Retrieving documents
In this section, you’re going to look at two methods of retrieving documents from a collection: you will use the administration console to build simple queries, and also write a short program to retrieve documents matching certain criteria. Both of the methods will introduce N1QL (pronounced 'nickel'), Couchbase’s SQL-based query language.
Using the Query Editor
Return to the admin console, and click on the Query item on the left-hand menu.
This will take you to the query workbench. The workbench has a few filter fields that’ll make it much easier to narrow down our search criteria.
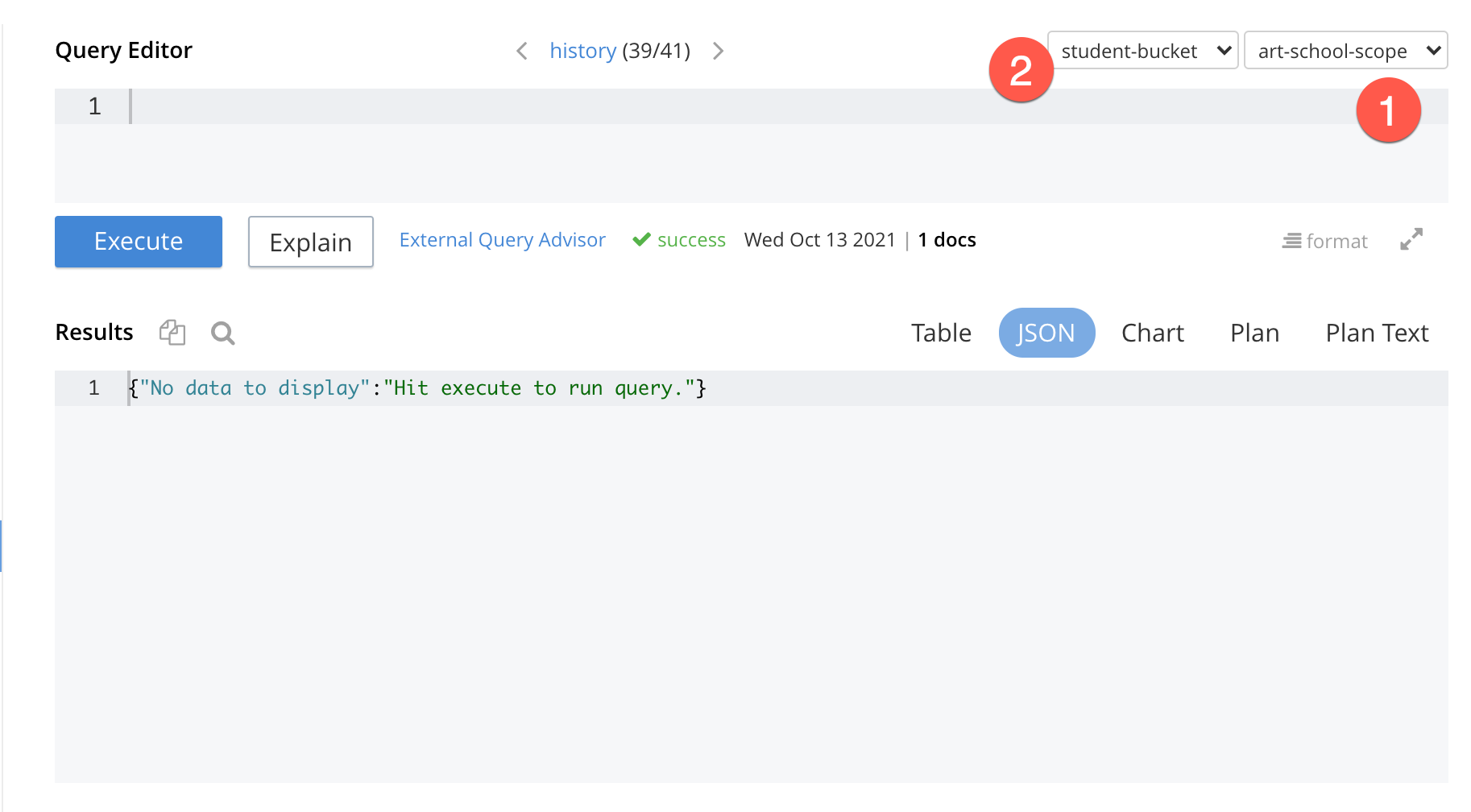
Use the two dropdown items to select the student-bucket and the art-school-scope. This narrows the scope of the queries, meaning you don’t have to add the name of the bucket and the scope to your queries.
