Cluster Manager
The Couchbase Cluster Manager runs on all the nodes of a cluster, maintaining essential per-node processes, and coordinating cluster-wide operations.
Cluster Manager Architecture
The architecture of the Cluster Manager is as follows:
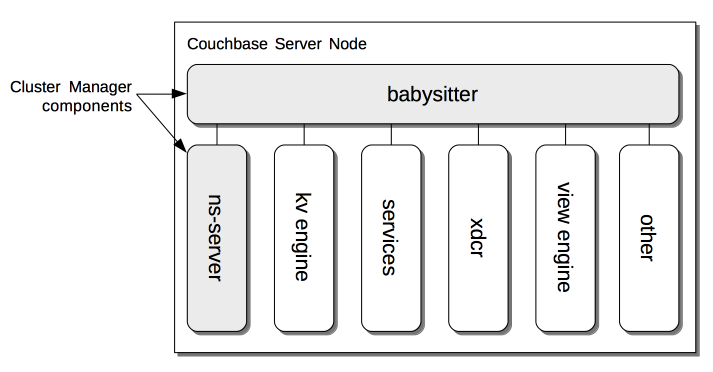
As shown, the Cluster Manager consists of two processes.
The first, the babysitter, is responsible for maintaining a variety of Couchbase Server-processes, which indeed include the second Cluster Manager process, ns-server.
The babysitter starts and monitors all of these processes, logging their output to the file babysitter.log (see
Manage Logging, for information on
logfile-locations).
If any of the processes dies, the babysitter restarts it.
The babysitter is not cluster-aware.
The processes for which the babysitter is responsible are:
-
ns-server: Manages the node’s participation in the cluster, as described in ns-server, below.
-
kv engine: Runs as part of the Data Service, which must be installed on at least one cluster-node. Provides access to Data.
-
services: One or more Couchbase Services that optionally run on the node.
-
xdcr: The program for handling Cross Data-Center Replication (XDCR). This is installed with the Data Service, but runs as an independent OS-level process, separate from the Cluster Manager itself. See Availability, for information.
-
view engine: The program for handling Views. This is installed with the Data Service, but runs as an independent OS-level process, separate from the Cluster Manager itself. See Views, for more information.
-
other: Various ancillary programs.
ns-server
The principal Cluster-Manager process is ns-server, whose architecture is as follows:
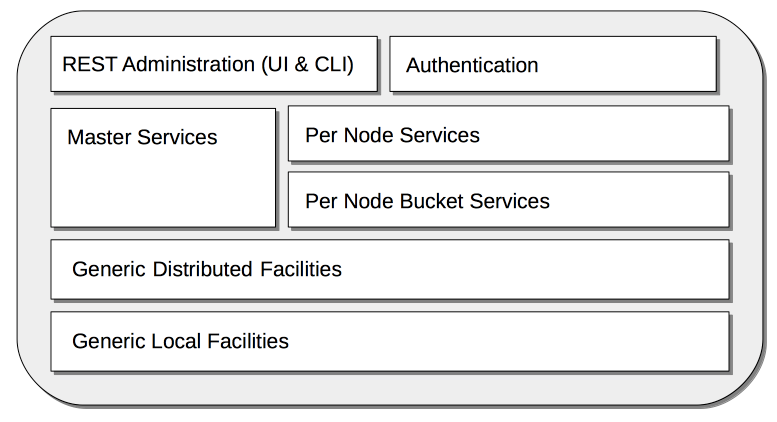
The modules are:
-
REST Administration (UI and CLI): Supports administration of Couchbase Server, by means of a REST API; which itself underlies both the user interface provided by Couchbase Web Console, and the Couchbase Command-Line Interface.
-
Authentication: Protects node-resources with Role-Based Access Control. This is based on credentials (usernames and passwords) associated with system-defined roles, each of which is associated with a range of privileges. For detailed information, see Authorization.
-
Master Services: Manage operations with cluster-wide impact; such as failover, rebalance, and adding and deleting buckets. Note that at any given time, only one of the instances of Master Services on a multi-node cluster is in charge: the instances having negotiated among themselves, to identify and elect the instance. Should the elected instance subsequently become unavailable, another takes over. The Master Services are sometimes referred to as the Orchestrator.
-
Per Node Services: Manages the health of the current node, and handles the monitoring and restart of its processes and services.
-
Per Node Bucket Services: Manages bucket-level operations for the current node; supporting replication, fail-over, restart, and statistics-collection.
-
Generic Distributed Facilities: Supports node-discovery, configuration-messaging and alerts, replication, and heartbeat-transmission.
-
Generic Local Facilities: Provides local configuration-management, libraries, workqueues, logging, clocks, ids, and events.
Adding and Removing Nodes
The elected Master Services of the Cluster Manager are responsible for cluster membership. When topology changes, a set of operations is executed, to accomplish redistribution while continuing to handle existing workloads. This is as follows:
-
The Master Services update the new nodes with the existing cluster configuration.
-
The Master Services initiate rebalance, and recalculate the vBucket map.
-
The nodes that are to receive data initiate DCP replication-streams from the existing nodes for each vBucket, and begin building new copies of those vBuckets. This occurs for both active and replica vBuckets, depending on the new vBucket map layout.
-
Incrementally — as each new vBucket is populated, the data is replicated, and indexes are updated — an atomic switchover takes place, from the old vBucket to the new vBucket.
-
As new vBuckets on new nodes become active, the Master Services ensure that the new vBucket map and cluster topology are communicated to all nodes and clients. This process is repeated until rebalance is complete.
The process of removing one or more Data-Service nodes is similar to that of adding: vBuckets are created on nodes that are to be maintained, and data is copied to them from vBuckets resident on nodes that are to be removed. When no more vBuckets remain on a node, the node is removed from the cluster.
When adding or removing nodes that do not host the Data Service, no data is moved: therefore, nodes are added or removed from the cluster map without data-transition.
Once the process of adding or removing is complete, and a new cluster map has been made available by the Master Services, client SDKs automatically begin load-balancing across those services, using the new cluster map.
For the practical steps to be following in adding and removing nodes, see Add a Node and Rebalance and Remove a Node and Rebalance.
Node-Failure Detection
Nodes within a Couchbase Server-cluster provide status on their health by means of a heartbeat mechanism. Heartbeats are provided by all instances of the Cluster Manager, at regular intervals. Each heartbeat contains basic statistics on the node, which are used to assess the node’s condition.
The Master Services keep track of heartbeats received from all other nodes. If automatic failover is enabled, and no heartbeats are received from a node for longer than the default timeout period, the Master Services may automatically fail the node over.
For detailed information on failover options, see Fail a Node over and Rebalance.
vBucket Distribution
Couchbase Server buckets physically contain 1024 active and 0 or more replica vBuckets. The Master Services govern the placement of these vBuckets, to maximize availability to and rebalance performance. The vBucket map is recalculated whenever the cluster topology changes, by means of the following rules:
-
Active and replica vBuckets are placed on separate nodes.
-
If a bucket is configured with more than one replica, each additional replica vBucket is placed on a separate node.
-
If Server Groups are defined for active vBuckets, the replica vBuckets are placed in a separate groups. See Server Group Awareness, for more information.
Centralized Management, Statistics, and Logging
The Cluster Manager simplifies centralized management with centralized configuration-management, statistics-gathering, and logging services. All configuration-changes are managed by the Master Services, and are pushed out from the Master Services node to the other nodes.
Statistics are accessible through all the Couchbase administration interfaces: The CLI, the REST API, and Couchbase Web Console. See Management Tools.