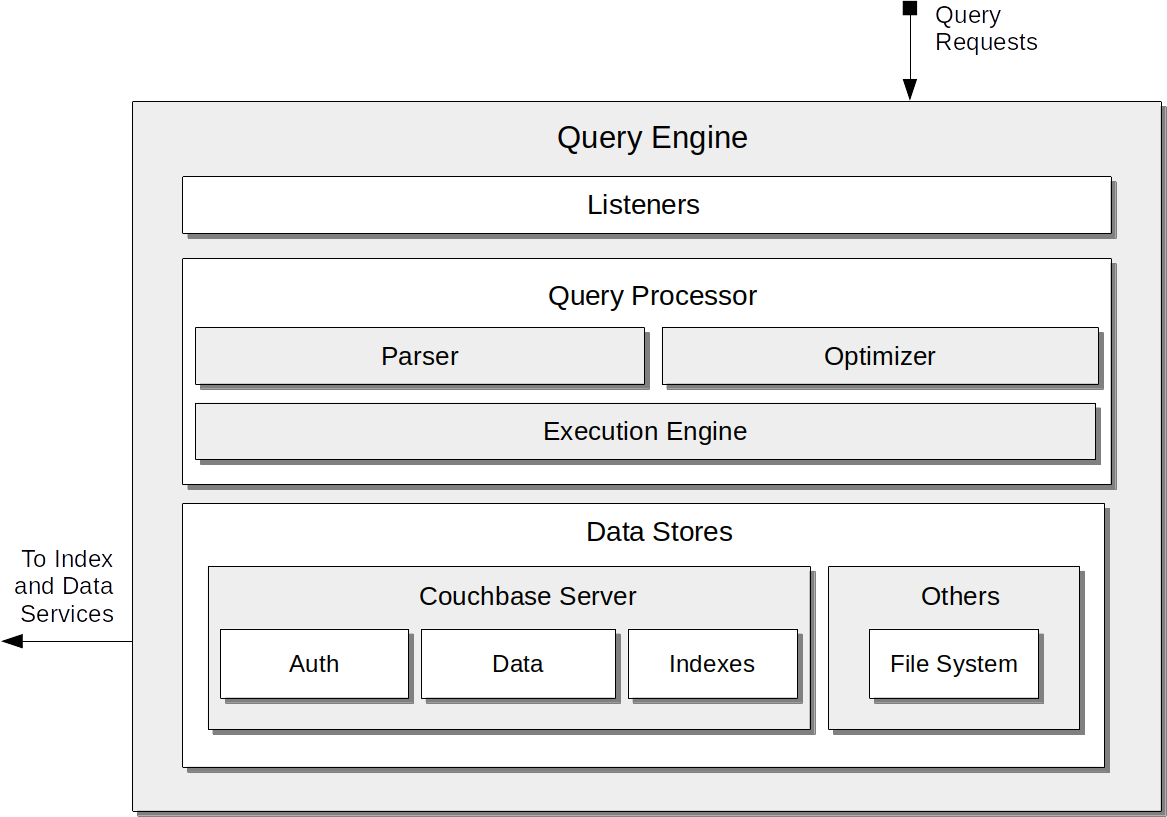
Its architecture and the query processing-sequence it supports are explained in Query Service.
Index Service
The Couchbase Index Service supports the creation of primary and secondary indexes on items stored within Couchbase Server.
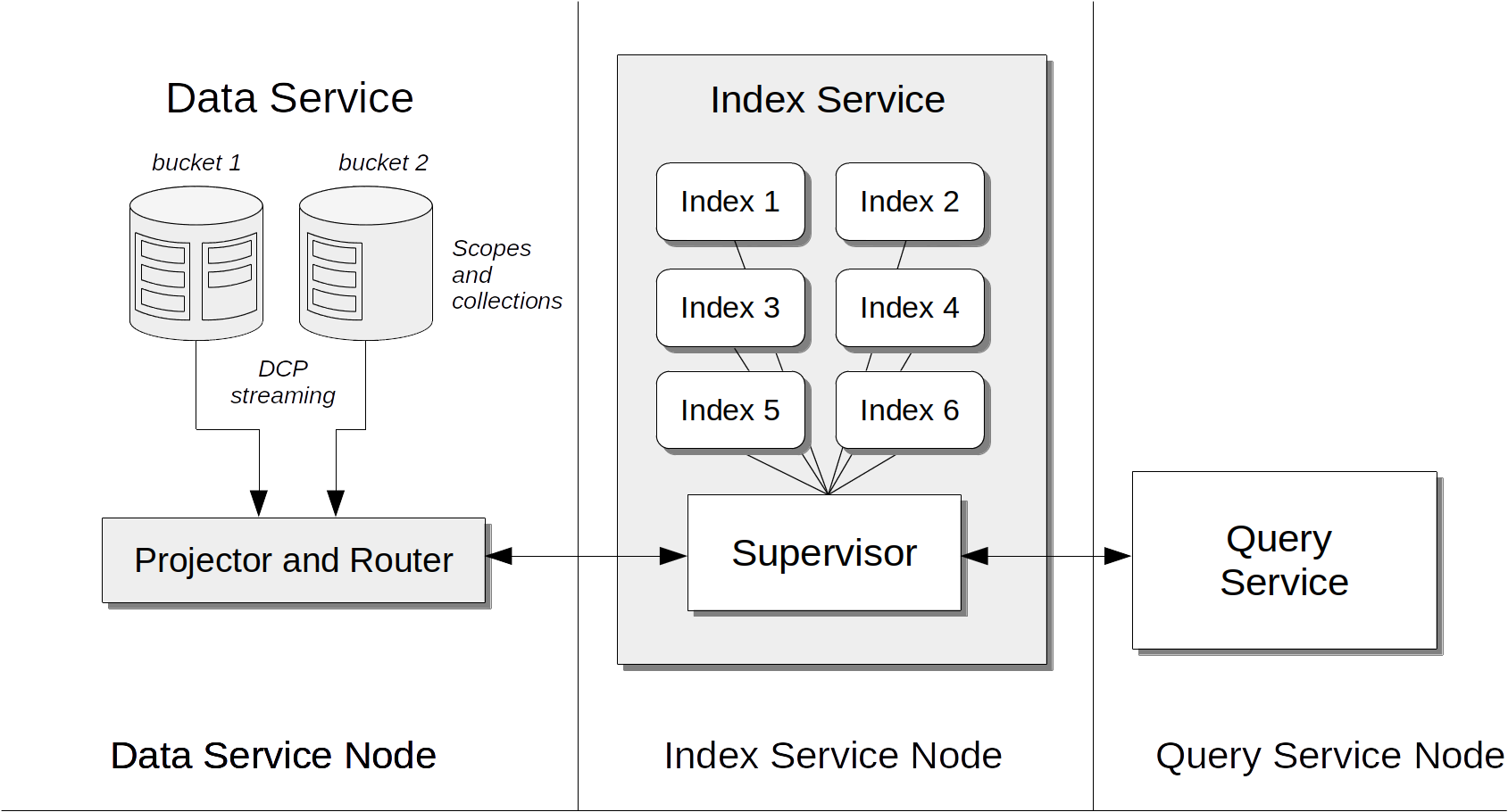
Components essential for the Index Service reside not only on each node to which the Index Service is assigned, but also on each node to which the Data Service is assigned, as shown by the illustration in Index Service.
