Index partitioning enables you to increase aggregate query performance by dividing and spreading a large index of documents across multiple nodes, horizontally scaling out an index as needed. The system partitions the index across a number of index nodes using a hash partitioning strategy in a way that’s transparent to queries.
Benefits of a partitioned index include:
-
The ability to scale out horizontally as the index size increases.
-
Transparency to queries, requiring no change to existing queries.
-
Reduction of query latency for large aggregated queries since each partition can be scanned in parallel.
-
Provides a low-latency range query while allowing indexes to be scaled out as needed.
Partitioned indexes are displayed in the Couchbase Web Console with a partitioned indicator:
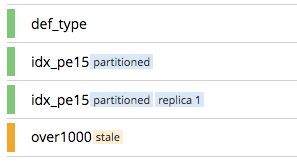
For more information, see Manage Indexes.
Syntax
To create a partitioned index, the overall syntax is the same as for a primary index or global secondary index. The distinguishing feature is the use of the PARTITION BY HASH clause to specify the partitions.
For more information, see CREATE PRIMARY INDEX, CREATE INDEX, or CREATE VECTOR INDEX.
PARTITION BY HASH Clause
index-partition ::= 'PARTITION' 'BY' 'HASH' '(' partition-key-expr
( ',' partition-key-expr )* ')'
| partition-key-expr |
A field or an expression over a field representing a partition key. For details and examples, see Partition Keys. |
WITH Clause
index-with ::= 'WITH' expr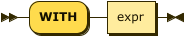
When creating a partitioned index, you can use the WITH clause to specify additional options for the partitions.
| expr |
An object with the following properties. |
| Name | Description | Schema |
|---|---|---|
num_partition |
The number of partitions to divide the index into. For more information, see Number of Partitions. Default: |
Integer |
nodes |
A list of nodes to restrict the set of nodes available for placement. For more information, see Partition Placement. For details of the syntax, see CREATE PRIMARY INDEX, CREATE INDEX, or CREATE VECTOR INDEX. |
String array |
defer_build |
When set to true, the index creation operation queues the task for building the index, but immediately pauses the building of the index. For more information, see CREATE PRIMARY INDEX, CREATE INDEX, or CREATE VECTOR INDEX. |
Boolean |
num_replica |
The number of replicas of the partitioned index to create. If this integer is greater than or equal to the number of index nodes in the cluster, then the index creation will fail. For more information, see CREATE PRIMARY INDEX, CREATE INDEX, or CREATE VECTOR INDEX. |
Integer |
secKeySize |
A sizing hint, specifying the average length of the combined index keys. For more information, see Sizing Hints. Example: |
Integer |
docKeySize |
A sizing hint, specifying the average length of the document key Example: |
Integer |
arrSize |
A sizing hint, specifying the average length of the array fields. Non-array fields will be ignored. For more information, see Sizing Hints. Example: |
Integer |
numDoc |
A sizing hint, specifying the number of documents in the index. For more information, see Sizing Hints. Example: |
Integer |
residentRatio |
A sizing hint, specifying the resident ratio of the index. The resident ratio is the memory usage of the index, as a percentage of its estimated data size. For more information, see Sizing Hints. Couchbase recommends setting this property to Example: |
Integer |
Composite Vector indexes and Hyperscale Vector indexes support further options. See CREATE INDEX or CREATE VECTOR INDEX.
Partition Keys
Partition keys are made up of one or more terms, with each term being the document key, a document field, or an expression of document key or field. The partition keys are hashed to generate a partition ID for each document. The partition ID is then used to identify the partition in which the document’s index keys would reside.
The partition keys should be immutable: their values should not change once the document is created.
For example, in the landmark keyspace, the field named activity almost never changes, and is therefore a good candidate for partition key.
If the partition keys have changed, then the corresponding document should be deleted and recreated with the new partition keys.
Each term in the partition keys can be any JSON data type: number, string, boolean, array, object, or NULL.
If a term in the partition keys is missing in the document, the term will have a SQL++ MISSING value.
Partition keys do not support SQL++ array expressions, such as ARRAY ... FOR ... IN.
The following table lists some examples of partition keys.
