Remove a Node and Rebalance
Couchbase Server allows a cluster node to be removed, and the remaining nodes rebalanced.
Understanding Removal and Rebalance
The rebalance operation distributes active and replica vBuckets across available cluster nodes in optimal fashion. This allows the best possible data-availability to be maintained after nodes have been added or removed. Examples of using rebalance after node-addition have already been provided, in Add a Node and Rebalance and Join a Cluster and Rebalance. In particular, reference was made in both locations to the data initially resident on a single node being replicated and distributed, across two nodes, following node-addition.
Nodes can also be rebalanced following removal: this is demonstrated in the current section. When a node is flagged for removal (as opposed to failover), new replica vBuckets will be created on the remaining nodes, as node-removal occurs. This has the effect of reducing available memory for the specified number of replicas.
This page provides the steps to be taken for node-removal and rebalance. For a conceptual explanation of removal, see Removal.
Examples on This Page
The examples in the subsections below show how to remove the same node from the same two-node cluster; using the UI, the CLI, and the REST API respectively. The examples assume:
-
A two-node cluster already exists; as at the conclusion of List Cluster Nodes.
-
The cluster has the Full Administrator username of
Administrator, and password ofpassword.
Remove a Node with the UI
Proceed as follows:
-
Access the Servers screen of Couchbase Web Console, by means of the Servers tab in the left-hand navigation bar. The screen appears as follows:

-
Left-click on the row for node
10.142.181.102. The row expands vertically, as follows: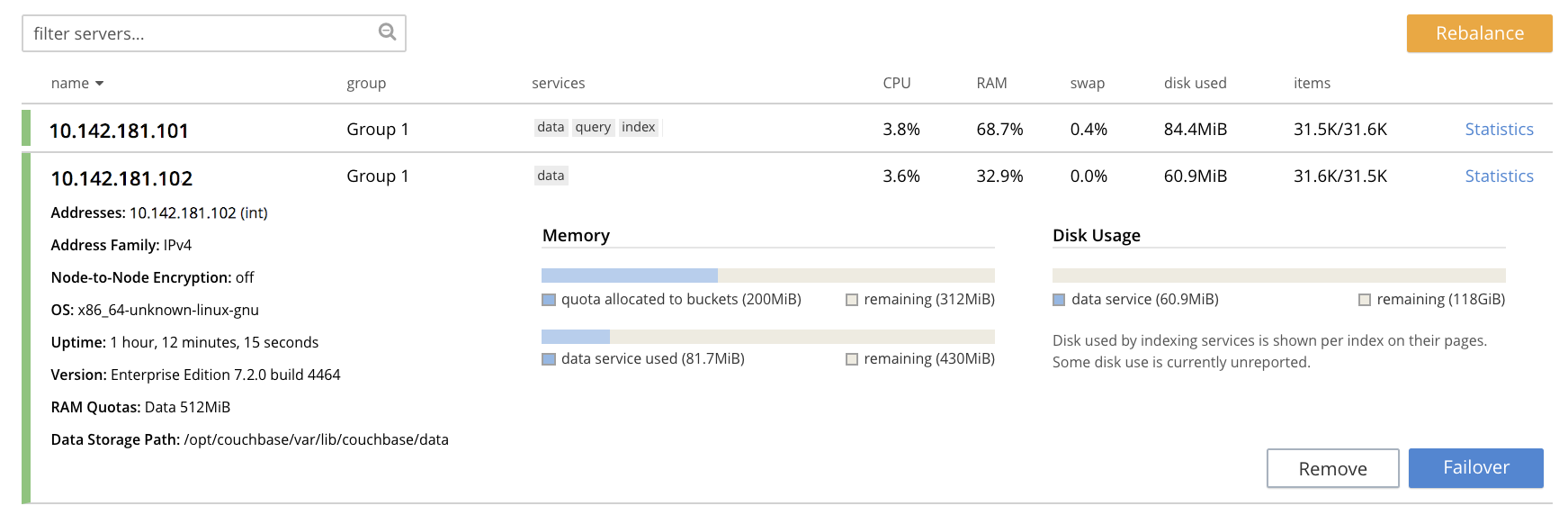
-
To initiate removal, left-click on the Remove button, at the lower left of the row:
The Confirm Server Removal dialog appears:
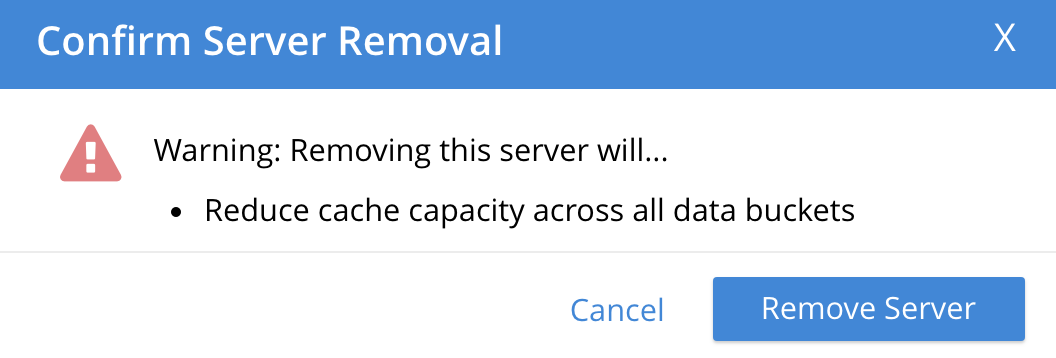
Left-click on the Remove Server confirmation button. The Servers screen reappears as follows:
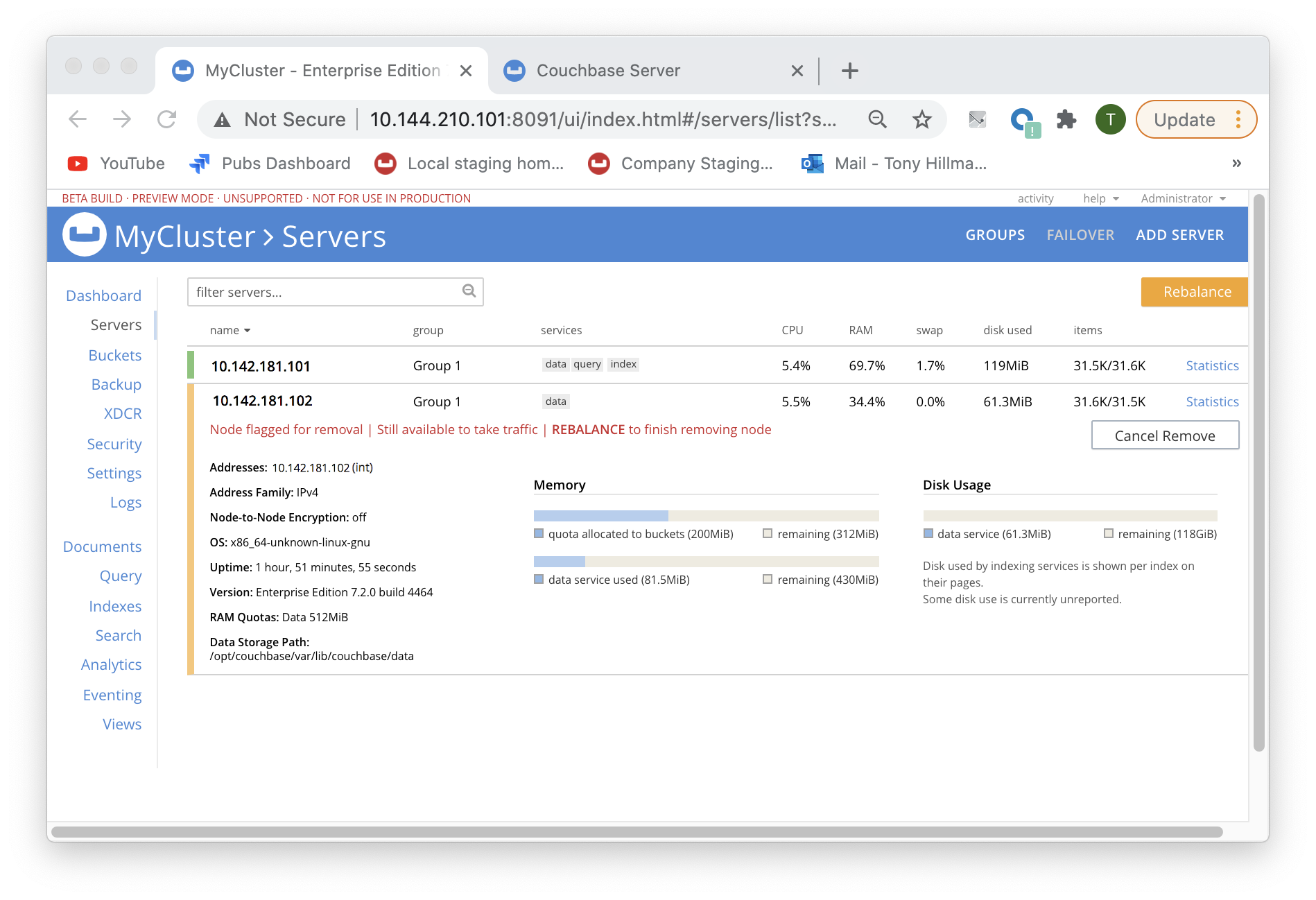
This indicates that node
10.142.181.102has beenflagged for removal, and isStill available to take traffic. A rebalance must be performed to complete removal. -
Left-click on the Rebalance button, at the upper right:

Rebalancing now occurs. A dialog appears, providing status on progress.

Following the rebalance, the Servers screen confirms that a single node remains. All Items (from the
travel-samplebucket) are again solely located on10.142.181.101, with no replicas (since at least two nodes are required for replication to occur).
Note that if rebalance fails, notifications are duly provided. These are described in Rebalance Failure Notification. See also the information provided on Automated Rebalance-Failure Handling, and the procedure for its set-up, described in Rebalance Settings.
Remove a Node with the CLI
A node can be removed from the cluster by means of the CLI. Note that the node does not have to be failed over prior to removal.
To remove the node and perform the necessary rebalance, use the rebalance command with the --server-remove option.
couchbase-cli rebalance -c 10.142.181.102:8091 \ --username Administrator \ --password password --server-remove 10.142.180.102:8091
This initiates the rebalance process. As it continues, progress is shown as console output:
Rebalancing Bucket: 01/01 (travel-sample) 0 docs remaining [================================ ] 31.67%
For more information, see the command reference for rebalance.
Remove a Node with the REST API
To remove a node from a cluster with the REST API, and rebalance the remaining nodes, use the /controller/rebalance URI.
This requires that all known nodes be specified, and that the nodes to be ejected also be specified:
curl -u Administrator:password -v -X POST \ http://10.142.181.101:8091/controller/rebalance \ -d 'ejectedNodes=ns_1%4010.142.181.102' \ -d 'knownNodes=ns_1%4010.142.181.101%2Cns_1%4010.142.181.102'
The command returns no output.
Next Steps
Nodes can be failed over, so that an unhealthy or unresponsive node can be removed from the cluster without application-access being affected. See Fail Nodes Over.