Search Service
The Couchbase Search Service supports the creation of specially purposed indexes for Full Text Search.
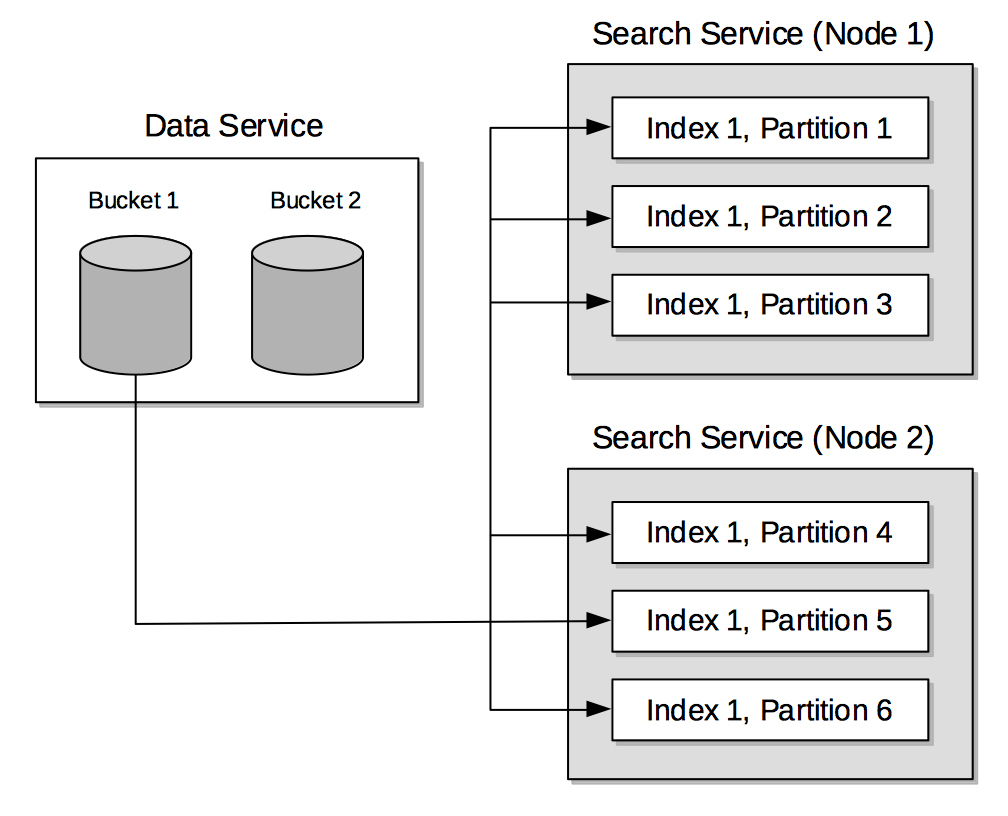
When a Search Index is created by means of the Search Service, its handling of data for the vBuckets is divided equally among the established search-index partitions, as shown by the illustration in Search Service.
Backup Service
The Couchbase Backup Service supports the scheduling of full and incremental data backups, either for specific individual buckets, or for all buckets on the cluster. This includes specifying time windows, for the automated merging of backups that have been previously accomplished.
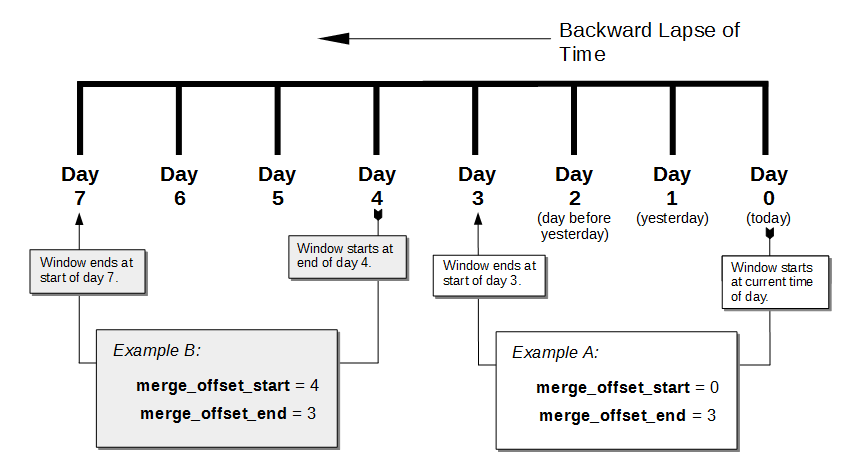
For more information, see Backup Service.
Cluster Manager
The Couchbase Cluster Manager runs on all the nodes of a cluster, maintaining essential per-node processes, and coordinating cluster-wide operations.