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
| Partition Type | Example |
|---|---|
The document key. |
|
Any single or multiple immutable field in the defined index. |
|
Any single or multiple immutable non-leading field in the defined index. |
|
Any single or multiple immutable document field not defined in the index. |
|
A function on the index fields, such as |
|
A complex expression on the index fields combining functions and operators. |
|
Use Document Keys as Partition Key
The simplest way to create a partitioned index is to use the document key as the partition key.
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
CREATE INDEX idx_pe1 ON airline (country, name, id)
PARTITION BY HASH(META().id);
SELECT name, id
FROM airline
WHERE country="United States"
ORDER BY name;With meta().id as the partition key, the index keys are evenly distributed among all the partitions.
Every query will gather the qualifying index keys from all the partitions.
Choose Partition Keys for Range Query
An application has the option to choose the partition key that can minimize latency on a range query for a partitioned index.
For example, let’s say a query has an equality predicate based on the field sourceairport and destinationairport.
If the index is also partitioned by the index keys on sourceairport and destinationairport, then the query will only need to read a single partition for the given pair of sourceairport and destinationairport.
In this case, the application can maintain a low query latency while allowing the partitioned index to scale out as needed.
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Lookup all airlines with non-stop flights from SFO to JFK.
CREATE INDEX idx_pe2 ON route
(sourceairport, destinationairport, stops, airline, id)
PARTITION BY HASH (sourceairport, destinationairport);
SELECT airline, id
FROM route
WHERE sourceairport="SFO" AND
destinationairport="JFK" AND
stops == 0
ORDER BY airline;The partition keys do not have to be the leading index keys in order to select qualifying partitions.
As long as the leading index keys are provided along with the partition keys in the predicate, the query engine can still select the qualifying partitions for index scan.
The following example scans a single partition with a given pair of sourceairport and destinationairport.
Lookup all non-stop flights from SFO to JFK for the given airlines.
CREATE INDEX idx_pe3 ON route
(airline, sourceairport, destinationairport, stops, id)
PARTITION BY HASH (sourceairport, destinationairport);
SELECT airline, id
FROM route
WHERE airline IN ["UA", "AA"] AND
sourceairport="SFO" AND
destinationairport="JFK" AND
stops == 0
ORDER BY airline;If the partition keys are based on a SQL++ expression, then the query predicate should use the same expression for selecting qualifying partitions.
Case-insensitive lookup for all airlines with non-stop flights from SFO to JFK.
CREATE INDEX idx_pe4 ON route
(LOWER(sourceairport), LOWER(destinationairport), stops, airline, id)
PARTITION BY HASH (LOWER(sourceairport), LOWER(destinationairport))
SELECT airline, id
FROM route
WHERE LOWER(sourceairport)="sfo" AND
LOWER(destinationairport)="jfk" AND
stops == 0
ORDER BY airlineAs with equality predicate in the previous examples, the query engine can select qualifying partitions using an IN clause with matching partitioned keys.
The following example scans at most 3 partitions with sourceairport "SFO", "SJC", or "OAK".
Lookup for all airlines with non-stop flights from SFO, SJC, or OAK to JFK.
CREATE INDEX idx_pe5 ON route
(sourceairport, destinationairport, stops, airline, id)
PARTITION BY HASH (sourceairport, destinationairport);
SELECT airline, id
FROM route
WHERE sourceairport IN ["SFO", "SJC", "OAK"] AND
destinationairport="JFK" AND
stops == 0
ORDER BY airline;As shown in the previous examples, in order to allow the query engine to select qualifying partitions, the partition keys must be present as an equality predicate in the query.
The following query only has an equality predicate on sourceairport and hence will not be able to select the qualifying partitions without destinationairport.
Consequently, this query will gather qualifying index keys from all partitions.
Lookup all airlines with non-stop flights from SFO.
CREATE INDEX idx_pe6 ON route
(sourceairport, destinationairport, stops, airline, id)
PARTITION BY HASH (sourceairport, destinationairport);
SELECT airline, id
FROM route
WHERE sourceairport="SFO" AND
stops == 0
ORDER BY airline;Similarly, the following query gathers qualifying index keys from all partitions as destinationairport IS NOT MISSING is not an equality predicate.
Lookup all airlines with non-stop flights from SFO.
CREATE INDEX idx_pe7 ON route
(sourceairport, destinationairport, stops, airline, id)
PARTITION BY HASH (sourceairport, destinationairport);
SELECT airline, id
FROM route
WHERE sourceairport="SFO" AND
destinationairport is not missing AND
stops == 0
ORDER BY airline;For the query engine to select qualifying partitions, the partition keys must also be a part of the index keys.
