Services
Couchbase Services support access to and maintenance of data. Services can be deployed with flexibility across available hardware-resources, providing Multi-Dimensional Scaling, whereby a cluster can be tuned for optimal handling of emergent workloads.
Services are configured and deployed by the Full Administrator who initializes Couchbase Server on one or more nodes. The standard configuration-sequence allows a subset of services to be selected per node, with an individual memory-allocation for each. Each service supports a particular form of data-access. Services not required need not be deployed. Services intended to support a heavy workload can be deployed across multiple cluster-nodes, to ensure optimal performance and resource-availability.
Services and Multi-Dimensional Scaling
Couchbase Server provides the following services:
-
Data: Supports the storing, setting, and retrieving of data-items, specified by key.
-
Query: Parses queries specified in the N1QL query-language, executes the queries, and returns results. The Query Service interacts with both the Data and Index services.
-
Index: Creates indexes, for use by the Query and Analytics services.
-
Search: Create indexes specially purposed for Full Text Search. This supports language-aware searching; allowing users to search for, say, the word
beauties, and additionally obtain results forbeautyandbeautiful. -
Analytics: Supports join, set, aggregation, and grouping operations; which are expected to be large, long-running, and highly consumptive of memory and CPU resources.
-
Eventing: Supports near real-time handling of changes to data: code can be executed both in response to document-mutations, and as scheduled by timers.
-
Backup: Supports the scheduling of full and incremental data backups, either for specific individual buckets, or for all buckets on the cluster. Also allows the scheduling of merges of previously made backups.
These services can be deployed, maintained, and provisioned independently of one another, by means of Multi-Dimensional Scaling, to ensure the most effective ongoing response to changing business conditions and emergent workload-requirements.
Setting Up Services
Services are set up on a per node basis. Each node can run at most one instance of a service. The Data Service must run on at least one node. Some services are interdependent, and therefore require at least one instance of each of their dependencies to be running on the cluster (for example, the Query Service depends on the Index Service and on the Data Service).
When the first node in a cluster is initialized, the services assigned to it become the default assignment for each other node subsequently to be added to the cluster. However, this default can be departed from, node by node; with one or more services omitted from the default, and one or more added.