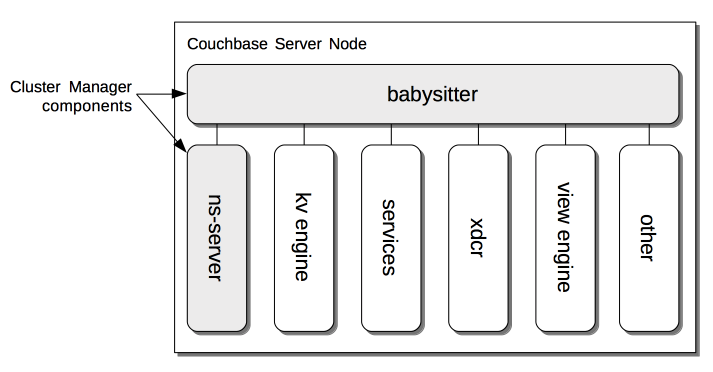
Its architecture is explained in Cluster Manager.
This page also provides a detailed diagram for the most important component of the Cluster Manager, ns-server.
Intra-Cluster Replication
The Couchbase replication architecture keeps cluster-data highly available, by replicating data across the nodes of a cluster, using the Database Change Protocol.
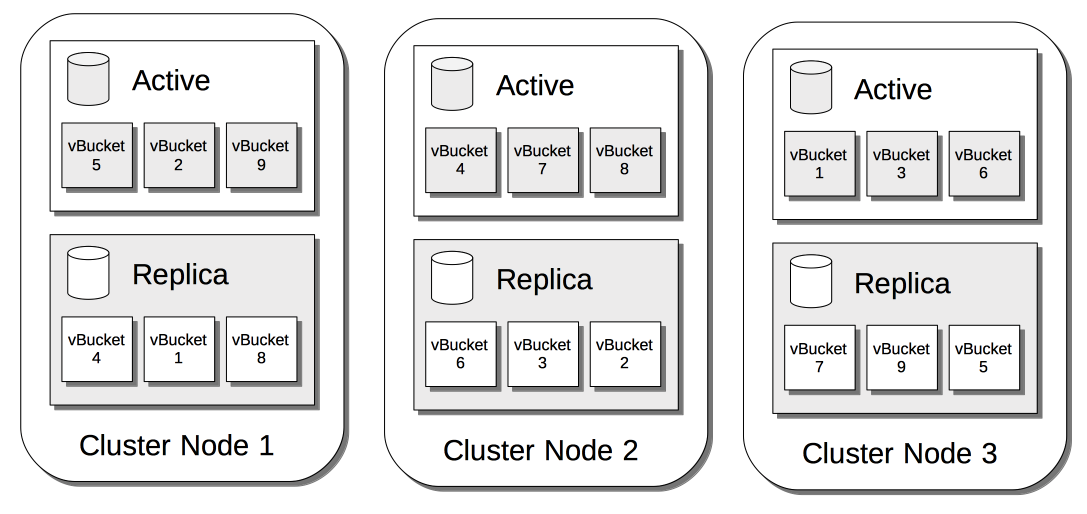
This is explained in Intra-Cluster Replication.
Cross Data Center Replication (XDCR)
Cross Data Center Replication (XDCR) is the process whereby data can be replicated to a remote cluster.
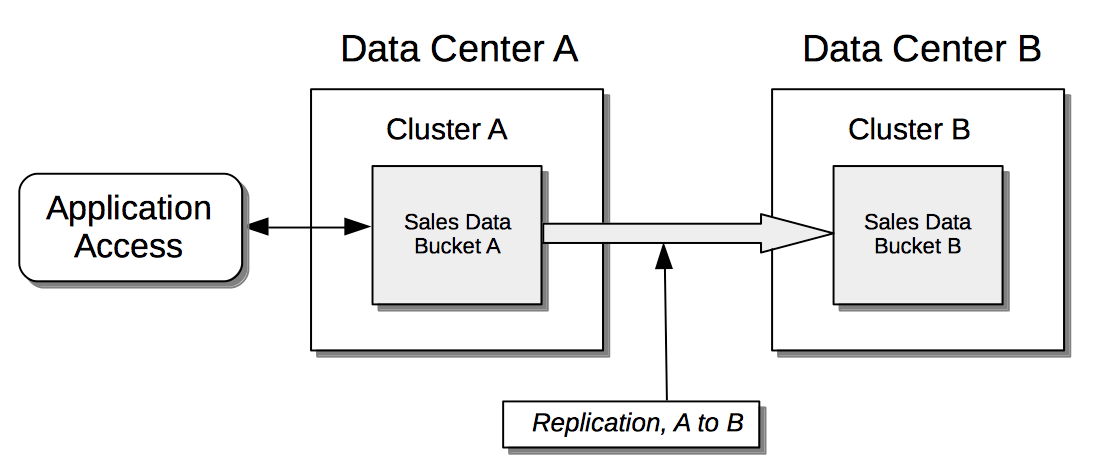
The topographical options for XDCR set-up are shown by the diagrams in XDCR Direction and Topology.
XDCR Advanced Filtering
XDCR Advanced Filtering allows specified subsets of documents to be replicated from the source bucket.