Okay, let’s try a simple query to retrieve all the course in our collection.
Type the following query into the query editor field:
select crc.* from `course-record-collection` crc| N1QL is very similar to standard SQL. Once you have mastered the document database model, you’ll find it very easy to adapt. |

What happens when you hit Execute?
You get an error message returned from the cluster:
[
{
"code": 4000, (1)
"msg": "No index available on keyspace `default`:`student-bucket`.`art-school-scope`.`course-record-collection` that matches your query. Use CREATE PRIMARY INDEX ON `default`:`student-bucket`.`art-school-scope`.`course-record-collection` to create a primary index, or check that your expected index is online.", (2)
"query": "select * from `course-record-collection`" (3)
}
]| 1 | The internal Couchbase code for the message. |
| 2 | A plain text description telling you what happened. In this case, the problem is that there no index defined on our bucket, so the search couldn’t locate any key information. |
| 3 | The JSON message also returns the original query. |
Creating an index
Fortunately, you can use the same query editor to add an index to the bucket. To do this, enter the following command into the editor and press Enter.
create primary index course_idx on `course-record-collection`This will create a single index (course_idx) on your course-record-collection.
| The error message returned from the search statement provides an example command for creating the primary index. You can copy the example command and run it in the query editor to create your primary index. |
Okay, now if you run the select query again …
select crc.* from `course-record-collection` crcNow you should get a result:
[
{
"course-name": "art history",
"credit-points": 100,
"faculty": "fine art"
},
{
"course-name": "fine art",
"credit-points": 50,
"faculty": "fine art"
},
{
"course-name": "graphic design",
"credit-points": 200,
"faculty": "media and communication"
}
]Okay, now try something else: returning the courses with credit-points of less than 200:
select crc.* from `course-record-collection` crc where crc.`credit-points` < 200which will bring back:
[
{
"course-name": "art history",
"credit-points": 100,
"faculty": "fine art"
},
{
"course-name": "fine art",
"credit-points": 50,
"faculty": "fine art"
}
]But what about the primary id field?
Good question. You may want to get hold of id field, which as you can see, isn’t returned with the document, even if we’re asking for all the fields in the call. The primary key exists as part of the document’s "meta" structure, which can be interrogated along with the rest of the document. Make the following small adjustment to the N1QL statement and run the query again:
select META().id, crc.* from `course-record-collection` crc where crc.`credit-points` < 200The META() function call will return any property contained in the document’s metadata, including its id:
[
{
"course-name": "art history",
"credit-points": 100,
"faculty": "fine art",
"id": "ART-HISTORY-000001" (1)
},
{
"course-name": "fine art",
"credit-points": 50,
"faculty": "fine art",
"id": "FINE-ART-000002" (1)
}
]| 1 | id fields added to the returned document. |
You can find a full rundown of the N1QL language here: N1QL Language Reference.
Using the SDK
Of course, you can also retrieve documents using the JDK. In this section, you’re going to use the same N1QL queries as part of a small Java application. Let’s start with a basic record retrieval:
Unresolved include directive in modules/tutorials/pages/java-tutorial/retrieving-documents.adoc - include::3.2@java-sdk:student:example$ArtSchoolRetriever.java[]If you build and run this program:
mvn exec:java -Dexec.mainClass="ArtSchoolRetriever" -Dexec.cleanupDaemonThreads=falseThen you’ll get a list of the classes in the output.
