ビューの目的はCouchbase Serverデータベースに保存された非構造化、あるいは半構造化のデータから必要なフィールドや情報を抽出し、選択した情報のインデックスを作成することです。Couchbase ServerにJSON形式で情報を保存することで、個々のフィールドを選択して出力する処理が容易になります。結果として生成された構造は、格納されたデータのビューです。この処理によって生成されたビューによって、データベース内に生データオブジェクトとして保存された情報を選択、クエリ、イテレートすることができます。
このプロセスの概要を次の図に示します。
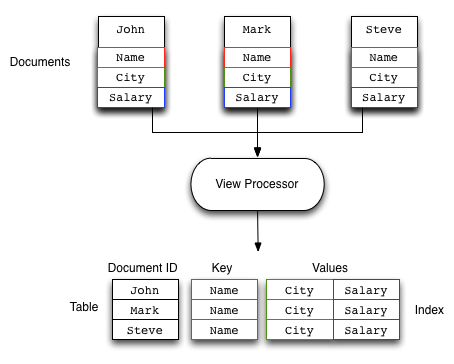
上記の例では、ビューがName, City, Salaryのフィールドを保存されたドキュメントから取得し、各ドキュメントに対応する配列を生成します。Couchbaseのバケットに保存された全てのドキュメントを反復処理し、指定した情報を出力することでビューが作成されます。処理結果のインデックスは後の利用のために保存され、ビューにアクセスした際に、新しく保存されたデータで更新されます。差分のみを処理することで、性能に与える影響を少なくしています。既存の大規模なデータに対して新規のビューを作成すると、構築に長い時間がかかりますが、データの更新には時間はかからないでしょう。
ビューの定義はデータベース内の各ドキュメントから生成する情報のフォーマットと内容を指定します。JSONで保存したフィールドに依存するので、ドキュメントがJSONではない場合や、ビューで要求したフィールドが存在しない場合、その情報は無視されます。これはいくつかのドキュメントが軽微なエラーや関連するフィールドを保持していない場合でも、ビューの作成を可能とするためです。
ドキュメントデータベースの利点のひとつは、アプリケーションに対する大きな変更や、コストのかかるスキーマの更新を事前に必要とせず、データベースに保存するドキュメントのフォーマットをいつでも変更できることです。