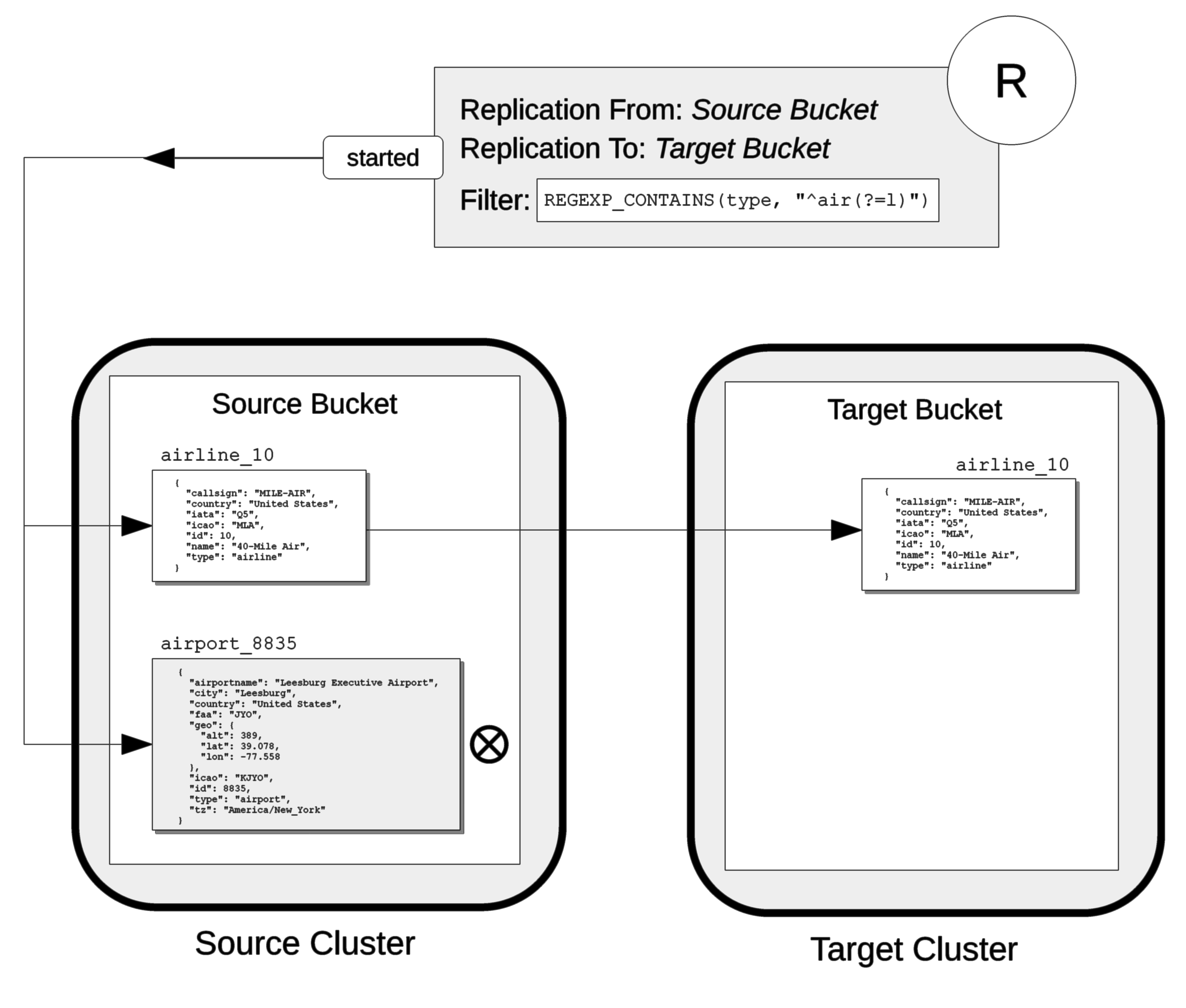
Information on the available options for document-selection is provided in XDCR Advanced Filtering.
XDCR with Scopes and Collections
XDCR allows documents to be mapped between different source and target collections.
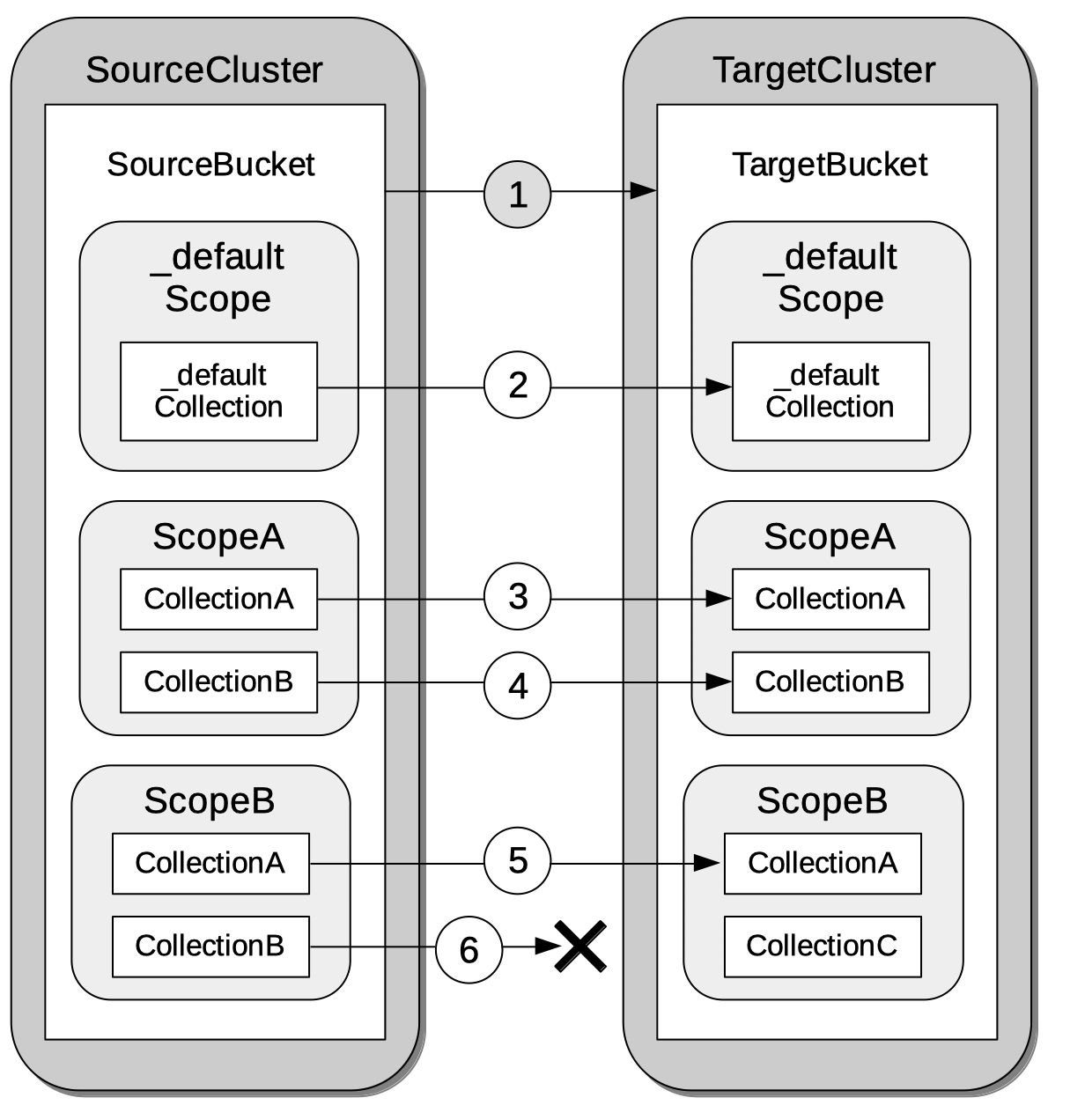
Detailed information is provided in XDCR with Scopes and Collections.
