Retrieve Records
- tutorial
Retrieve records, or documents, from your collections using SQL++, Couchbase’s SQL-based query language. You can retrieve your records using the query editor or the SDK.
With the Query Editor
To retrieve the records with the Query Editor, you must first define an index.
Define an Index
Before you can retrieve your records with the query editor, you must first define an index in your bucket. The index helps your cluster find specific data when you run a query.
To define an index:
-
In your Couchbase cluster in your browser, click Query to open the query editor.
-
Select student-bucket and art-school-scope in the context drop-down. Using these filters means you can narrow down the scope of your queries. You do not need to add the names of your bucket and scope to your queries.
-
Enter the following query into your query editor:
create primary index course_idx on `course-record-collection` -
Click Execute to create a single index called
course_idxin yourcourse-record-collection.
Retrieve Your Records
You can use the Query Editor to retrieve all course records at once, or narrow your search down to retrieve records based on specific criteria.
Retrieve All Course Records
To retrieve all of your course records using the query editor:
-
Enter the following query into your query editor:
select crc.* from `course-record-collection` crc -
Click Execute to retrieve all course records.
[ { "course-name": "art history", "credit-points": 100, "faculty": "fine art" }, { "course-name": "fine art", "credit-points": 50, "faculty": "fine art" }, { "course-name": "graphic design", "credit-points": 200, "faculty": "media and communication" } ]
Retrieve Course Records with Less than 200 Credits
You can expand your query to narrow your search down further.
To retrieve only courses with less than 200 credit-points using the query editor:
-
Enter the following query into your query editor:
select crc.* from `course-record-collection` crc where crc.`credit-points` < 200 -
Click Execute to retrieve all courses with less than 200 credits.
[ { "course-name": "art history", "credit-points": 100, "faculty": "fine art" }, { "course-name": "fine art", "credit-points": 50, "faculty": "fine art" } ]
Retrieve Record IDs
The id field is not automatically returned when you retrieve all of your course information.
The id is part of a document’s meta structure, and to retrieve it you must adjust your SQL++ query and run it again:
-
Enter the following query into your query editor:
select META().id, crc.* from `course-record-collection` crc where crc.`credit-points` < 200The
META()function call returns any property contained inside the document’s metadata, including the ID. -
Click Execute to retrieve course records and their IDs.
[ { "course-name": "art history", "credit-points": 100, "faculty": "fine art", "id": "ART-HISTORY-000001" }, { "course-name": "fine art", "credit-points": 50, "faculty": "fine art", "id": "FINE-ART-000002" } ]
With the SDK
You can also use SQL++ queries to retrieve your records with the SDK. Unlike the query editor, though, you must include the name of the bucket and the scope to fully qualify the name of the collection in the SQL++ statement in your application. For example:
select crc.* from `student-bucket`.`art-school-scope`.`course-record-collection` crcRetrieve Your Records
You can use the SDK to retrieve all course records at once, or narrow your search down to retrieve records based on specific criteria.
Retrieve All Course Records
To retrieve all of your course records using the Java SDK:
-
In your
javadirectory, create a new file calledArtSchoolRetriever.java. -
Paste the following code block into your
ArtSchoolRetriever.javafile:import com.couchbase.client.core.error.CouchbaseException; import com.couchbase.client.java.Cluster; import com.couchbase.client.java.json.JsonObject; import com.couchbase.client.java.query.QueryResult; public class ArtSchoolRetriever { public static void main(String[] args) { Cluster cluster = Cluster.connect("localhost", "username", "password"); retrieveCourses(cluster); cluster.disconnect(); } private static void retrieveCourses(Cluster cluster) { try { final QueryResult result = cluster.query("select crc.* from `student-bucket`.`art-school-scope`.`course-record-collection` crc"); for (JsonObject row : result.rowsAsObject()) { System.out.println("Found row: " + row); } } catch (CouchbaseException ex) { ex.printStackTrace(); } } } -
Open a terminal window and navigate to your
studentdirectory. -
Run the command
mvn installto pull in all the dependencies and rebuild your application. -
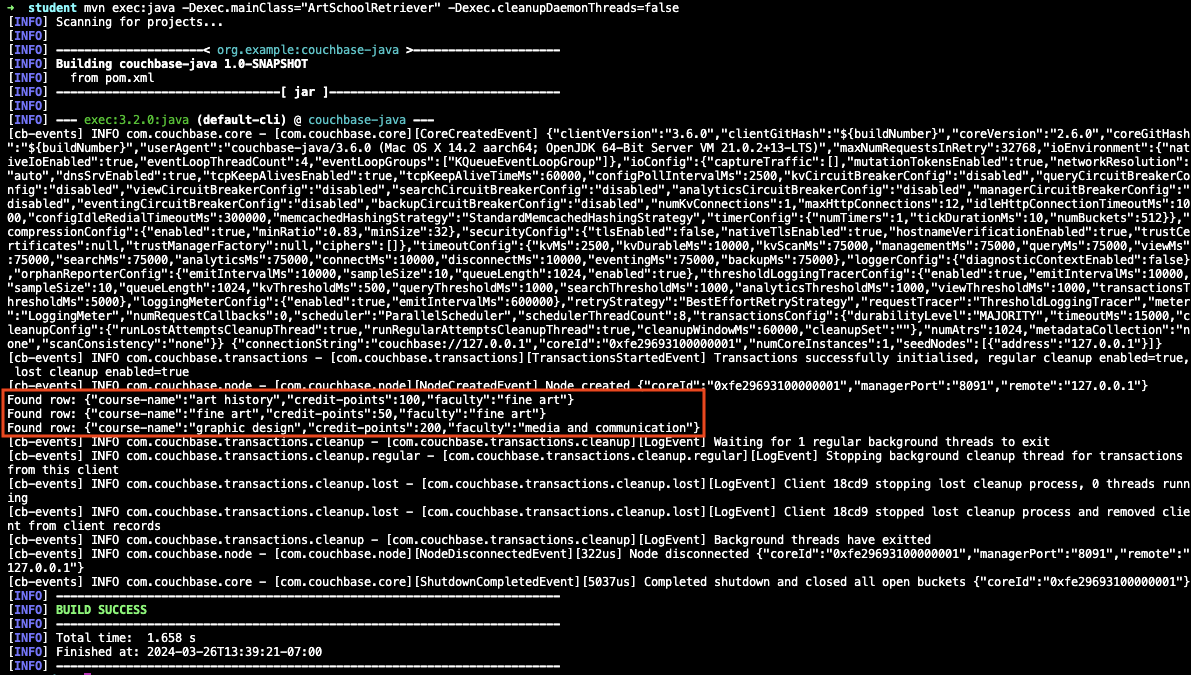
Run the following command to retrieve all course records:
mvn exec:java -Dexec.mainClass="ArtSchoolRetriever" -Dexec.cleanupDaemonThreads=falseIf the retrieval is successful, the course information outputs in the console log.
