Introduction¶
A newer version of this software is available
You are viewing the documentation for an older version of this software. To find the documentation for the current version, visit the Couchbase documentation home page.
Welcome to the official Java SDK documentation. The first section, Getting Started, covers the basic functionality, laying the foundation for the later sections. If you want to see how to build a full-blown application on top of Couchbase, look for the Tutorial section next.
The Using the APIs section holds self-contained reference material about API usage. Go there if you want to dig into topics like storing data, using views and so on. Finally, Advanced Usage contains in-depth information about topics that come up during debugging and production.
Getting Started¶
This section shows you the basics of Couchbase Server and how to interact with it through the Java Client SDK. Here’s a quick outline of what you’ll do in this section:
Create a project in your favorite IDE and set up the dependencies.
Write a simple program that demonstrates how to connect to Couchbase Server and save some documents.
Write a program that demonstrates how to use create, read, update, and delete (CRUD) operations on documents in combination with JSON serialization and deserialization.
Explore some of the API methods that provide more specialized functions.
At this point we assume that you have a Couchbase Server 2.5 release (or later) running and you have the beer-sample bucket configured. If you need help setting up everything, see the following documents:
Using the Couchbase Web Console for information about using the Couchbase Administrative Console
Couchbase CLI for information about the command line interface
Couchbase REST API for information about creating and managing Couchbase resources
The TCP/IP port allocation on Microsoft Windows by default includes a restricted number of ports available for client communication. For more information about this issue, including information about how to adjust the configuration and increase the number of available ports, see MSDN: Avoiding TCP/IP Port Exhaustion.
Preparation¶
To get ready to build your first app, you need to install Couchbase Server, download the Couchbase Java SDK, and set up your IDE.
Installing Couchbase Server
Get the latest Couchbase Server release and install it.
As you follow the download instructions and setup wizard, make sure you install the beer-sample default bucket. It contains beer and brewery sample data, which you use with the examples.
If you already have Couchbase Server 2.5 (or later) but do not have the beer-sample bucket installed, open the Couchbase Web Console and select Settings > Sample Buckets. Select the beer-sample checkbox, and then click Create. A notification box in the upper-right corner disappears when the bucket is ready to use.
Downloading the Couchbase Client Libraries
To include the Client SDK in your project, you can either
manually include all dependencies in your CLASSPATH, or if you want make your life easier, you can use a dependency manager such as Maven. All stable Couchbase-related dependencies are published to the Maven Central Repository.
To include the libraries directly in your project,
download the zip file and add
all the JAR files to your CLASSPATH of the system/project. Most IDEs also allow
you to add specific JAR files to your project. Make sure you add the following
dependencies in your CLASSPATH :
couchbase-client-1.4.11.jar, or latest version available
spymemcached-2.11.7.jar
commons-codec-1.5.jar
httpcore-4.3.jar
netty-3.5.5.Final.jar
httpcore-nio-4.3.jar
jettison-1.1.jar
Previous releases of the 1.4 branch are also available through Maven Central or as a zip archive: * Couchbase Java Client 1.4.10 * Couchbase Java Client 1.4.9 * Couchbase Java Client 1.4.8 * Couchbase Java Client 1.4.7 * Couchbase Java Client 1.4.6 * Couchbase Java Client 1.4.5 * Couchbase Java Client 1.4.4 * Couchbase Java Client 1.4.3 * Couchbase Java Client 1.4.2 * Couchbase Java Client 1.4.1 * Couchbase Java Client 1.4.0
If you use a dependency manager, the syntax varies for each tool. The following examples show how to set up the dependencies when using Maven, sbt (for Scala programs), and Gradle.
To use Maven to include the SDK, add the following dependency to your pom.xml file:
<dependency>
<groupId>com.couchbase.client</groupId>
<artifactId>couchbase-client</artifactId>
<version>1.4.11</version>
</dependency>
If you program in Scala and want to manage your dependencies through sbt, then you can do it with these additions to your build.sbt file:
libraryDependencies += "couchbase" % "couchbase-client" % "1.4.11"
For Gradle you can use the following snippet:
repositories {
mavenCentral()
}
dependencies {
compile "com.couchbase.client:couchbase-client:1.4.11"
}
Now that you have all needed dependencies in the CLASSPATH environment variable, you can set up your IDE.
Setting up your IDE
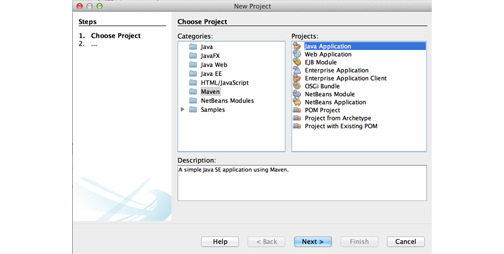
The NetBeans IDE is used in this example, but you can use any other Java-compatible IDE. After you install the NetBeans IDE and open it:
-
Select File > New Project > Maven > Java Application, and then click Next.
-
Enter a name for your new project and change the location to the directory you want.
We named the project “examples.”
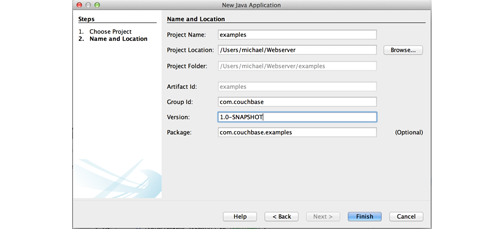
-
Enter a namespace for the project in the Group Id field.
We used the
com.couchbasenamespace for this example, but you can use your own if you like. If you do so, just make sure you change the namespace later in the source files when you copy them from our examples.Now that your project, you can add the Couchbase Maven repository to use the Java SDK.
Click Finish.
In the Projects window, right-click Dependencies > Add Dependency.
-
Enter the following settings to add the Couchbase Java SDK from the Maven repository:
Group ID: com.couchbase.client
Artifact ID: couchbase-client
Version: 1.4.11
For now, you need to add only the Couchbase Java SDK itself because the transitive dependencies are fetched automatically.
Click Add.
Now all the dependencies are in place and you can move forward to your first application with Couchbase.
Hello Couchbase¶
To follow the tradition of first programming tutorials, we start with a “Hello Couchbase” example. In this example, we connect to a Couchbase node, set a simple document, retrieve the document, and then print the value out. This first example contains the full source code, but in later examples we omit the import statements and also assume an existing connection to the cluster.
Listing 1: Hello Couchbase!
package com.couchbase.examples;
import com.couchbase.client.CouchbaseClient;
import java.net.URI;
import java.util.ArrayList;
public class App {
public static void main(String[] args) throws Exception {
ArrayList<URI> nodes = new ArrayList<URI>();
// Add one or more nodes of your cluster (exchange the IP with yours)
nodes.add(URI.create("http://127.0.0.1:8091/pools"));
// Try to connect to the client
CouchbaseClient client = null;
try {
client = new CouchbaseClient(nodes, "default", "");
} catch (Exception e) {
System.err.println("Error connecting to Couchbase: " + e.getMessage());
System.exit(1);
}
// Set your first document with a key of "hello" and a value of "couchbase!"
client.set("hello", "couchbase!").get();
// Return the result and cast it to string
String result = (String) client.get("hello");
System.out.println(result);
// Shutdown the client
client.shutdown();
}
}
The code in Listing 1 is straightforward, but there is a lot going on that is worth a little more discussion:
-
Connect. The
CouchbaseClientclass accepts a list of URIs that point to nodes in the cluster. If your cluster has more than one node, Couchbase strongly recommends that you add at least two or three URIs to the list. The list does not have to contain all nodes in the cluster, but you do need to provide a few nodes so that during the initial connection phase your client can connect to the cluster even if one or more nodes fail.After the initial connection, the client automatically fetches cluster configuration and keeps it up-to-date, even when the cluster topology changes. This means that you do not need to change your application configuration at all when you add nodes to your cluster or when nodes fail. Also make sure you use a URI in this format:
http://[YOUR-NODE]:8091/pools. If you provide only the IP address, your client will fail to connect. We call this initial URI the bootstrap URI.The next two arguments are for the
bucketand thepassword. The bucket is the container for all your documents. Inside a bucket, a key — the identifier for a document — must be unique. In production environments, Couchbase recommends that you use a password on the bucket (this can be configured during bucket creation), but when you are just starting out using thedefaultbucket without a password is fine. The beer-sample bucket also doesn’t have a password, so just change the bucket name and you’re set. -
Set and get. These two operations are the most important ones you will use from a Couchbase SDK. You use
setto create or overwrite a document and you usegetto read it from the server. There are lots of arguments and variations for these two methods, but if you use them as shown in the previous example it will get you pretty far in your application development.Note that the
getoperation will read all types of information, including binary, from the server, so you need to cast it into the data format you want. In our case we knew we stored a string, so it makes sense to convert it back to a string when we get it later. Disconnect when you shutdown your server instance, such as at the end of your application, you should use the
shutdownmethod to prevent loss of data. If you use this method without arguments, it waits until all outstanding operations finish, but does not accept any new operations. You can also call this method with a maximum waiting time that makes sense if you do not want your application to wait indefinitely for a response from the server.
The logger for the Java SDK logs from INFO upwards by default. This means the Java SDK logs a good amount of
information about server communications. From our Hello Couchbase example the
log looks like this:
2014-10-22 09:11:39.498 INFO net.spy.memcached.auth.AuthThread: Authenticated to /127.0.0.1:11210
2014-10-22 09:11:39.512 INFO com.couchbase.client.vbucket.provider.BucketConfigurationProvider: Could bootstrap through carrier publication.