Server Group Awareness
Server Group Awareness allows individual server-nodes to be assigned to specific groups, within a Couchbase Cluster. This allows active vBuckets and indexes to be maintained on groups other than those of their corresponding replica vBuckets and index replicas; so that if a group goes offline, vBuckets and indexes remain available on other groups.
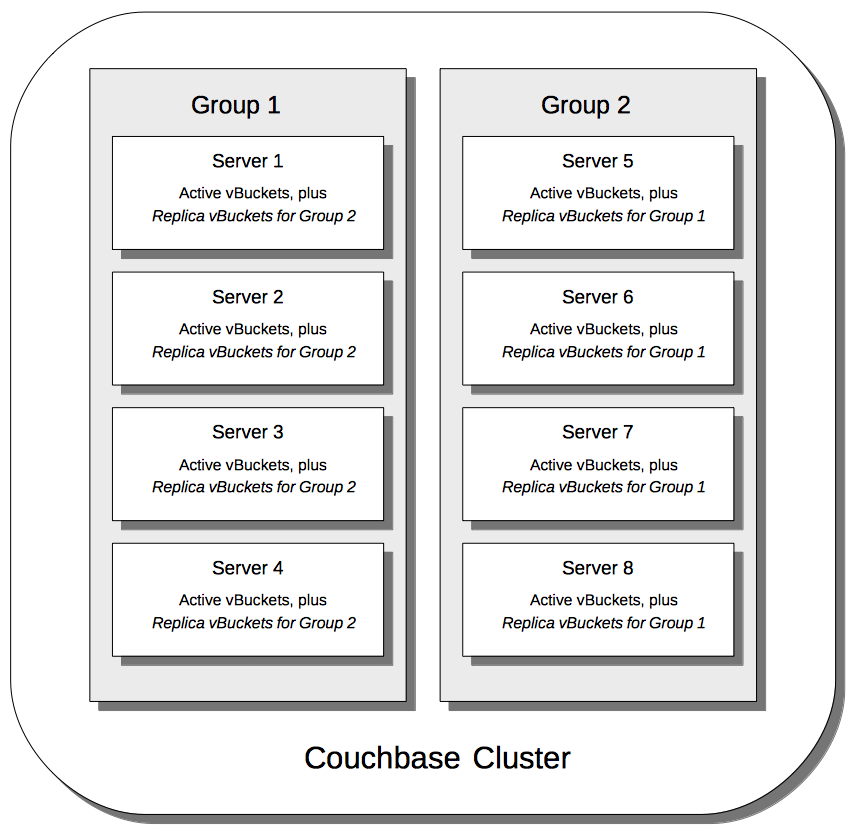
Possible group layouts, and the effects of failover, are illustrated diagrammatically in Server Group Awareness.
Data Size Limits
A data-item stored by Couchbase Server has multiple inner components, each of which has a fixed size limit.
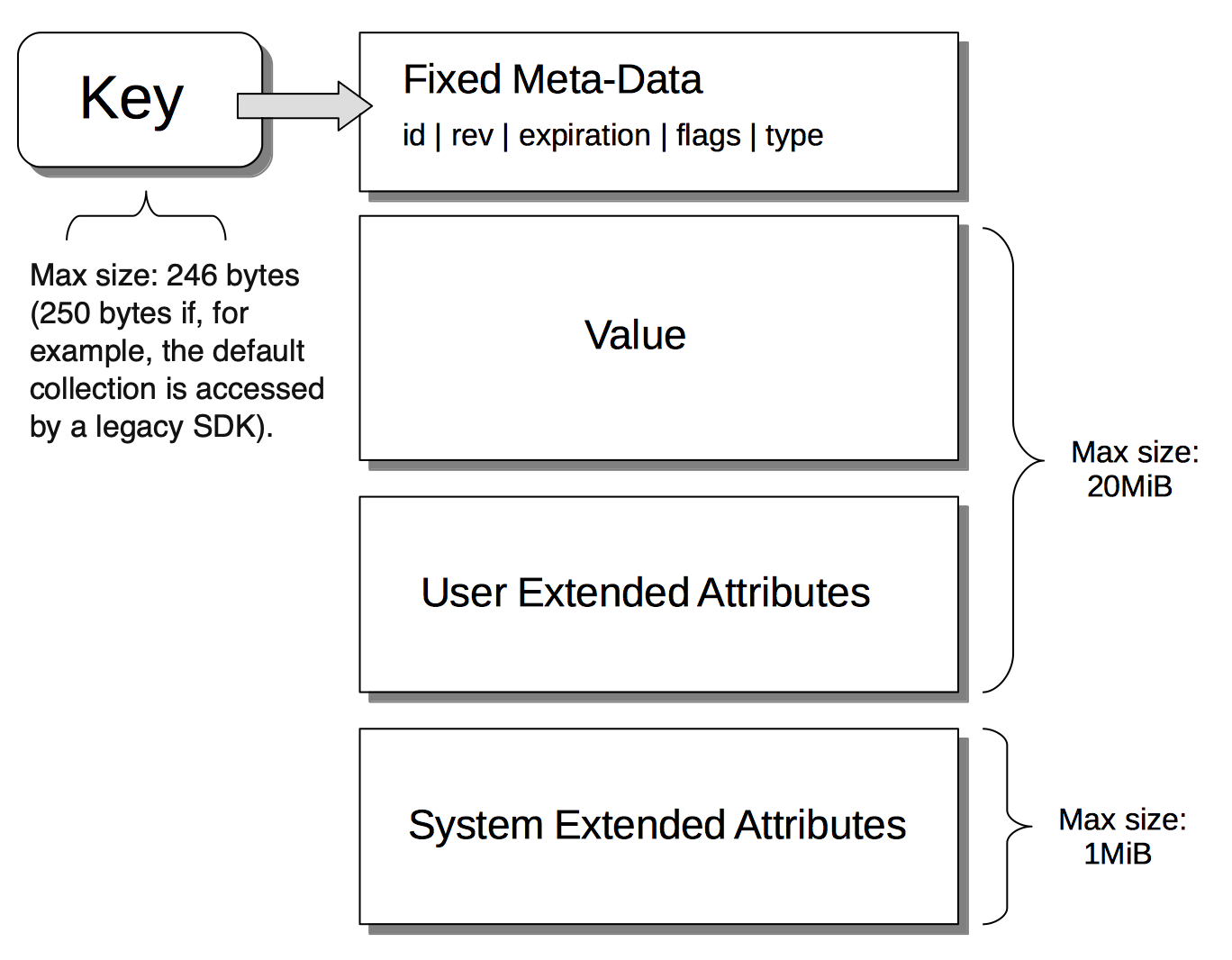
Components and their sizes are described in Data Size Limits.