The following index always gathers keys from all partitions as destinationairport is not an index key.
Lookup all airlines with flights from SFO to JFK.
CREATE INDEX idx_pe8 ON route
(sourceairport, stops, airline, id)
PARTITION BY HASH (sourceairport, destinationairport);
SELECT airline, id
FROM route
WHERE sourceairport="SFO" AND
destinationairport="JFK"
ORDER BY airline;When choosing partition keys other than the document key, the size of each partition can potentially be subjected to data skew of the chosen partition keys. For example, for the index in the following example, the partitions containing the major airlines would have more entries since more index keys would end up hashing into the same partition.
CREATE INDEX idx ON route
(airline, destinationairport, sourceairport)
PARTITION BY HASH(airline);During index rebalancing, the rebalancer takes into account the data skew among the partitions using runtime statistics. It tries to even out resource utilization across the index service nodes by moving the partitions across the nodes when possible.
Choose Partition Keys for Aggregate Query
As with a range query, when an index is partitioned by document key, an aggregate query can gather the qualifying index keys from all the partitions before performing aggregation in the query engine. Whenever aggregate pushdown optimization is allowed, the query engine will push down partial aggregate calculation to each partition. The query engine then computes the final aggregate result from the partial aggregates across all the partitions. For more information on aggregate query optimization, see Group By and Aggregate Performance.
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find number of flights out of SFO for every destination across all airlines.
CREATE INDEX idx_pe9 ON route
(sourceairport, destinationairport, stops, airline, id, ARRAY_COUNT(schedule))
PARTITION BY HASH (meta().id);
SELECT sourceairport, destinationairport, SUM(ARRAY_COUNT(schedule))
FROM route
WHERE sourceairport = "SFO"
GROUP BY sourceairport, destinationairport;The choice of partition keys can also improve aggregate query performance by enabling the query engine to push down the full aggregate calculation to the index node. In this case, the query engine does not have to recompute the final aggregate result from the index nodes. In addition, certain pushdown optimizations can only be enabled when a full aggregate result is expected from the index node. To enable a full aggregate computation, the index must be created with the following requirements:
-
The expressions in the GROUP BY clause must match the partition keys.
-
The expressions in the GROUP BY clause must match the leading index keys.
-
The partition keys must match the leading index keys.
Find number of flights out of SFO for every destination across all airlines.
CREATE INDEX idx_pe10 ON route
(sourceairport, destinationairport, stops, airline, id, ARRAY_COUNT(schedule))
PARTITION BY HASH (sourceairport, destinationairport);
SELECT sourceairport, destinationairport, SUM(ARRAY_COUNT(schedule))
FROM route
WHERE sourceairport = "SFO"
GROUP BY sourceairport, destinationairport;Number of Partitions
The number of index partitions is fixed when the index is created. By default, each index will have 8 partitions. The Administrator can override the number of partitions at index creation time.
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
CREATE INDEX idx_pe11 ON route
(airline, sourceairport, destinationairport)
PARTITION BY HASH(airline) WITH {"num_partition": 16};Partition Placement
When a partitioned index is created, the partitions are created across available index nodes. During placement of the new index, the index service assumes that each partition has an equal size and places the partitions according to the availability of resources on each node. For example, if an index node has more available free memory than the other nodes, it will assign more partitions to this index node. If the index has a replica, then the replica partition will not be placed onto the same node.
Alternatively, you can specify the node list to restrict the set of nodes available for placement by using a command similar to the following example.
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
CREATE INDEX idx_pe12 ON route
(airline, sourceairport, destinationairport)
PARTITION BY HASH(airline)
WITH {"nodes": ["192.168.10.10:8091", "192.168.10.11:8091"]};When you specify a node list for a partitioned index, the Index Service places the partitions according to the available resources on the specified nodes. For example, if you create an index with 8 partitions and specify a list of 8 nodes, the Index Service does not necessarily place 1 partition on each node. Rather, the Index Service considers the resource usage on each of the specified nodes, and may choose to place the partitions on 4 of them.