2014-10-22 09:11:39.516 INFO com.couchbase.client.CouchbaseConnection: Added {QA sa=localhost/127.0.0.1:11210, #Rops=0, #Wops=0, #iq=0, topRop=null, topWop=null, toWrite=0, interested=0} to connect queue
2014-10-22 09:11:39.518 INFO com.couchbase.client.CouchbaseClient: CouchbaseConnectionFactory{bucket='beer-sample', nodes=[http://127.0.0.1:8091/pools], order=RANDOM, opTimeout=2500, opQueue=16384, opQueueBlockTime=10000, obsPollInt=10, obsPollMax=500, obsTimeout=5000, viewConns=10, viewTimeout=75000, viewWorkers=1, configCheck=10, reconnectInt=1100, failureMode=Redistribute, hashAlgo=NATIVE_HASH, authWaitTime=2500}
2014-10-22 09:11:39.560 INFO com.couchbase.client.CouchbaseClient: viewmode property isn't defined. Setting viewmode to production mode
2014-10-22 09:11:39.626 INFO net.spy.memcached.auth.AuthThread: Authenticated to localhost/127.0.0.1:11210
2014-10-22 09:11:39.663 INFO com.couchbase.client.CouchbaseConnection: Shut down Couchbase client
2014-10-22 09:11:39.664 INFO com.couchbase.client.ViewConnection: I/O reactor terminated
couchbase!
From the log, you can determine which nodes the client is connected to, see whether views on the server are in development or production mode, and view other helpful output. These logs provide vital information when you need to debug any issues on Couchbase community forums or through Couchbase Customer Support.
Reading Documents¶
With Couchbase Server 2.0 and later, you have two ways of fetching your documents: either
by the unique key through the get method, or through Views. Because Views are
more complex we will discuss them later in this guide. In the meantime, we show
get first:
Object get = client.get("mykey");
Because Couchbase Server stores all types of data, including binary, get returns an object of type Object. If you store JSON documents, the actual document is a
string, so you can safely convert it to a string:
String json = (String) client.get("mykey");
If the server finds no document for that key, it returns a null. It is
important that you check for null in your code, to prevent
NullPointerExceptions later down the stack.
With Couchbase Server 2.0 and later, you can also query for documents with secondary indexes, which we collectively call Views. This feature enables you to provide map functions to extract information and you can optionally provide reduce functions to perform calculations on information. This guide gets you started on how to use views through the Java SDK. If you want to learn more, including how to set up views with Couchbase Web Console, see Using the Views Editor in the Couchbase Server Manual.
This next example assumes you already have a view function set up with
Couchbase Web Console. After you create your View in the Couchbase Web Console, you can
query it from the Java SDK in three steps. First, you get the view definition
from the Couchbase cluster, second you create a Query object and third, you
query the cluster with both the View and the Query objects. In its simplest
form, it looks like this:
// 1: Get the View definition from the cluster
View view = client.getView("beer", "brewery_beers");
// 2: Create the query object
Query query = new Query();
// 3: Query the cluster with the view and query information
ViewResponse result = client.query(view, query);
The getView() method needs both the name of the design document and the name
of the view to load the proper definition from the cluster. The SDK needs them
to determine whether there is a view with the given map functions and also whether it
contains a reduce function or is even a spatial view.
You can query views with several different options. All options are available as
setter methods on the Query object. Here are some of them:
setIncludeDocs(boolean): Use to define if the complete documents should be included in the result.setReduce(boolean): Used to enable/disable the reduce function (if there is one defined on the server).setLimit(int): Limit the number of results that should be returned.setDescending(boolean): Revert the sorting order of the result set.setStale(Stale): Can be used to define the tradeoff between performance and freshness of the data.setDebug(boolean): Prints out debugging information in the logs.
Now that we have our view and the query objects in place, we can
issue the query command, which actually triggers indexing on a Couchbase
cluster. The server returns the results to the Java SDK in the ViewResponse
object. We can use it to iterate over the results and print out some details.
Here is a more complete example, which also includes the full documents and fetches only the first five results:
View view = client.getView("beer", "brewery_beers");
Query query = new Query();
query.setIncludeDocs(true).setLimit(5); // include all docs and limit to 5
ViewResponse result = client.query(view, query);
// Iterate over the result and print the key of each document:
for(ViewRow row : result) {
System.out.println(row.getId());
// The full document (as String) is available through row.getDocument();
}
In the logs, you can see the corresponding document keys automatically sorted in ascending order:
21st_amendment_brewery_cafe
21st_amendment_brewery_cafe-21a_ipa
21st_amendment_brewery_cafe-563_stout
21st_amendment_brewery_cafe-amendment_pale_ale
21st_amendment_brewery_cafe-bitter_american
Deleting Documents¶
If you want to get delete documents, you can use the delete operation:
OperationFuture<Boolean> delete = client.delete("key");
Again, delete is an asynchronous operation and therefore returns a
OperationFuture object on which you can block through the get() method. If you try
to delete a document that is not there, the result of the OperationFuture is false. Be aware that when you delete a document, the server does not
immediately remove a copy of that document from disk, instead it performs lazy
deletion for items that expired or deleted items. For more information about how
the server handles lazy expiration, see About Document
Expiration in the Couchbase Server Developer Guide.
Next Steps¶
You are now ready to start exploring Couchbase Server and the Java SDK on your own. If you want to learn more and see a full-fledged application on top of Couchbase Server 2.5, read the Web Application Tutorial. The Couchbase Server Manual and the Couchbase Developer Guide provide useful information for your day-to-day work with Couchbase Server. You can also look at the Couchbase Java SDK API Reference.
Tutorial¶
This tutorial builds on the foundation introduced in the Getting Started section and evolves the introduced concepts further by implementing a complete web application. Make sure you have the beer-sample bucket installed because the application allows you to display and manage beers and breweries. If you need to get the sample database, see Preparation.
The full source code for the example is available at couchbaselabs on GitHub. The sample application that you can download provides more content than we describe in this tutorial; but it should be easy for you to look around and understand how it functions if you first start reading this tutorial here.
Preview the Application¶
If you want to get up and running really quickly, here is how to do it with Jetty. This guide assumes you are using OS X or Linux. If you are using Windows, you need to modify the paths accordingly. Also, make sure you have Maven installed on your machine.
Download Couchbase Server 2.5 or later and install it. Make sure you install the beer-sample data set when you run the wizard because this tutorial uses it.
-
Add the following views and design documents to the
beer-samplebucket.Views and design documents enable you to index and query data from the database. Later we will publish the views as production views. For more information about using views from an SDK, see Couchbase Developer Guide, Finding Data with Views.
The first design document name is
beerand view name isby_name:function (doc, meta) { if(doc.type && doc.type == "beer") { emit(doc.name, null); } }The other design document name is
breweryand view name isby_name:function (doc, meta) { if(doc.type && doc.type == "brewery") { emit(doc.name, null); } } -
Clone the Java SDK beer repository from GitHub and
cdinto the directory:$ git clone git://github.com/couchbaselabs/beersample-java.git Cloning into ‘beersample-java’… remote: Counting objects: 153, done. remote: Compressing objects: 100% (92/92), done. remote: Total 153 (delta 51), reused 124 (delta 22) Receiving objects: 100% (153/153), 81.97 KiB | 120 KiB/s, done. Resolving deltas: 100% (51/51), done. $ cd beersample-java -
In Maven, run the application inside the Jetty container:
$ mvn jetty:run …. snip …. Dec 17, 2012 1:50:16 PM com.couchbase.beersample.ConnectionManager contextInitialized INFO: Connecting to Couchbase Cluster 2012-12-17 13:50:16.621 INFO com.couchbase.client.CouchbaseConnection: Added {QA sa=/127.0.0.1:11210, #Rops=0, #Wops=0, #iq=0, topRop=null, topWop=null, toWrite=0, interested=0} to connect queue 2012-12-17 13:50:16.624 INFO com.couchbase.client.CouchbaseConnection: Connection state changed for sun.nio.ch.SelectionKeyImpl@2e2a730e 2012-12-17 13:50:16.635 WARN net.spy.memcached.auth.AuthThreadMonitor: Incomplete authentication interrupted for node {QA sa=localhost/127.0.0.1:11210, #Rops=0, #Wops=0, #iq=0, topRop=null, topWop=null, toWrite=0, interested=8} 2012-12-17 13:50:16.662 WARN net.spy.memcached.auth.AuthThread: Authentication failed to localhost/127.0.0.1:11210 2012-12-17 13:50:16.664 INFO net.spy.memcached.auth.AuthThread: Authenticated to localhost/127.0.0.1:11210 2012-12-17 13:50:16.666 INFO com.couchbase.client.ViewConnection: Added localhost to connect queue 2012-12-17 13:50:16.667 INFO com.couchbase.client.CouchbaseClient: viewmode property isn’t defined. Setting viewmode to production mode 2012-12-17 13:50:16.866:INFO::Started SelectChannelConnector@0.0.0.0:8080 [INFO] Started Jetty Server Navigate to http://localhost:8080/welcome and enjoy the application.