Data Model
The Couchbase Data Model is based on using JSON documents to store data items.

The Relational and JSON data models have fundamental differences, explained here graphically.
vBuckets
Couchbase buckets, which are used to group data-items logically, are mapped to underlying shards on disk, known as vBuckets.
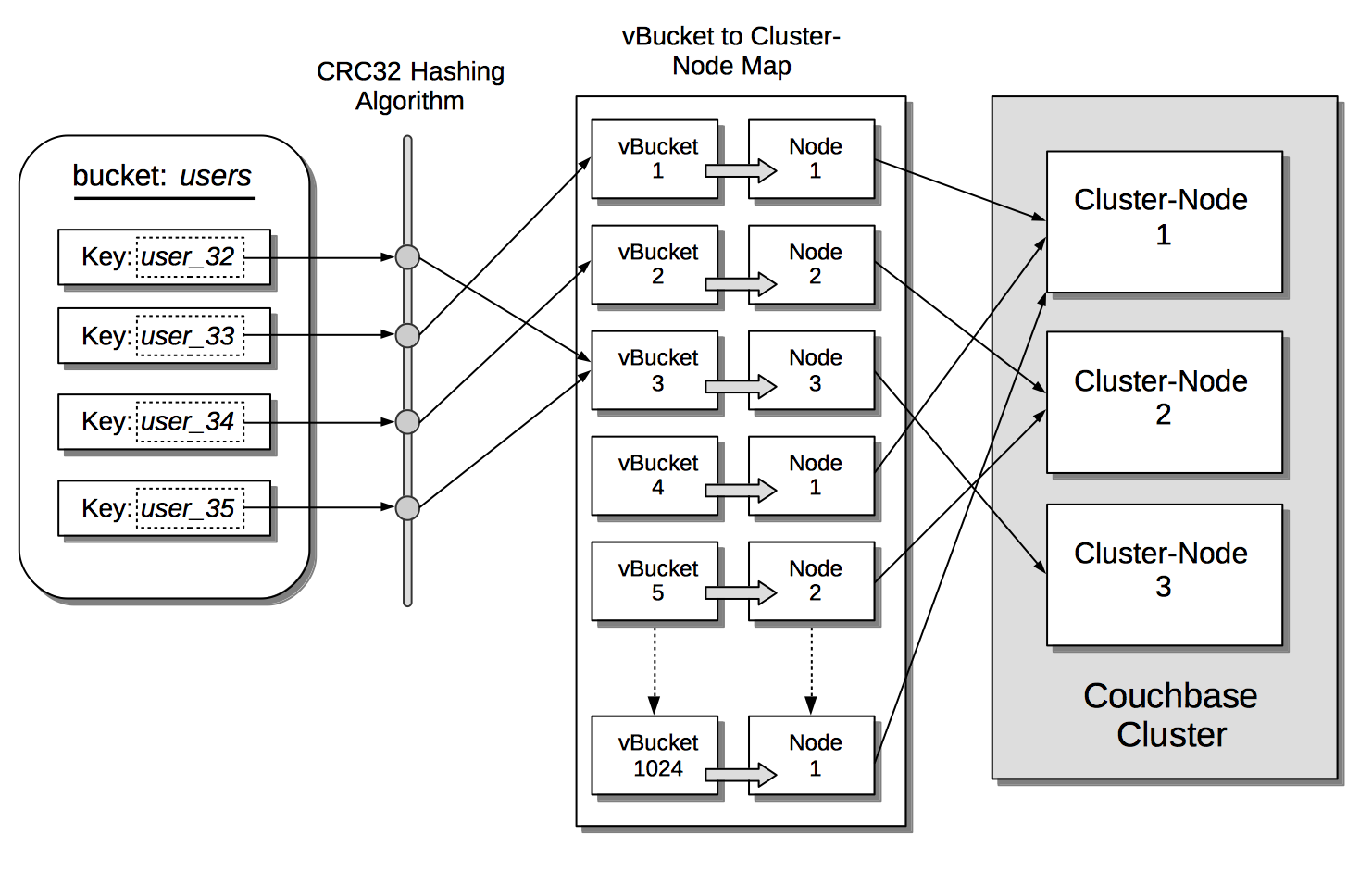
This is explained in Understanding vBuckets.
Compression
Compression is used by Couchbase Server to maximize resources and heighten performance.