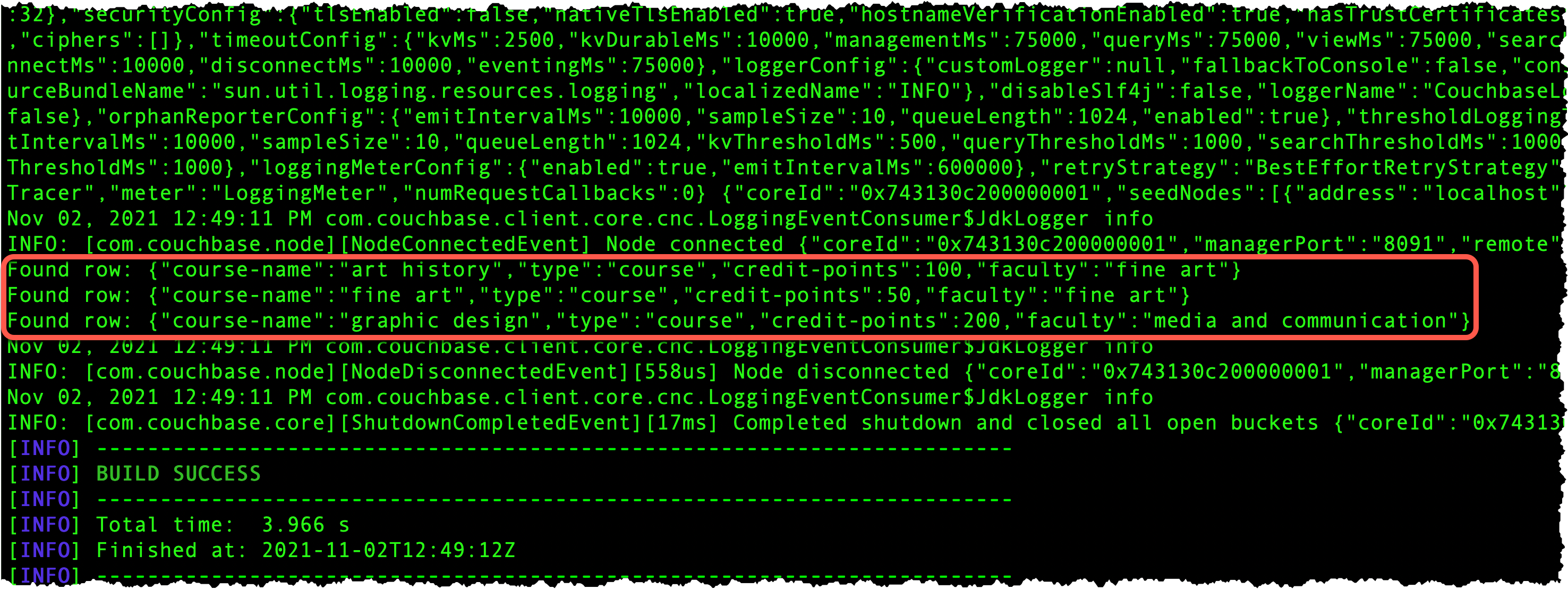
You may have noticed a difference between the SQL statement we used in the web console, and the statement used as part of the application:
select crc.* from `student-bucket`.`art-school-scope`.`course-record-collection` crcThe name of the collection in the N1QL statement has to be fully qualified, including the name of the bucket as well as the containing scope.
You can, of course, set parameters as part of your query, as shown in the next example:
Unresolved include directive in modules/tutorials/pages/java-tutorial/retrieving-documents.adoc - include::3.2@java-sdk:student:example$ArtSchoolRetrieverParameters.java[]| 1 | The N1QL statement takes a parameters $creditPoints which will be substituted with a correctly typed value when the statement is called. |
| 2 | The value to substitute is provided in the QueryOptions given as the second parameter in the call.
The value of the map entry is the actual parameter value (in this case, 200 which we’re using to test the credit-points). |
You can use maven to run the program:
mvn exec:java -Dexec.mainClass="ArtSchoolRetrieverParameters" -Dexec.cleanupDaemonThreads=falseNext steps
Now you can add and search for records, the next section will consolidate what you’ve learned so far by demonstrating how to amend existing records by adding enrollment details. So when you’re ready carry on to Adding Course Enrollments.