When first allocated to a node, a service requires the assignment of a specific memory quota, which becomes standard for that service in each of its instances across the cluster. (The exception to this is the Query Service, which never requires a memory quota.)
Service-allocation should be designed based on workload-analysis: if a particular service is expected to handle a heavy workload, it should be allocated with a larger memory quota, and potentially as the only service on the node. Alternatively, if a cluster is to be used for development purposes only, it may be convenient to allocate services in the quickest and most convenient way, with some quotas being equal.
For example, the following illustration shows how four services — Data, Index, Query, and Search — might be allocated evenly across the five nodes of a development cluster:
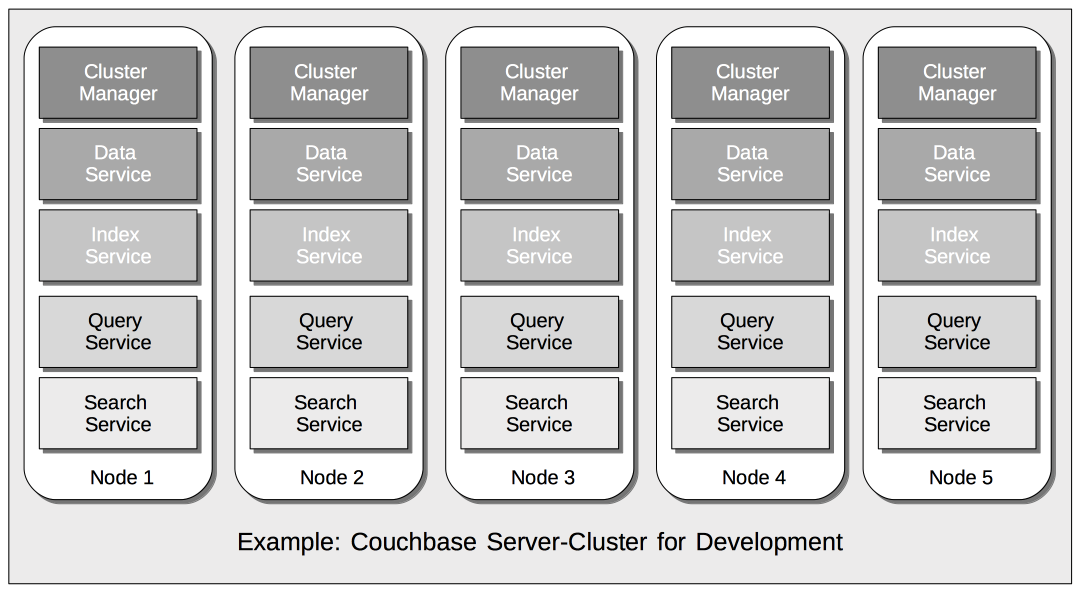
This configuration might provide perfectly acceptable performance for each of the four services, in the context of development and testing. However, if a large amount of data needed, in production, to be intensively indexed, and addressed by means of Query and Search, the following configuration would be more efficient:
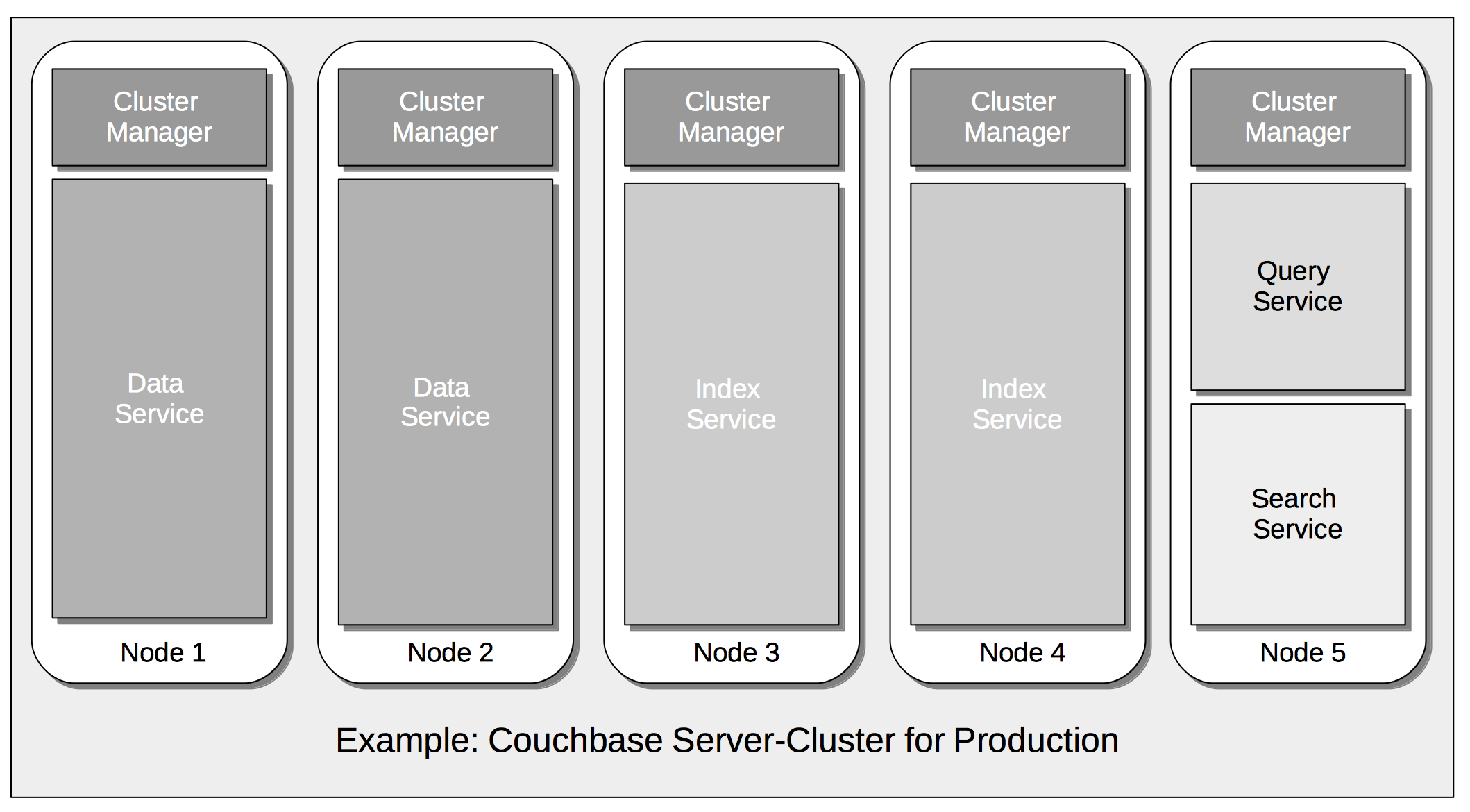
In this revised configuration, the Data Service is the only service to run on two of the nodes; the Index Service the only service on two futher nodes; and the Query and Search Services share the fifth and final node.
For a more detailed explanation of service memory quotas, see Memory. For information on the practical steps required to initialize a cluster, including the allocation of services to nodes, see Create a Cluster.
Multi-Dimensional Scaling
The ability to deploy Couchbase Services with flexibility across hardware-resources supports Multi-Dimensional Scaling, whereby a cluster can be fine-tuned for optimal handling of emergent workload-requirements. If, for example, a greater Search workload-requirement is encountered, one or more existing non-Search nodes can be removed, reconfigured to run the Search Service, and re-added to the cluster.
Alternatively, additional hardware-resources (CPU, memory, disk-capacity) can be added to targeted nodes in the cluster, in order to support the performance of key services. This ability to provision services independently from one another, and thereby scale their performance individually up and down as required, provides the greatest flexibility in terms of handling changing business requirements, and redeploying existing resources to ensure continuously heightened efficiency.