Preparing Your Project¶
This tutorial uses Servlets and JSPs in combination with Couchbase Server 2.5 to
display and manage beers and breweries found in the beer-sample data set. The
easiest way to develop apps is by using an IDE such as Eclipse or NetBeans. You
can use the IDE to automatically publish apps to an application server such as
Apache Tomcat or GlassFish as a WAR file. We designed the code here to be as portable as possible, but you might need to change one or two things if you have a slightly different version or a customized setup in your environment.
Project Setup¶
In your IDE, create a new Web Project, either with or without Maven support.
If you have not already gone through the Getting Started section for the Java SDK, you
should review the information on how to include the Couchbase SDK and all the
required dependencies in your project. For more information, see
Preparation.
Also make sure to include Google GSON or your favorite JSON library as well.
This tutorial uses the following directory structure:
|-target
|-src
|---main
|-----java
|-------com
|---------couchbase
|-----------beersample
|-----resources
|-----webapp
|-------WEB-INF
|---------beers
|---------breweries
|---------maps
|---------tags
|---------welcome
|-------css
|-------js
If you use Maven, you should also have a pom.xml file in the root directory. Here is a sample pom.xml so you can see the general structure and dependencies. The full source is at the repository we mentioned earlier. See couchbaselabs on GitHub for the full pom.xml file.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.couchbase</groupId>
<artifactId>beersample-java</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>war</packaging>
<name>beersample-java</name>
<dependencies>
<dependency>
<groupId>com.couchbase.client</groupId>
<artifactId>couchbase-client</artifactId>
<version>1.4.11</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.2.4</version>
</dependency>
<dependency>
<groupId>javax</groupId>
<artifactId>javaee-web-api</artifactId>
<version>6.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
To make the application more interactive, we use jQuery and Twitter Bootstrap. You can either download the libraries and put them in their appropriate css and js directories under the webapp directory, or clone the project repository and use it from there. Either way, make sure you have the following files in place:
css/bootstrap.min.css (the minified twitter bootstrap library)
css/bootstrap-responsive.min.css (the minified responsive layout classes from bootstrap)
From here, you should have a basic web application configured that has all the
dependencies included. We now move on and configure the beer-sample bucket so
we can use it in our application.
Creating Your Views¶
Views enable you to index and query data from your database. The beer-sample bucket comes with a small set of predefined view functions, but to have our application function correctly we need some more views. This is also a very good chance for you to see how you can manage views inside Couchbase Web Console. For more information on the topics, see Couchbase Developer Guide, Finding Data with Views.
Because we want to list beers and breweries by their name, we need to define one view function for each type of result that we want.
In Couchbase Web Console, click Views .
From the drop-down list box, choose the beer-sample bucket.
Click Development Views, and then click Create Development View to define your first view.
-
Give the view the names of both the design document and the actual view. Insert the following names:
Design Document Name:
_design/dev_beerView Name:
by_nameThe next step is to define the
mapfunction and optionally at this phase you could define areducefunction to perform information on the index results. In our example, we do not use thereducefunctions at all, but you can play around with reduce functions ro see how they work. For more information, see Couchbase Developer Guide, Using Built-in Reduce Functions and Creating Custom Reduces. -
Insert the following JavaScript
mapfunction and click Save.function (doc, meta) { if(doc.type && doc.type == "beer") { emit(doc.name, null); } }
Every map function takes the full document ( doc ) and its associated
metadata ( meta ) as the arguments. Your map function can then inspect this
data and emit the item to a result set when you want to have it in your index.
In our case we emit the name of the beer ( doc.name ) when the document has a
type field and the type is beer. For our application we do not need to emit a
value; therefore we emit a null here.
In general, you should try to keep the index as small as possible. You should
resist the urge to include the full document with emit(meta.id, doc), because
it will increase the size of your view indexes and potentially impact application performance. If you need to access the full document or large parts
of it, use the setIncludeDocs(true) directive, which does a get() call with the document ID in the background. Couchbase Server might return a version of
the document that is slightly out of sync with your view, but it will be a fast and efficient operation.
Now we need to provide a similar map function for the breweries. Because you already know how to do this, here is all the information you need to create it:
Design Document Name:
_design/dev_breweryView Name:
by_name-
Map Function:
function (doc, meta) { if(doc.type && doc.type == "brewery") { emit(doc.name, null); } }
The final step is to push the design documents to production mode for Couchbase Server. While the design documents are in development mode, the index is applied only on the local node. See, Couchbase Manual, Development and Production Views. To have the index on the whole data set:
In Couchbase Web Console, click Views.
Click the Publish button on both design documents.
Accept any dialog that warns you from overriding the old view function.
For more information about using views for indexing and querying from Couchbase Server, see the following useful resources:
General Information: Couchbase Server Manual: Views and Indexes.
Sample Patterns: to see examples and patterns you can use for views, see Couchbase Views, Sample Patterns.
Time-stamp Pattern: many developers frequently ask about extracting information based on date or time. To find out more, see Couchbase Views, Sample Patterns.
Bootstrapping Our Servlets¶
To tell the application server where and how the incoming HTTP requests should
be routed, we need to define a web.xml inside the WEB-INF directory of our
project:
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd">
<listener>
<listener-class>com.couchbase.beersample.ConnectionManager</listener-class>
</listener>
<servlet>
<servlet-name>WelcomeServlet</servlet-name>
<servlet-class>com.couchbase.beersample.WelcomeServlet</servlet-class>
</servlet>
<servlet>
<servlet-name>BreweryServlet</servlet-name>
<servlet-class>com.couchbase.beersample.BreweryServlet</servlet-class>
</servlet>
<servlet>
<servlet-name>BeerServlet</servlet-name>
<servlet-class>com.couchbase.beersample.BeerServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>WelcomeServlet</servlet-name>
<url-pattern>/welcome</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>BreweryServlet</servlet-name>
<url-pattern>/breweries/*</url-pattern>
<url-pattern>/breweries</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>BeerServlet</servlet-name>
<url-pattern>/beers/*</url-pattern>
<url-pattern>/beers</url-pattern>
</servlet-mapping>
<welcome-file-list>
<welcome-file>welcome</welcome-file>
</welcome-file-list>
</web-app>
This is not ready to run yet, because you have not implemented any of these classes yet, but we will do that soon. The listener directive references the
ConnectionMananger class, which we implement to manage the connection instance to our Couchbase cluster. The servlet directives define the servlet classes
that we use and the following servlet-mapping directives map HTTP URLs to them. The final welcome-file-list directive tells the application server where to route the root URL ( "/" ).
For now, comment out all servlet, servlet-mapping and welcome-file-list directives with the <!-- and --> tags, because the application server will complain that they are not implemented. When you implement the appropriate servlets, remove the comments accordingly. If you plan to add your own servlets, remember to add and map them inside the web.xml properly!
Managing Connections¶
The first class we implement is the ConnectionManager in the
src/main/java/com/couchbase/beersample directory. This is a
ServletContextListener that starts the CouchbaseClient on application startup and closes the connection when the application shuts down. Here is the
full class:
package com.couchbase.beersample;
public class ConnectionManager implements ServletContextListener {
private static CouchbaseClient client;
private static final Logger logger = Logger.getLogger(
ConnectionManager.class.getName());
@Override
public void contextInitialized(ServletContextEvent sce) {
logger.log(Level.INFO, "Connecting to Couchbase Cluster");
ArrayList<URI> nodes = new ArrayList<URI>();
nodes.add(URI.create("http://127.0.0.1:8091/pools"));
try {
client = new CouchbaseClient(nodes, "beer-sample", "");
} catch (IOException ex) {
logger.log(Level.SEVERE, ex.getMessage());
}
}
@Override
public void contextDestroyed(ServletContextEvent sce) {
logger.log(Level.INFO, "Disconnecting from Couchbase Cluster");
client.shutdown(60, TimeUnit.SECONDS);
}
public static CouchbaseClient getInstance() {
return client;
}
}
In this example, we removed the comments and imports to shorten the listing a bit. The contextInitialized and contextDestroyed methods are called on start-up and shutdown. When the application starts, we initialize the CouchbaseClient with the list of nodes, the bucket name and an empty password. In a production deployment, you want to fetch these environment-dependent settings from a configuration file. We will call the getInstance() method from the servlets to obtain the CouchbaseClient instance.
When you publish your application, you should see in the server logs that the Java SDK correctly connects to the bucket. If you see an exception at this phase, it means that your settings are wrong or you have no Couchbase Server running at the given nodes. Here is an example server log from a successful connection:
INFO: Connecting to Couchbase Cluster
SEVERE: 2012-12-05 14:39:00.419 INFO com.couchbase.client.CouchbaseConnection: Added {QA sa=/127.0.0.1:11210, #Rops=0, #Wops=0, #iq=0, topRop=null, topWop=null, toWrite=0, interested=0} to connect queue
SEVERE: 2012-12-05 14:39:00.426 INFO com.couchbase.client.CouchbaseConnection: Connection state changed for sun.nio.ch.SelectionKeyImpl@1b554a4
SEVERE: 2012-12-05 14:39:00.458 INFO net.spy.memcached.auth.AuthThread: Authenticated to localhost/127.0.0.1:11210
SEVERE: 2012-12-05 14:39:00.487 INFO com.couchbase.client.ViewConnection: Added localhost to connect queue
SEVERE: 2012-12-05 14:39:00.489 INFO com.couchbase.client.CouchbaseClient: viewmode property isn't defined. Setting viewmode to production mode
INFO: WEB0671: Loading application [com.couchbase_beersample-java_war_1.0-SNAPSHOT] at [/]
INFO: com.couchbase_beersample-java_war_1.0-SNAPSHOT was successfully deployed in 760 milliseconds.