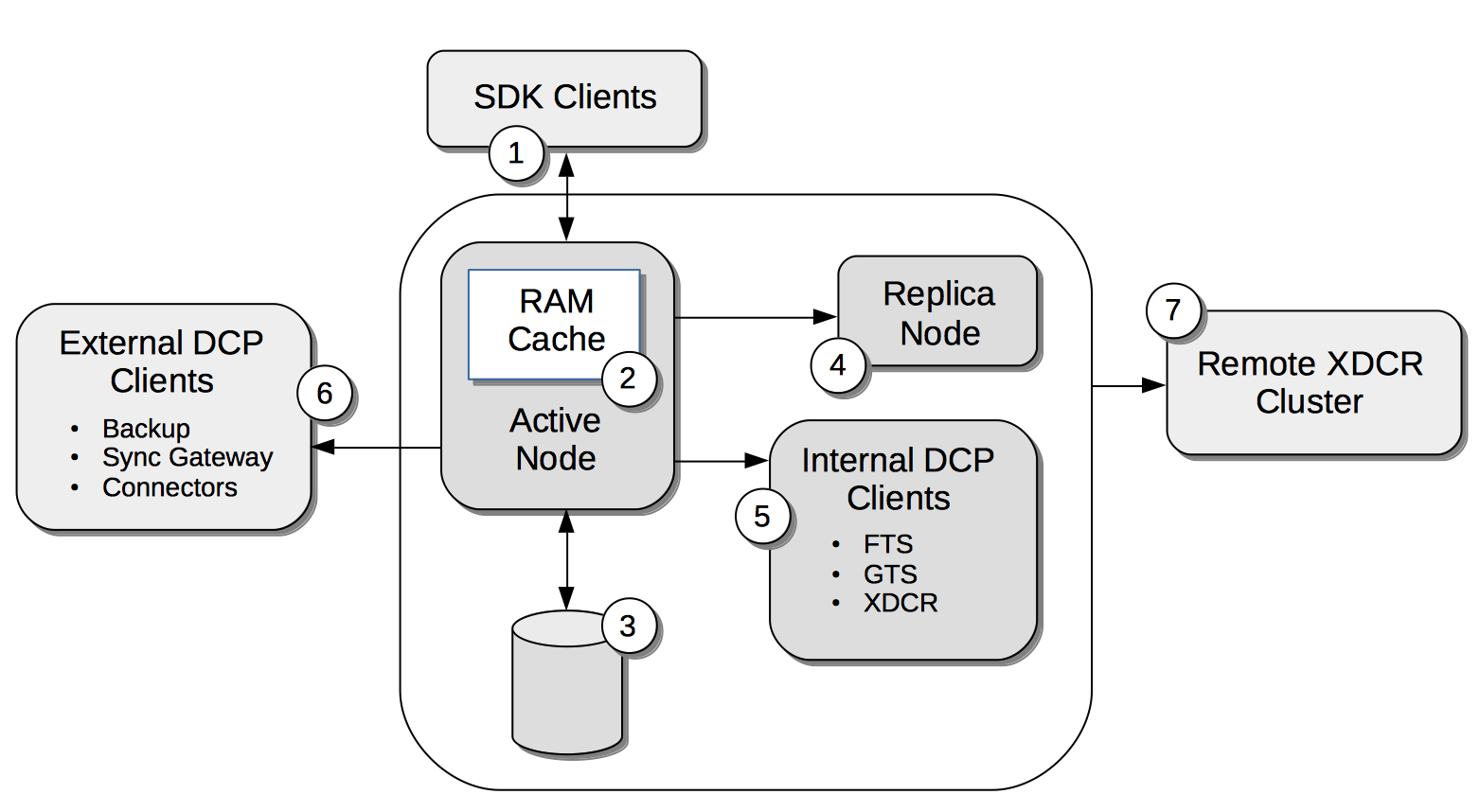
The communication-paths that benefit are listed and explained in Where Compression is Used.
Saving New Items
When Couchbase Server receives new data from a client, it saves to disk, and also replicates across nodes.
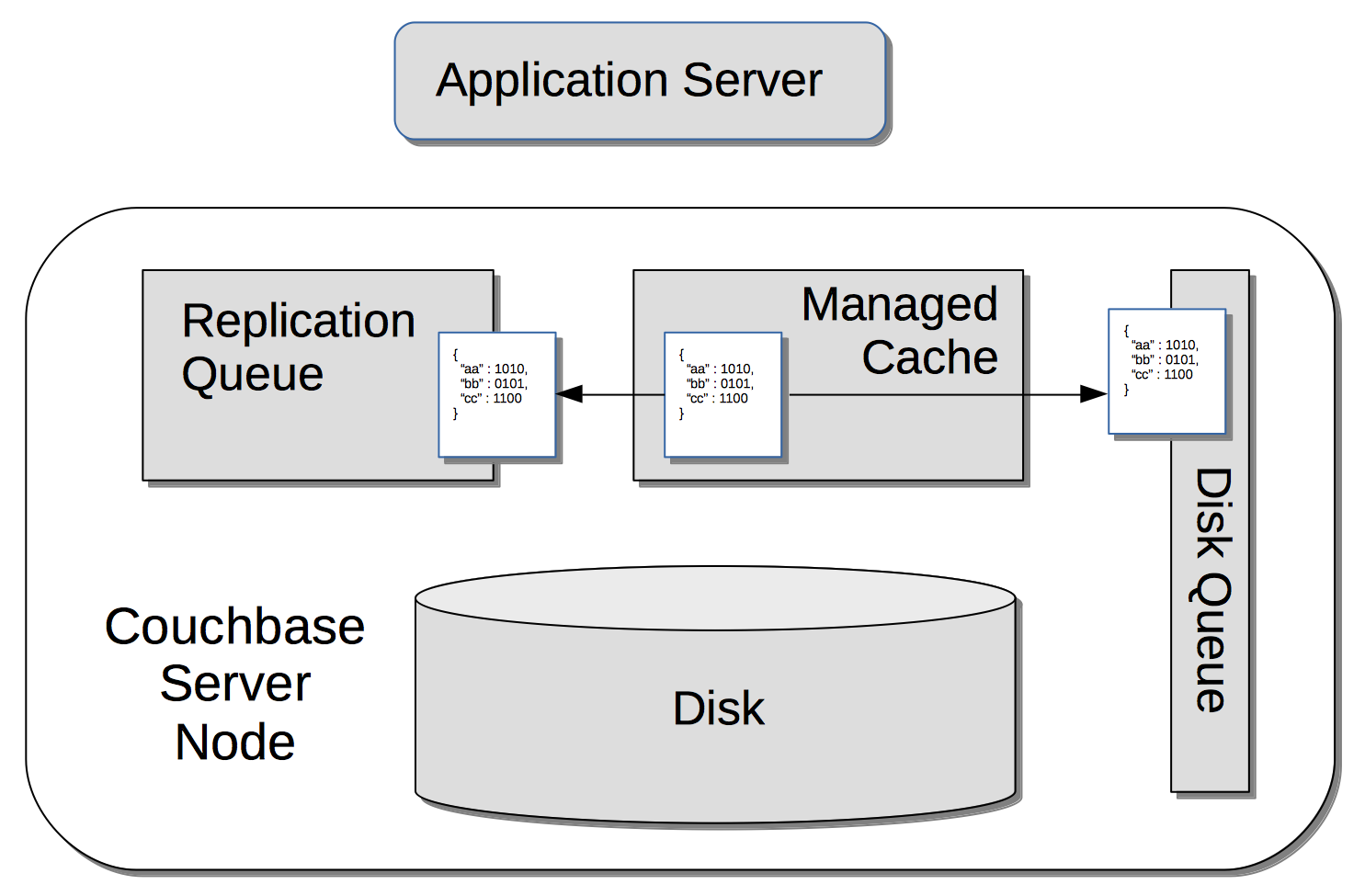
A sequence of diagrams is provided to show the memory and storage architecture whereby Couchbase Server handles Saving New Items.