If you create a partitioned index on a specific set of nodes, and then decide that you want to specify a different set of nodes for partition placement, you need to remove the partitioned index and then recreate the partitioned index on a smaller or greater number of nodes. However, refer also to the section on rebalancing a partitioned index below.
| To avoid any downtime, before removing the partitioned index, first create an equivalent index for your queries to continue using. |
Sizing Hints
You can optionally provide sizing hints to help place the partitions. Given the sizing hints, the planner uses a formula to estimate the memory and CPU usage of the index. Based on the estimated memory and CPU usage, the planner tries to place the partitions according to the free resources available to each index node.
For a list of sizing hints and example values, see WITH Clause.
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
CREATE INDEX idx_pe13 ON route
(airline, sourceairport, destinationairport)
PARTITION BY HASH (airline) WITH {"secKeySize": 20, "docKeySize": 20};CREATE INDEX idx_pe14 ON route
(airline, sourceairport, schedule)
PARTITION BY HASH (airline) WITH {"secKeySize": 20, "docKeySize": 20, "arrSize": 100};Partition Replica
A partitioned index can be created with multiple replicas to ensure indexes are online despite node failure. if there are multiple server groups in a cluster, replica partitions will be spread out to each server group whenever possible. If one of the server groups is offline, the remaining replica partitions will be available to serve all queries. Every index replica is available to serve queries. Therefore, index replicas can also be used to load rebalancing of query requests.
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
CREATE INDEX idx_pe15 ON route
(airline, sourceairport, schedule)
PARTITION BY HASH (airline) WITH {"num_replica": 2};When an index node fails, any in-flight query requests (serviced by the failed node) will fail since the partial results are already being processed. Any new query requests requiring the lost partition are then serviced by the partitions in the replica.
Rebalance
When new index nodes are added or removed from the cluster, the rebalance operation attempts to move the index partitions across available index nodes in order to balance resource consumptions. At the time of rebalancing, the rebalance operation gathers statistics from each index. These statistics are fed to an optimization algorithm to determine the possible placement of each partition in order to minimize the variation of resource consumption across index nodes.
The rebalancer will only attempt to balance resource consumption on a best try basis. In some situations, the resource consumption cannot be fully balanced. For example:
-
The index service will not try to move the index if the cost to move an index across nodes is too high.
-
A cluster has a mix of non-partitioned indexes and partitioned indexes.
-
The partitions contain skewed data.
In Couchbase Server 7.0 and later, the index redistribution setting enables you to specify how Couchbase Server redistributes indexes on rebalance. For further details, see Rebalancing the Index Service.
Repair Failed Partitions
When an index node fails, the index partitions on that node will be lost. The lost partitions can be recovered or repaired when:
-
The failed node is delta-recovered.
-
The failed node is rebalanced out of the cluster. The lost partitions on that node can be repaired/rebuilt in other index nodes whenever possible. The lost partitions cannot be repaired when the number of remaining nodes is less than or equal to the number of index replicas.
Performance Considerations
Max Parallelism
Along with aggregate pushdown optimization, an application can further enhance the aggregate query performance by computing aggregation in parallel for each partition in the index service.
This can be controlled by specifying the parameter max_parallelism when issuing a query.
Starting with Couchbase Server 6.5, max_parallelism is set by default to match the number of partitions of the index.
When max_parallelism is set to the default value, the index service uses more CPU and memory since the query traffic is increased.
OFFSET Pushdown
When there are more than one qualifying partitions involved in a range query, the query engine will not push down the OFFSET clause to the index service.
Without partition elimination, a partitioned index will have higher overhead for queries with a large OFFSET value.
Alternatively, applications can use keyset based pagination with partitioned index to achieve good pagination query performance, detailed in this blog Database Pagination: Using OFFSET and Keyset in N1QL.
For aggregate queries, the query engine will pushdown the OFFSET clause whenever full aggregate result is expected and there is only 1 qualifying partition involved in the query.
LIMIT Pushdown
When there are more than one qualifying partitions involved in a range query, the query engine will pushdown the LIMIT clause by rewriting it to be the sum of values in the LIMIT clause and OFFSET clause.
For aggregate queries, the query engine will pushdown the LIMIT clause whenever a full aggregate result is expected. When there are more than one qualifying partitions involved in an aggregate query, the query engine will pushdown the LIMIT clause by rewriting it to be the sum of values in the LIMIT clause and OFFSET clause.