The Welcome Page¶
The first servlet that we implement is the WelcomeServlet, so go ahead and remove the appropriate comments inside the web.xml file. You also want to enable the welcome-file-list at this point. When a user visits the application, we show him a nice greeting and give him all available options to choose.
Because there is no Couchbase Server interaction involved, we just tell it to render the JSP template:
package com.couchbase.beersample;
public class WelcomeServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
request.getRequestDispatcher("/WEB-INF/welcome/index.jsp")
.forward(request, response);
}
}
The index.jsp file uses styling from Twitter bootstrap to provide a clean layout. Aside from that, it shows a nice greeting and links to the servlets that provide the actual functionality:
<%@taglib prefix="t" tagdir="/WEB-INF/tags" %>
<%@page contentType="text/html" pageEncoding="UTF-8"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
<t:layout>
<jsp:body>
<div class="span6">
<div class="span12">
<h4>Browse all Beers</h4>
<a href="/beers" class="btn btn-warning">Show me all beers</a>
<hr />
</div>
<div class="span12">
<h4>Browse all Breweries</h4>
<a href="/breweries" class="btn btn-info">Take me to the breweries</a>
</div>
</div>
<div class="span6">
<div class="span12">
<h4>About this App</h4>
<p>Welcome to Couchbase!</p>
<p>This application helps you to get started on application
development with Couchbase. It shows how to create, update and
delete documents and how to work with JSON documents.</p>
<p>The official tutorial can be found
<a href="http://www.couchbase.com/docs/couchbase-sdk-java-1.1/tutorial.html">here</a>!</p>
</div>
</div>
</jsp:body>
</t:layout>
There is one more interesting note to make here: it uses taglibs, which enables us to use the same layout for all pages. Because we have not created this layout, we do so now. Create the following layout.tag file in the /WEB-INF/tags directory:
<%@tag description="Page Layout" pageEncoding="UTF-8"%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Couchbase Java Beer-Sample</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta name="description" content="The Couchbase Java Beer-Sample App">
<meta name="author" content="Couchbase, Inc. 2012">
<link href="/css/bootstrap.min.css" rel="stylesheet">
<link href="/css/beersample.css" rel="stylesheet">
<link href="/css/bootstrap-responsive.min.css" rel="stylesheet">
<!-- HTML5 shim, for IE6-8 support of HTML5 elements -->
<!--[if lt IE 9]>
<script src="http://html5shim.googlecode.com/svn/trunk/html5.js"></script>
<![endif]-->
</head>
<body>
<div class="container-narrow">
<div class="masthead">
<ul class="nav nav-pills pull-right">
<li><a href="/welcome">Home</a></li>
<li><a href="/beers">Beers</a></li>
<li><a href="/breweries">Breweries</a></li>
</ul>
<h2 class="muted">Couchbase Beer-Sample</h2>
</div>
<hr>
<div class="row-fluid">
<div class="span12">
<jsp:doBody/>
</div>
</div>
<hr>
<div class="footer">
<p>© Couchbase, Inc. 2012</p>
</div>
</div>
<script src="/js/jquery.min.js"></script>
<script src="/js/bootstrap.min.js"></script>
<script src="/js/beersample.js"></script>
</body>
</html>
Again, nothing fancy here. We just need it in place to make everything look clean afterwards. When you deploy your application, you should see in the logs that it is connects to the Couchbase cluster, and when you view it in the browser you should see a nice web page greeting.
Managing Beers¶
Now we reach the main portion of the tutorial where we actually interact with Couchbase Server. First, we uncomment the BeerServlet and its corresponding tags inside the web.xml file. We make use of the view to list all beers and make them easily searchable. We also provide a form to create, edit, or delete beers.
Here is the bare structure of our BeerServlet, which will be filled with live data soon. Once again, we removed comments and imports for the sake of brevity:
package com.couchbase.beersample;
public class BeerServlet extends HttpServlet {
final CouchbaseClient client = ConnectionManager.getInstance();
final Gson gson = new Gson();
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
try {
if(request.getPathInfo() == null) {
handleIndex(request, response);
} else if(request.getPathInfo().startsWith("/show")) {
handleShow(request, response);
} else if(request.getPathInfo().startsWith("/delete")) {
handleDelete(request, response);
} else if(request.getPathInfo().startsWith("/edit")) {
handleEdit(request, response);
} else if(request.getPathInfo().startsWith("/search")) {
handleSearch(request, response);
}
} catch (InterruptedException ex) {
Logger.getLogger(BeerServlet.class.getName()).log(
Level.SEVERE, null, ex);
} catch (ExecutionException ex) {
Logger.getLogger(BeerServlet.class.getName()).log(
Level.SEVERE, null, ex);
}
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
}
private void handleIndex(HttpServletRequest request,
HttpServletResponse response) throws IOException, ServletException {
}
private void handleShow(HttpServletRequest request,
HttpServletResponse response) throws IOException, ServletException {
}
private void handleDelete(HttpServletRequest request,
HttpServletResponse response) throws IOException, ServletException,
InterruptedException,
ExecutionException {
}
private void handleEdit(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException {
}
private void handleSearch(HttpServletRequest request,
HttpServletResponse response) throws IOException, ServletException {
}
}
Because our web.xml file uses wildcards ( * ) to route every /beer that is
related to this servlet, we need to inspect the path through getPathInfo() and dispatch the request to a helper method that does the actual work. We use the
doPost() method to analyze and store the results of the web form. We also use
this method to edit and create new beers because we sent the form through a POST
request.
The first functionality we implement is a list of the top 20 beers in a table.
We can use the beer/by_name view we created earlier to get a sorted list of all beers. The following Java code belongs to the handleIndex method and builds the list:
// Fetch the View
View view = client.getView("beer", "by_name");
// Set up the Query object
Query query = new Query();
// We the full documents and only the top 20
query.setIncludeDocs(true).setLimit(20);
// Query the Cluster
ViewResponse result = client.query(view, query);
// This ArrayList will contain all found beers
ArrayList<HashMap<String, String>> beers = new ArrayList<HashMap<String, String>>();
// Iterate over the found documents
for(ViewRow row : result) {
// Use Google GSON to parse the JSON into a HashMap
HashMap<String, String> parsedDoc = gson.fromJson((String)row.getDocument(), HashMap.class);
// Create a HashMap which will be stored in the beers list.
HashMap<String, String> beer = new HashMap<String, String>();
beer.put("id", row.getId());
beer.put("name", parsedDoc.get("name"));
beer.put("brewery", parsedDoc.get("brewery_id"));
beers.add(beer);
}
// Pass all found beers to the JSP layer
request.setAttribute("beers", beers);
// Render the index.jsp template
request.getRequestDispatcher("/WEB-INF/beers/index.jsp")
.forward(request, response);
The index action in the code above queries the view, parses the results with
GSON into a HashMap object and eventually forwards the ArrayList to the JSP layer. At this point we can implement the index.jsp template which iterates over the ArrayList and prints out the beers in a nicely formatted table:
<%@taglib prefix="t" tagdir="/WEB-INF/tags" %>
<%@page contentType="text/html" pageEncoding="UTF-8"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
<t:layout>
<jsp:body>
<h3>Browse Beers</h3>
<form class="navbar-search pull-left">
<input id="beer-search" type="text" class="search-query" placeholder="Search for Beers">
</form>
<table id="beer-table" class="table table-striped">
<thead>
<tr>
<th>Name</th>
<th>Brewery</th>
<th></th>
</tr>
</thead>
<tbody>
<c:forEach items="${beers}" var="beer">
<tr>
<td><a href="/beers/show/${beer.id}">${beer.name}</a></td>
<td><a href="/breweries/show/${beer.brewery}">To Brewery</a></td>
<td>
<a class="btn btn-small btn-warning" href="/beers/edit/${beer.id}">Edit</a>
<a class="btn btn-small btn-danger" href="/beers/delete/${beer.id}">Delete</a>
</td>
</tr>
</c:forEach>
</tbody>
</table>
</jsp:body>
</t:layout>
Here we use JSP tags to iterate
over the beers and use their properties, name and id, and fill the table rows with this information. In a browser you should now see a table with a list of beers with Edit and Delete buttons on the right. You can also see a link to the associated brewery that you can click on. Now we implement the delete action for each beer, because it’s very easy to do with Couchbase:
private void handleDelete(HttpServletRequest request,
HttpServletResponse response) throws IOException, ServletException, InterruptedException, ExecutionException {
// Split the Request-Path and get the Beer ID out of it
String beerId = request.getPathInfo().split("/")[2];
// Try to delete the document and store the OperationFuture
OperationFuture<Boolean> delete = client.delete(beerId);
// If the Future succeeded (returned true), redirect to /beers
if(delete.get()) {
response.sendRedirect("/beers");
}
}
The delete method deletes a document from the cluster based on the given document key. Here, we wait on the OperationFuture to return from the get() method and if the server successfully deletes the item we get true and can redirect to the index action.