Memory Quotas
Couchbase Server monitors the memory used by buckets with respect to fixed memory quotas. If watermarks are exceeded, automated management action is taken, to ensure that the data items most needed are retained in memory, and those less needed removed.
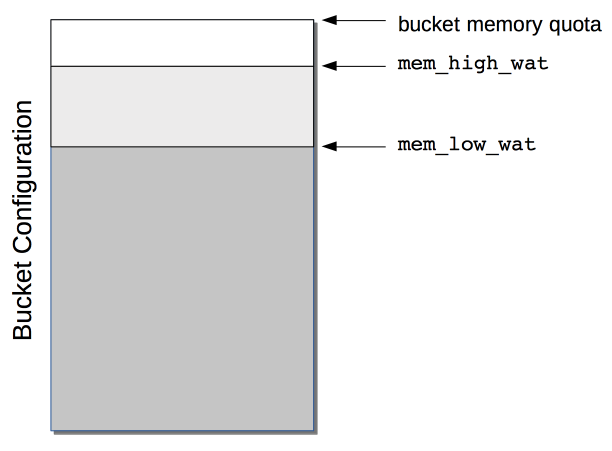
This is explained in detail, and the relations of memory quotas represented graphically, in Ejection.
Multiple Root Certificates
Couchbase Server supports use of multiple CA (or root) certificates, for a single cluster. This allows an individual node either to use a CA that is also used by one or more other nodes; or to use a CA that is used by no other node. This may be used during CA certificate rotation: a new CA is uploaded, node certificates are changed one by one, and finally, the old CA is removed.
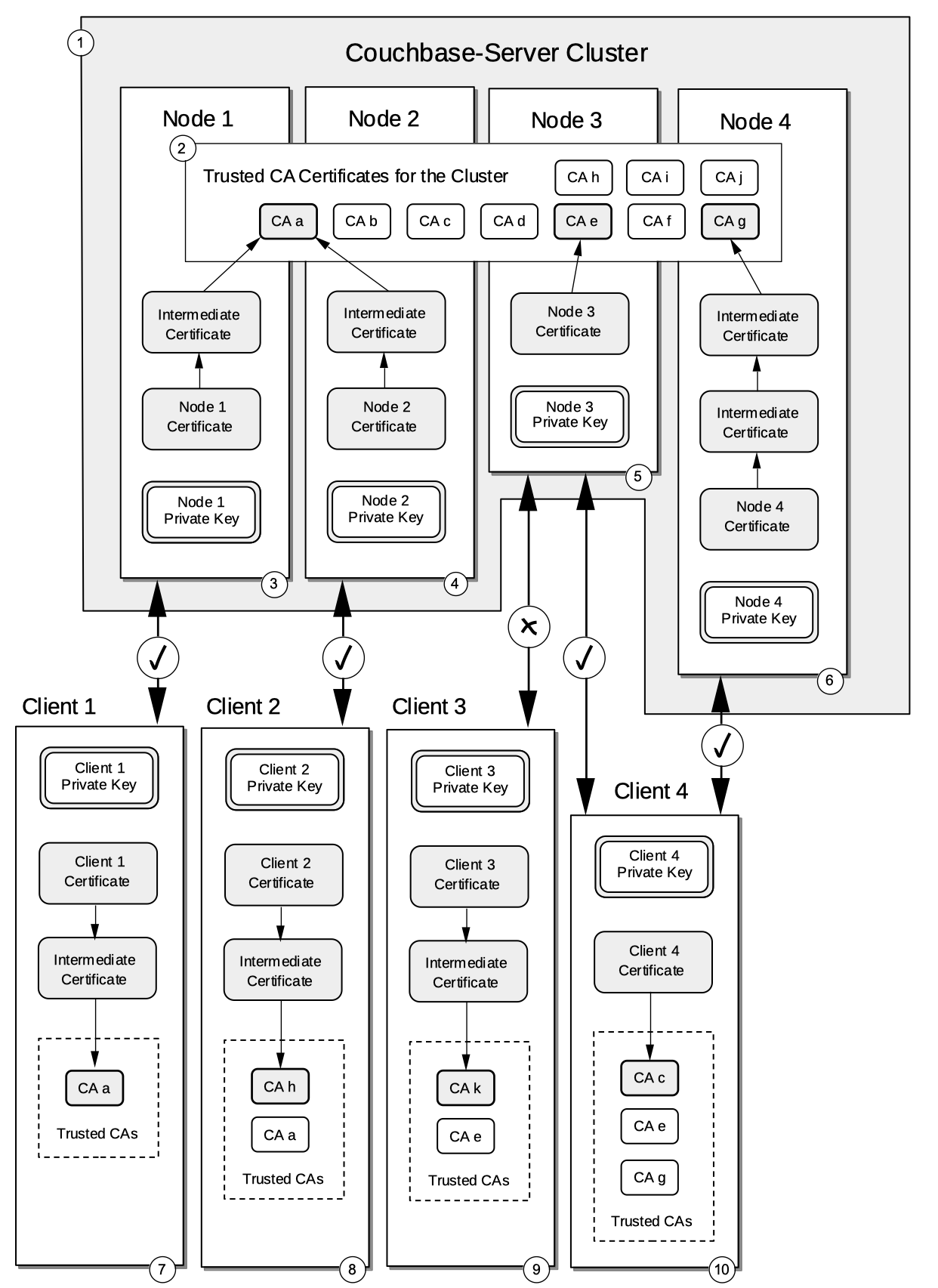
For detailed information, see Using Multiple Root Certificates.