Retrieve Course Records with Less than 200 Credits
You can set parameters in your code to narrow your search down further.
To retrieve only courses with less than 200 credit-points using the Java SDK:
-
In your
javadirectory, create a new file calledArtSchoolRetrieverParameters.java. -
Paste the following code block into your
ArtSchoolRetrieverParameters.javafile:import com.couchbase.client.core.error.CouchbaseException; import com.couchbase.client.java.Cluster; import com.couchbase.client.java.json.JsonObject; import com.couchbase.client.java.query.QueryOptions; import com.couchbase.client.java.query.QueryResult; public class ArtSchoolRetrieverParameters { public static void main(String[] args) { Cluster cluster = Cluster.connect("localhost", "username", "password"); retrieveCourses(cluster); cluster.disconnect(); } private static void retrieveCourses(Cluster cluster) { try { // This SQL++ statement takes the parameter `$creditPopints`, // which is then substituted by the value in the second parameter when the statement is called. final QueryResult result = cluster.query("select crc.* " + "from `student-bucket`.`art-school-scope`.`course-record-collection` crc " + "where crc.`credit-points` < $creditPoints", // The second parameter in the function call, with a value that replaces `$creditPoints`. QueryOptions.queryOptions() .parameters(JsonObject.create().put("creditPoints", 200))); for (JsonObject row : result.rowsAsObject()) { System.out.println("Found row: " + row); } } catch (CouchbaseException ex) { ex.printStackTrace(); } } } -
Open a terminal window and navigate to your
studentdirectory. -
Run the command
mvn installto pull in all the dependencies and rebuild your application. -
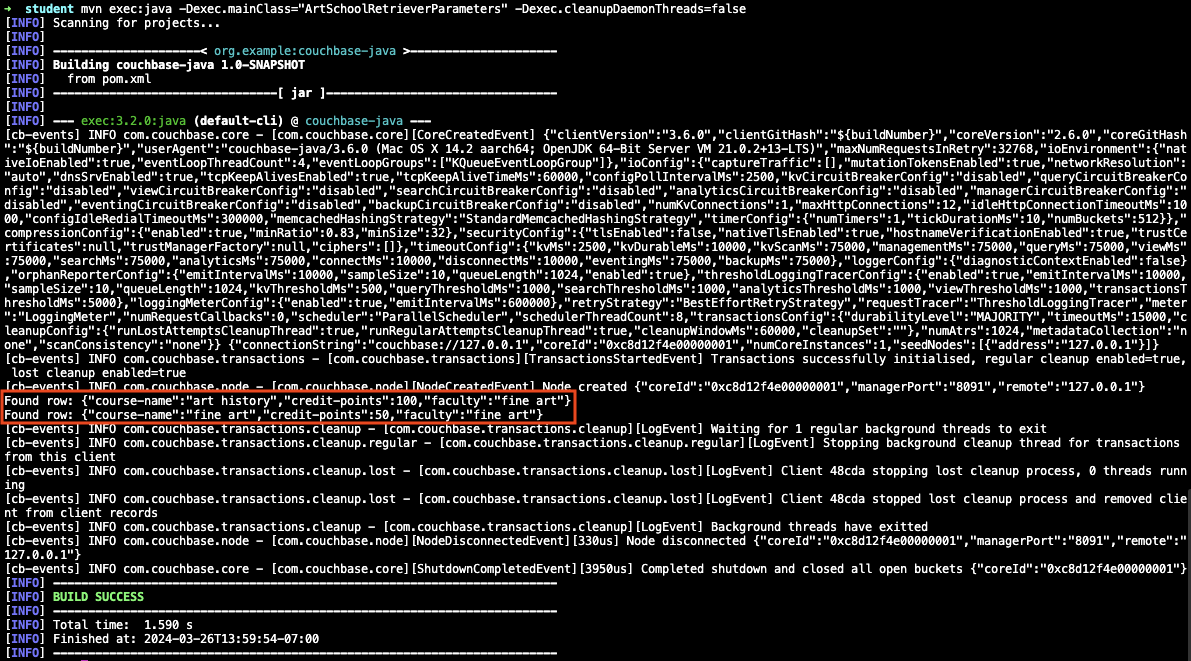
Run the following command to retrieve all course records:
mvn exec:java -Dexec.mainClass="ArtSchoolRetrieverParameters" -Dexec.cleanupDaemonThreads=falseIf the retrieval is successful, the course information with your parameters outputs in the console log.
If you come across errors in your console, see the troubleshooting page.
Next Steps
After retrieving student and course records, you can add enrollment details to the student records using the SDK.