Now that we can delete a document, we want to enable users to edit beers. The edit action is very similar to the delete action, but it reads and updates the document based on the given ID instead of deleting it. Before we can edit a beer, we need to parse the string representation of the JSON document into a Java structure so we can use it in the template. We again make use of the Google GSON library to handle this for us:
private void handleEdit(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException {
// Extract the Beer ID from the URL
String[] beerId = request.getPathInfo().split("/");
// If there is a Beer ID
if(beerId.length > 2) {
// Read the Document (as a JSON string)
String document = (String) client.get(beerId[2]);
HashMap<String, String> beer = null;
if(document != null) {
// Convert the String into a HashMap
beer = gson.fromJson(document, HashMap.class);
beer.put("id", beerId[2]);
// Forward the beer to the view
request.setAttribute("beer", beer);
}
request.setAttribute("title", "Modify Beer \"" + beer.get("name") + "\""); } else {
request.setAttribute("title", "Create a new beer");
}
request.getRequestDispatcher("/WEB-INF/beers/edit.jsp").forward(request, response);
}
If the handleEdit method gets a beer document back from Couchbase Server and parses it into JSON, the document is converted to a HashMap object and then forwarded to the edit.jsp template. Also, we define a title variable that we use inside the template to determine whether we want to edit a document or create a new one. We can enable users to create new beers as opposed to editing an existing beer anytime we pass no Beer ID to the edit method. Here is the corresponding edit.jsp template:
<%@taglib prefix="t" tagdir="/WEB-INF/tags" %>
<%@page contentType="text/html" pageEncoding="UTF-8"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
<t:layout>
<jsp:body>
<h3>${title}</h3>
<form method="post" action="/beers/edit/${beer.id}">
<fieldset>
<legend>General Info</legend>
<div class="span12">
<div class="span6">
<label>Name</label>
<input type="text" name="beer_name" placeholder="The name of the beer." value="${beer.name}">
<label>Description</label>
<input type="text" name="beer_description" placeholder="A short description." value="${beer.description}">
</div>
<div class="span6">
<label>Style</label>
<input type="text" name="beer_style" placeholder="Bitter? Sweet? Hoppy?" value="${beer.style}">
<label>Category</label>
<input type="text" name="beer_category" placeholder="Ale? Stout? Lager?" value="${beer.category}">
</div>
</div>
</fieldset>
<fieldset>
<legend>Details</legend>
<div class="span12">
<div class="span6">
<label>Alcohol (ABV)</label>
<input type="text" name="beer_abv" placeholder="The beer's ABV" value="${beer.abv}">
<label>Biterness (IBU)</label>
<input type="text" name="beer_ibu" placeholder="The beer's IBU" value="${beer.ibu}">
</div>
<div class="span6">
<label>Beer Color (SRM)</label>
<input type="text" name="beer_srm" placeholder="The beer's SRM" value="${beer.srm}">
<label>Universal Product Code (UPC)</label>
<input type="text" name="beer_upc" placeholder="The beer's UPC" value="${beer.upc}">
</div>
</div>
</fieldset>
<fieldset>
<legend>Brewery</legend>
<div class="span12">
<div class="span6">
<label>Brewery</label>
<input type="text" name="beer_brewery_id" placeholder="The brewery" value="${beer.brewery_id}">
</div>
</div>
</fieldset>
<div class="form-actions">
<button type="submit" class="btn btn-primary">Save changes</button>
</div>
</form>
</jsp:body>
</t:layout>
This template is a little bit longer, but that is mainly because we have lots of fields on our beer documents. Note how we use the beer attributes inside the value attributes of the HTML input fields. We also use the unique ID in the form method to dispatch it to the correct URL on submit.
The last thing we need to do for form submission to work is the actual form parsing and storing itself. Since we do form submission through a POST request, we need to implement the doPost() method on our servlet:
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// Parse the Beer ID
String beerId = request.getPathInfo().split("/")[2];
HashMap<String, String> beer = beer = new HashMap<String, String>();
Enumeration<String> params = request.getParameterNames();
// Iterate over all POST params
while(params.hasMoreElements()) {
String key = params.nextElement();
if(!key.startsWith("beer_")) {
continue;
}
String value = request.getParameter(key);
// Store them in a HashMap with key and value
beer.put(key.substring(5), value);
}
// Add two more fields
beer.put("type", "beer");
beer.put("updated", new Date().toString());
// Set (add or override) the document (converted to JSON with GSON)
client.set(beerId, 0, gson.toJson(beer));
// Redirect to the show page
response.sendRedirect("/beers/show/" + beerId);
}
The code iterates over all POST fields and stores them in a HashMap object. We then
use the set command to store the document to Couchbase Server and use Google
GSON to translate information out of the HashMap object into a JSON string. In this case, we could also wait for a OperationFuture response and return an error if we determine the set failed.
The last line redirects to a show method, which just shows all fields of the document. Because the patterns are the same as before, here is the handleShow method:
private void handleShow(HttpServletRequest request,
HttpServletResponse response) throws IOException, ServletException {
// Extract the Beer ID
String beerId = request.getPathInfo().split("/")[2];
String document = (String) client.get(beerId);
if(document != null) {
// Parse the JSON and set it for the template if a document was found
HashMap<String, String> beer = gson.fromJson(document, HashMap.class);
request.setAttribute("beer", beer);
}
// render the show.jsp template
request.getRequestDispatcher("/WEB-INF/beers/show.jsp")
.forward(request, response);
}
Again we extract the ID and if Couchbase Server finds the document it gets parsed into a HashMap and forwarded to the show.jsp template. If the server finds no document, we get a return of null in the Java SDK. The template then just prints out all keys and values in a table:
<%@taglib prefix="t" tagdir="/WEB-INF/tags" %>
<%@page contentType="text/html" pageEncoding="UTF-8"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
<t:layout>
<jsp:body>
<h3>Show Details for Beer "${beer.name}"</h3>
<table class="table table-striped">
<tbody>
<c:forEach items="${beer}" var="item">
<tr>
<td><strong>${item.key}</strong></td>
<td>${item.value}</td>
</tr>
</c:forEach>
</tbody>
</table>
</jsp:body>
</t:layout>
In the index.jsp template, you might notice the search box at the top. We can use it to dynamically filter our table results based on the user input. We will use nearly the same code for the filter as in the index method; except this time we make use of range queries to define a beginning and end to search for. For more information about performing range queries, see Ordering.
Before we implement the actual Java method, we need to put the following snippet in the js/beersample.js file. You might have already done this at the beginning of the tutorial, and if so, you can skip this step. This code takes any search box changes from the UI and updates the table with the JSON returned from the search method:
$("#beer-search").keyup(function() {
var content = $("#beer-search").val();
if(content.length >= 0) {
$.getJSON("/beers/search", {"value": content}, function(data) {
$("#beer-table tbody tr").remove();
for(var i=0;i < data.length; i++) {
var html = "<tr>";
html += "<td><a href=\"/beers/show/"+data[i].id+"\">"+data[i].name+"</a></td>";
html += "<td><a href=\"/breweries/show/"+data[i].brewery+"\">To Brewery</a></td>";
html += "<td>";
html += "<a class=\"btn btn-small btn-warning\" href=\"/beers/edit/"+data[i].id+"\">Edit</a>\n";
html += "<a class=\"btn btn-small btn-danger\" href=\"/beers/delete/"+data[i].id+"\">Delete</a>";
html += "</td>";
html += "</tr>";
$("#beer-table tbody").append(html);
}
});
}
});
The code waits for key-up events on the search field and then does an AJAX query to the search method on the servlet. The servlet computes the result and sends it back as JSON. The JavaScript then clears the table, iterates over the result, and creates new rows with the new JSON results. The search method looks like this:
private void handleSearch(HttpServletRequest request, HttpServletResponse response) throws IOException, ServletException {
// Exctract the searched value
String startKey = request.getParameter("value").toLowerCase();
// Prepare a query against the by_name view
View view = client.getView("beer", "by_name");
Query query = new Query();
// Define the query params
query.setIncludeDocs(true) // include the full documents
.setLimit(20) // only show 20 results
.setRangeStart(ComplexKey.of(startKey)) // Start the search at the given search value
.setRangeEnd(ComplexKey.of(startKey + "\uefff")); // End the search at the given search plus the unicode "end"
// Query the view
ViewResponse result = client.query(view, query);
ArrayList<HashMap<String, String>> beers = new ArrayList<HashMap<String, String>>();
// Iterate over the results
for(ViewRow row : result) {
// Parse the Document to a HashMap
HashMap<String, String> parsedDoc = gson.fromJson((String)row.getDocument(), HashMap.class);
// Create a new Beer out of it
HashMap<String, String> beer = new HashMap<String, String>();
beer.put("id", row.getId());
beer.put("name", parsedDoc.get("name"));
beer.put("brewery", parsedDoc.get("brewery_id"));
beers.add(beer);
}
// Return a JSON representation of all Beers
response.setContentType("application/json");
PrintWriter out = response.getWriter();
out.print(gson.toJson(beers));
out.flush();
}
You can use the setRangeStart() and setRangeEnd() methods to define the key range Couchbase Server returns. If we just provide the start range key, then we
get all documents starting from our search value. Because we want only those beginning with the search value, we can use the special "\uefff" UTF-8 character at the end, which means “end here.” You need to get used to this convention, but it’s very fast and efficient when accessing the view.
Wrapping Up¶
The tutorial presents an easy approach to start a web application with Couchbase Server as the underlying data source. If you want to dig a little bit deeper, see the full source code at couchbaselabs on GitHub. This contains more servlets and code to learn from. This might be extended and updated from time to time, so you might want to watch the repo.
Of course this is only the starting point for Couchbase, but together with the Getting Started Guide and other community resources you are well equipped to start exploring Couchbase Server on your own. Have fun working with Couchbase!
Using the APIs¶
The Client libraries provides an interface to both Couchbase and Memcached
buckets using a consistent interface. The interface between your Java
application and your Couchbase cluster is provided through the
instantiation of a single class, the CouchbaseClient.
Creating a new object based on this class opens connections to each configured server in the cluster and handles all the communication with the servers when setting, retrieving and updating values. A number of different methods are available for creating the object specifying the connection address and methods.
Connecting to a Couchbase Bucket¶
You can connect to specific Couchbase buckets (in place of using the default
bucket or a hostname:port combination configured on the Couchbase cluster) by
using the Couchbase URI for one or more Couchbase nodes and specifying the
bucket name and password (if required) when creating the new CouchbaseClient
object.
For example, to connect to localhost and the default bucket:
List<URI> uris = new ArrayList<URI>();
uris.add(URI.create("http://127.0.0.1:8091/pools"));
try {
client = new CouchbaseClient(uris, "default", "");
} catch (Exception e) {
System.err.println("Error connecting to Couchbase: " + e.getMessage());
System.exit(0);
}
The format of this constructor is:
CouchbaseClient client = new CouchbaseClient(List<URI> uris, String bucket, String password);
Where:
URIsis a list of URIs to the Couchbase nodes. The format of the URI is the hostname, port and path/pools. Note that in production systems, you should always pass in more than one node. It doesn’t have to be all nodes in the cluster, but in case one of the given bootstrap nodes is down you will still be able to connect to the cluster initially.bucketis the name of the bucket on the cluster that you want to use. Specified as aString. Note that this is not the administrator username.passwordis the password for this bucket. Specified as aString. Note that this is not the administrator password. If no password is used, specify an empty string.
Setting runtime Parameters for the CouchbaseConnectionFactoryBuilder¶
A more custom approach to creating the connection is using the
CouchbaseConnectionFactoryBuilder.
It’s possible to override some of the default parameters that are defined in
CouchbaseConnectionFactoryBuilder for a variety of reasons and customize the
connection for the session depending on expected load on the server and
potential network traffic.
For example, in the following program snippet, we instantiate a new
CouchbaseConnectionFactoryBuilder and use the setOpTimeout method to change
the default value to 10000 ms (10 seconds).
We subsequently use the buildCouchbaseConnection specifying the bucket name,
password and an username (which is not being used any more) to get a
CouchbaseConnectionFactory object. We then create a CouchbaseClient object.
List<URI> baseURIs = new ArrayList<URI>();
baseURIs.add(base);
CouchbaseConnectionFactoryBuilder cfb = new CouchbaseConnectionFactoryBuilder();
// Ovveride default values on CouchbaseConnectionFactoryBuilder
// For example - wait up to 10 seconds for an operation to succeed
cfb.setOpTimeout(10000);
CouchbaseConnectionFactory cf = cfb.buildCouchbaseConnection(baseURIs, "default", "");
client = new CouchbaseClient(cf);
The following table summarizes the parameters that you can set. The table provides the parameter name, a brief description, the default value, and why the particular parameter might need to be modified.
| Parameter | Description | Default | When to Override the default value |
|---|---|---|---|
opTimeout |
Time in milliseconds for an operation to time out | 2500 ms | You can set this value higher when there is heavy network traffic and timeouts happen frequently. |
timeoutExceptionThreshold |
Number of operations to time out before the node is deemed down | 998 | You can set this value lower to deem a node is down earlier. |
readBufSize |
Read buffer size | 16384 | You can set this value higher or lower to optimize the reads. |
opQueueMaxBlockTime |
The maximum time to block waiting for op queue operations to complete, in milliseconds. | 10000 ms | The default has been set with the expectation that most requests are interactive and waiting for more than a few seconds is thus more undesirable than failing the request. However, this value could be lowered for operations not to block for this time. |
shouldOptimize |
Optimize behavior for the network | False | You can set this value to be true if the performance should be optimized for the network as in cases where there are some known issues with the network that may be causing adverse effects on applications. |
maxReconnectDelay |
Maximum number of milliseconds to wait between reconnect attempts. | 30000 ms | You can set this value lower when there is intermittent and frequent connection failures. |
MinReconnectInterval |
Default minimum reconnect interval in milliseconds | 1100 | This means that if a reconnect is needed, it won’t try to reconnect more frequently than the default value. The internal connections take up to 500 ms per request. You can set this value higher to try reconnecting less frequently. |
obsPollInterval |
Wait for the specified interval before the observe operation polls the nodes. | 400 | Set this higher or lower depending on whether the polling needs to happen less or more frequently depending on the tolerance limits for the observe operation as compared to other operations. |
obsPollMax |
The maximum number of times to poll the master and replicas to meet the desired durability requirements. | 10 | You could set this value higher if the observe operations do not complete after the normal polling. |
Shutting down the Connection¶
The preferred method for closing a connection is to cleanly shut down the active
connection with a timeout using the shutdown() method with an timeout
period and unit specification. The following example shuts down the active connection
to all the configured servers and waits a minute to drain all the internal queues and complete operations, while not accepting new incoming operations:
client.shutdown(60, TimeUnit.SECONDS);
The method returns a Boolean value that indicates whether the shutdown request completed successfully.
You also can shut down an active connection immediately by using the shutdown() method to your Couchbase object instance. This is not recommended though since it doesn’t give the underlying queues a chance to drain and therefore may lead to a “unclean” shutdown.
client.shutdown();
Understanding and Using Asynchronous Operations¶
For all important operations, the Couchbase Java SDK exposes both asynchronous and synchronous methods to the user application. Nearly always, the synchronous methods are wrappers around their asynchronous counterparts. You can identify those methods easily, because they return a future of some kind: OperationFuture, GetFuture, ViewFuture and so on.
Why do we need those constructs at all and not just stick with a purely synchronous style? Asynchronous programming as a principle (and the concept of futures or closures/anonymous classes as their vehicle to implement it) allows you to write applications that are more performant, provide better throughput, lower latency and ultimately lead to higher resource utilization (for example, the number of CPU cores concurrently used in the application server).
While this is all good, the ideas and concepts used to implement such behavior don’t go well with traditional-style java programming. That said, after you understand these concepts, you can safely apply them to any program you write (not just Couchbase Java SDK programs).
If a method returns a Future<T>, it means that the method you call does not wait until the response is computed, but instead your thread immediately gets the control back. The future will contain the result of the computation eventually. Getting control back immediately is a good thing because you are then free to do something else until the result is computed. This is especially important if you are dealing with I/O of some form (such as disk or network), because the time spent on I/O is significant. CPUs and RAM are much faster than disks or the network, so using your resources in a meaningful way instead of waiting is a good thing.
Here’s the Future interface that is delivered with the JDK:
public interface Future<V> {
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
}
The interface clearly defines the contract that a Future has, which sets the tone for the upcoming examples and principles. If you call get() on a future, it blocks your current thread (similar to a synchronous method) until the result is computed. If you call asyncMethod().get(), you basically turned it into a synchronous call. The overloaded get(long, TimeUnit) method is intended so that you can provide a custom time until a TimeoutException is raised for example. When using the Couchbase Java SDK, the plain get() method will use the configured default timeout.
You can also proactively cancel() a future, which means that the underlying task will not be computed if it has not been started. If it has already been computed, this method will fail (or just be ignored). You can also check if the future is cancelled through the isCancelled() method, and check if it is already done through isDone(). Both methods are non-blocking, which means they return the current state without waiting for it to change.
With this in mind, take a look at a corresponding method in the Couchbase Java SDK, the CouchbaseClient.set() method:
// Doing a asynchronous set, returning immediately (maybe even before it has been sent out to the server)
OperationFuture<Boolean> future = client.set("key", "value");
// Wait until the response is returned (blocks the current thread!)
boolean success = future.get(); // or with custom timeout
// Check if its done already
boolean isDone = future.isDone();
// Check if it has been cancelled
boolean isCancelled = future.isCancelled();
The generic type boolean in this case indicates whether the operation succeeded. The OperationFuture has much more information associated with it, but the general principle applies. A lot of those methods can return exceptions in various ways. For information about handling those exceptions, see the going to production and troubleshooting sections.
SDK Futures¶
The Couchbase Java SDK and the underlying spymemcached library implement a variety of future types, which are dependent on their usage. If you are mutating values, you will come across the OperationFuture<T>, which is the most common one. In addition to the methods already described, you need to know
about the following methods (there are others exposed as well, but they are generally for internal use and should not be used by the application directly):
-
String getKey(): Returns the key for this operation -
Long getCas(): Returns the current CAS value for the document (which has changed after the mutation, for example) -
OperationStatus getStatus(): Contains theOperationStatus, which gives you more insight into what happened in case of a failure.
Due to the nature of the last two methods, those are blocking, which means they call get() first. If you want to use them with a different timeout than the default one, make sure to manually execute get(long, TimeUnit) first.
The following futures are related to get requests: GetFuture and BulkGetFuture. They get returned from get(String key,...) requests (retrieving documents)—do not confuse them with the general .get() method to block on the future. For all practical purposes, you can think of the GetFuture method as a OperationFuture, but it doesn’t give you access to the key and the CAS value. This is because of historical reasons, but you can use the client.asyncGets to get the CAS value nevertheless.
The BulkGetFuture class provides an additional method: getSome(long, TimeUnit). To understand it, you need to know that if you call .get() on a bulk future, it waits until either all documents are returned or the timeout is reached. Now if only one of the requested documents does not return in the time interval, the whole thing times out. Because sometimes you can live with just the documents that got returned until the timeout is reached, you can use the getSome method for this alternative behavior. If you are dealing with replica reads, you also come across a ReplicaGetFuture. Treat it exactly like a GetFuture.
If you are curious about the internal differences: Because the client sends multiple get requests to all replica nodes when a getFromReplica() is issued, a ReplicaGetFuture needs to keep track of those to find out the correct one that returns. A GetFuture only has to keep track of exactly one request.
When dealing with views and design documents, you get both HttpFuture and ViewFuture objects returned. Because the ViewFuture is a specialized version of the HttpFuture, you can treat them the same. They also expose a getStatus() method that facilitates better error handling.
While there are many future implementations around, they all work mostly the same but just differ with their internal implementation in terms of what they have to do and what underlying operations they facilitate.
Understanding and working with Listeners¶
Even if the Java SDK returns futures, most of the times your application is designed in a synchronous fashion. This is true especially in environments like servlets or traditional Spring applications. Reactive programming and fully asynchronous web stacks are becoming more popular though. For an example, take a look at the Play Framework.
Also, a common use case is to perform a database operation (like a get request), and then doing something with it. Writing code like this doesn’t buy you much (because synchronous behavior is forced through the .get() call):
Object document = client.asyncGet("key").get();
modifyAndReturnToUser(document);
To use resources better, you can do the corresponding modification right after the object is returned, but you actually don’t need to care when that is. The SDK calls you back after the response is here from the database. Therefore, you can add a callback to the future. A callback is also known as a listener. The following example is completely asynchronous version of the previous example:
client.asyncGet("key").addListener(new GetCompletionListener() {
@Override
public void onComplete(GetFuture<?> future) throws Exception {
modifyAndReturnToUser(future.get());
}
});
The callback is executed after the result is returned, and whatever you put in the onComplete method is executed in a different thread. You are still calling .get() on the future to get the result returned, but because you know this is already the case it is an “instant” operation.
To get the true power out of callbacks, you can nest them to build a completely asynchronous computation chain:
client.asyncGet("key").addListener(new GetCompletionListener() {
@Override
public void onComplete(GetFuture<?> future) throws Exception {
Object document = future.get();
modifyDocument(document);
client.set("key", document).addListener(new OperationCompletionListener() {
@Override
public void onComplete(OperationFuture<?> future) throws Exception {
System.out.println("I'm done!");
}
});
}
});
Both callbacks are executed in different threads in a thread pool. This looks a bit ugly because with Java 6 and 7, the only way to implement this kind of behavior is with anonymous classes (*CompletionListener). We can bring some Java 8 love to it with lambda expressions and
make it much more concise (similar constructs can also be used from languages like Scala and Groovy):
client.asyncGet("key").addListener(getFuture -> {
Object document = getFuture.get();
modifyDocument(document);
client.set("key", document).addListener(setFuture -> {
System.out.println("I'm done!");
});
});
If you want to run this example in a traditional synchronous application, you are in trouble if you want to compute the result asynchronously, but make the calling thread wait for a result at some point (because you might need to pass a response back to the user). For this purpose, the CountDownLatch of the java concurrent package comes in handy. It is part of the JDK, so it is always accessible to you.
This example modifies the previous example to make the calling thread wait for the asynchronous computation (still using Java 8 here to make the code samples shorter, but the same concepts apply to Java 6 and 7 and anonymous classes):
CountDownLatch latch = new CountDownLatch(1);
client.asyncGet("key").addListener(getFuture -> {
Object document = getFuture.get();
modifyDocument(document);
client.set("key", document).addListener(setFuture -> {
System.out.println("I'm done!");
latch.countDown();
});
});
boolean success = latch.await(10, TimeUnit.SECONDS);
The calling thread waits until the latch is counted down to 0, which eventually happens after the set call. If it does not get counted down (in case of a failure for example), then after 10 seconds success will be false and you can act upon it correctly. You still need a way to get the computed result out of the callback chain and back to the calling thread. Because the latch doesn’t carry much information, you need to add an additional construct (also from the concurrent package): the AtomicReference. Say you want to grab the OperationStatus from the set response and pass it up the stack for further investigation:
CountDownLatch latch = new CountDownLatch(1);
AtomicReference<OperationStatus> reference = new AtomicReference<>();
client.asyncGet("key").addListener(getFuture -> {
Object document = getFuture.get();
modifyDocument(document);
client.set("key", document).addListener(setFuture -> {
reference.set(setFuture.getStatus());
latch.countDown();
});
});
boolean success = latch.await(10, TimeUnit.SECONDS);
if (success) {
return reference.get();
} else {
// something happend down the chain, log and report the error.
}
You can think of the AtomicReference as a thread safe container that you can use to pass around objects. If you need to pass around primitives, there are also direct implementations like AtomicBoolean, AtomicInteger and so forth.
One more word on the thread pool for listeners: by default a dynamic thread pool is created and managed per CouchbaseClient, but you can pass in your own thread pool if you wan to share pool resources either from your application or if you are using listeners on multiple CouchbaseClient instances. See the configuration section for details, but if you pass in your own, don’t forget to shut it down when it is not needed anymore.
Bullet-Proof Futures and Listeners¶
Asynchronous operations differ a little to their synchronous counterparts in that they don’t raise an exception if something goes wrong because there is no thread where it makes sense. Of course, if you decide to block finally then there will be exceptions raised.
Even if a method that returns a future doesn’t block the calling thread until done, there can be an exception raised during a call like client.set(). Every key-based operation eventually goes down to a node, which has an input queue. If this queue is full (because the supplier (you) outpaces the consumer (the network)), an InvalidStateException is raised, telling you that it tried to wait for a given amount of time to insert the operation, but it still wasn’t possible. This setting, opQueueMaxBlockTime, is set to 10 seconds by default and is tunable. The default size of this input queue is 16384 (per node), which is also tunable.
try {
OperationFuture<Boolean> future = client.set("key", "value");
} catch (IllegalStateException ex) {
// outpacing the network, probably back off and retry
// or backpressure to upper layers
}
For completeness sake, there are two other reasons why an IllegalStateException could be thrown in this case: if the thread has been interrupted while it tried to put it onto the input queue or if the application is shutting down. Because both cases are rare in a the regular flow, the most common reason is the input queue.
Because views are handled differently, this does not need to be done for view and design document operations.
You also need to take care after you block on the future through .get() or .get(long, TimeUnit). There are two main reasons why this call will raise an exception: the underlying operation was either cancelled or timed out. Depending on which of those you are using, you need to be on the lookout for the following exceptions: TimeoutException, ExecutionException and RuntimeException.
There are different exceptions to catch between those two, because the java Future interface doesn’t define a TimeoutException on the get() method. This is because the original intent is to block until done, which only makes limited sense with I/O-based operations and distributed systems. So, let’s discuss the .get(long, TimeUnit) first. Here is the gist:
try {
OperationFuture<Boolean> future = client.set("key", "value");
boolean result = future.get(10, TimeUnit.SECONDS);
} catch (IllegalStateException ex) {
// outpacing the network, probably back off and retry
// or backpressure to upper layers
} catch(TimeoutException ex) {
// operation timed out
} catch(ExecutionException ex) {
// operation was cancelled or an exception was raised somewhere in the
// internal code path
}
To achieve the same thing with the regular get() method, the TimeoutException needs to be wrapped inside a RuntimeException:
try {
OperationFuture<Boolean> future = client.set("key", "value");
boolean result = future.get();
} catch (IllegalStateException ex) {
// outpacing the network, probably back off and retry
// or backpressure to upper layers
} catch(RuntimeException ex) {
if (e.getCause() instanceof TimeoutException) {
// operation timed out
}
} catch(ExecutionException ex) {
// operation was cancelled or an exception was raised somewhere in the
// internal code path
}
Querying Views¶
This section provides reference material about querying and working with views and design documents from the perspective of the Java client. If you want to get started quickly, check out the tutorial first. Also, the server documentation provides good information about how views work in general and their characteristics.
Introduction¶
Let’s first discuss how the client interacts with the server in terms of views. While not mandatory, it is always good to get a general idea about how the underlying codebase works. Because a view result potentially contains many rows, the client cannot pinpoint a single node to ask for the result (which is different than key-based operations). So instead of asking a single node for a specific document, the client asks one node in the cluster for the complete result. The server node temporarily acts as the broker for the view query and aggregates the results from all nodes in the cluster. It then returns the combined result to the client. All communication is done over HTTP port 8092. You need to make sure this port is reachable (in addition to other ports).
In the current implementation, the SDK uses the Apache httpcore library to perform the actual HTTP requests (and collect responses). This is done over Java NIO, which is very efficient compared to traditional, blocking IO. By default, two threads are created for view handling when you instantiate a new CouchbaseClient object. The first one is for the IO Reactor, which is basically the orchestrator, and then a worker thread that does the actual work of listening on the NIO selectors is launched. These settings can be tuned, but the defaults are suitable to get started.
While views are performant, they can never be as fast as single-key lookups. Therefore, they need to be used with care on the “hot code path” where performance is key to your application. We’ll see later how to get the most performance out of your views, but as always there are tradeoffs that need to be considered.
Configuration¶
On the CouchbaseConnectionFactoryBuilder, you can tune the following configuration options, which modify the run time behavior of views:
-
setViewTimeout()—default: 75 seconds (Cluster side default timeout is 60 seconds.) -
setViewWorkerSize()—default: 1 thread -
setViewConnsPerNode()—default: 10 connections.
Here is a example that shows how they could be changed:
CouchbaseClient client = new CouchbaseClient(
new CouchbaseConnectionFactoryBuilder()
.setViewTimeout(30) // set the timeout to 30 seconds
.setViewWorkerSize(5) // use 5 worker threads instead of one
.setViewConnsPerNode(20) // allow 20 parallel http connections per node in the cluster
.buildCouchbaseConnection(nodes, bucket, password)
);
View timeout. The view timeout is the default timeout used when the blocking methods are used (like client.query(...)). If the asynchronous methods are used, a custom timeout can be provided for greater flexibility. In general, you should not set a low timeout (like 2.5 seconds as with key-based operations), because views tend to take longer to return. Also, plan some padding for network spike latencies or if more traffic arrives than planned. This is also why a very conservative timeout of 75 seconds is used (and on the server side, the timeout is 60 seconds).
View worker size. Depending on the number of nodes in the cluster and the amount of view requests made, the worker size can be tuned to accommodate special needs. As a rule of thumb, if you do not expect more than 1 KB of view requests per second, one worker should be fine. If you want to push the limits, steadily increase the worker size and see if throughput increases (always potentially with higher latency as the trade-off).
View connections per node. This setting describes the maximum number of open HTTP connections in parallel on a per-node basis. For example, if you have 5 servers in your cluster and you keep the default maximum of 10 connections, the SDK will not open more than a total of 50 connections to the cluster. If you need more performance tuning this value might or might not help (if the server is busy serving requests, adding more connections won’t always help). The client only opens new connections if the other ones are still busy processing. If the maximum number of connections is open, the requests are queued up and dispatched (or time out).
The operation timeout for key-based operations, which is set to 2.5 seconds by default, is somewhat related because if you use the setIncludeDocs(true) query parameter, the SDK fetches documents in the background for you before returning you the ViewResult. While key-based operations are much more performant, timeouts can still occur. This is especially something to watch out for if you have a large amount of your data set on disk.
You can also configure the viewmode system property. By default, all view requests are made against design documents that haven been published. If you forget to click Publish in the user interface, the SDK still complains that the view does not exist. If you explicitly want to use development views, you can change this by setting the viewmode system property to development (default is production) before the CouchbaseClient object is constructed. This enables you to change from a development version of the view to a production version without needing to rebuild the application.
Querying¶
Querying the view consists of several steps. To query the view, you load the view definition, define a Query object ,and then query the actual index on the server. You can then iterate over the returned data set.
The following exempts use the beer-sample bucket that ships with the server. Make sure to load and connect to it if you want to follow along with the queries.
Loading the View Definition¶
The first thing to do is load the view definition from the server. This is needed because the client needs to know if a reduce function is defined, what kind of view it is and so on. To load the definition, you need both the name of the design document and of the view itself. The following example looks for the brewery_beers view inside the beer design document (remember to publish it first!).
CouchbaseClient client = new CouchbaseClient(...);
View view = client.getView("beer", "brewery_beers");
While not particularly interesting in general, the View object itself provides methods that help during debugging. You can use the getURI() method to make sure the query URL is correct and hasReduce() to see if a reduce function is defined and will be used by default (if not switched off through the Query object). The CouchbaseClient accesses the same properties later to route the query properly.
Preparing Query parameters¶
The next step is to instantiate a Query object and (optionally) apply parameters that influence the run time behavior of the query itself. The methods you see on the Query object, by intention, mirror those in the UI when you click the triangle next to Filter Results. Some of the parameters take enums as arguments to make it easier for you. Here is an example that shows how to set some parameters:
Query query = new Query();
query.setLimit(10);
query.setIncludeDocs(true);
query.setStale(Stale.UPDATE_AFTER);
ComplexKeys
The setters have docblocks to explain their meaning, but there is one thing you should be aware of. Because those arguments get transformed into HTTP query parameters, certain transformations need to be done, the most important one being escaping of values. Because escaping tends to get complex pretty quickly, especially if you might be dealing with brackets (for arrays) and quotes, a ComplexKey utility class is available. It removes the escaping burden from you and helps with inferring the correct wire format for the given object. All of the methods that take a ComplexKey also take a raw String, so you can always provide your own arguments if needed.
Let’s say we only want to get two keys out of our view index. Couchbase Server needs a format like ["key1","key2"], but we also need to encode it properly. Let’s try the raw way first:
Query query = new Query();
query.setKeys("[\"foo\",\"bar\"]");
This would be rendered on the wire as keys=%5B%22foo%22%2C%22bar%22%5D. To achieve the same result more easily, you can rewrite the same query using the ComplexKey class:
Query query = new Query();
query.setKeys(ComplexKey.of("foo", "bar"));
This doesn’t only work for strings, but also for numbers and so on. By default, if you pass only one element to the ComplexKey object it does not assume you need it wrapped in an array. If you do, call the forceArray method to enforce this behavior.
You can easily verify the output by calling toString on the Query class, which outputs the on the wire representation of the query.
Including Documents
As you have already been warned in the Couchbase Server documentation, you should never put the full document in the emit body. A map function like this is not recommended and bloats your index unnecessarily (because you are essentially storing the document both on disk and in the index):
// Don't do this!
function (doc, meta) {
emit(meta.id, doc);
}
Most of the time though, you need the document content that refers to a specific key (here, the document ID). The good news is that the SDK takes care of that for you. All map functions (not reduced) contain the document id implicitly, so if you set setIncludeDocs(true) on the Query object, the SDK will do a get fetch underneath to load the full document for you on the fly. So instead of the problematic snippet shown previously, here is the proper way:
function (doc, meta) {
emit(meta.id, null);
}
Query query = new Query();
query.setIncludeDocs(true);
The next section shows how to get a handle on the document body.
Querying the Index¶
Now that we have prepared both the view information and the actual query, it’s time to perform the actual query.
The CouchbaseClient provides a query method that is used for this task. It returns a ViewResponse that you can inspect and iterate over. Each iteration gives a ViewRow that represents a row emitted in the index and contains all the data needed.
The beer-sample data set contains a view that emits both breweries and their beers. To list the first 15 entries and print their document IDs in this view, you can write the following code:
View view = client.getView("beer", "brewery_beers");
Query query = new Query();
query.setLimit(15);
ViewResponse response = client.query(view, query);
for (ViewRow row : response) {
System.out.println(row.getId());
}
Here’s the output from the previous example:
21st_amendment_brewery_cafe
21st_amendment_brewery_cafe-21a_ipa
21st_amendment_brewery_cafe-563_stout
21st_amendment_brewery_cafe-amendment_pale_ale
21st_amendment_brewery_cafe-bitter_american
21st_amendment_brewery_cafe-double_trouble_ipa
21st_amendment_brewery_cafe-general_pippo_s_porter
21st_amendment_brewery_cafe-north_star_red
21st_amendment_brewery_cafe-oyster_point_oyster_stout
21st_amendment_brewery_cafe-potrero_esb
21st_amendment_brewery_cafe-south_park_blonde
21st_amendment_brewery_cafe-watermelon_wheat
3_fonteinen_brouwerij_ambachtelijke_geuzestekerij
3_fonteinen_brouwerij_ambachtelijke_geuzestekerij-drie_fonteinen_kriek
3_fonteinen_brouwerij_ambachtelijke_geuzestekerij-oude_geuze
The keys are sorted by UTF-8 collation. For more information about the collation scheme, see this blog post.
The following example uses a range to list only the 21st Amendment Brewery Cafe and all its beers:
Query query = new Query();
String brewery = "21st_amendment_brewery_cafe";
String endToken = "\\u02ad";
query.setRange(
ComplexKey.of(brewery).forceArray(true), // from (start)
ComplexKey.of(brewery + endToken).forceArray(true) // to (end)
);
The code in the example instructs the view engine to return a range of keys, beginning with the key specified in the brewery string for the 21s Amendment Brewery Cafe and ending with a nonexistent key. If an ending key is not specified, queries return the rows for the specified starting key and all rows following the starting key. The character stored in endToken is the last UTF-8 character, so you can think of it as the end to search for. The code creates a nonexistent ending key by concatenating endToken to the end of the starting key.
Running this query returns only the 21st Amendment Brewery Cafe and all its beers:
21st_amendment_brewery_cafe
21st_amendment_brewery_cafe-21a_ipa
21st_amendment_brewery_cafe-563_stout
21st_amendment_brewery_cafe-amendment_pale_ale
21st_amendment_brewery_cafe-bitter_american
21st_amendment_brewery_cafe-double_trouble_ipa
21st_amendment_brewery_cafe-general_pippo_s_porter
21st_amendment_brewery_cafe-north_star_red
21st_amendment_brewery_cafe-oyster_point_oyster_stout
21st_amendment_brewery_cafe-potrero_esb
21st_amendment_brewery_cafe-south_park_blonde
21st_amendment_brewery_cafe-watermelon_wheat
Working with the returned data¶
So far the examples have only printed the ID of the document, which you can also use to load the full document content :
ViewResponse response = client.query(view, query);
for (ViewRow row : response) {
if (row.getId() != null) {
String documentBody = (String) client.get(row.getId());
}
}
The Query class has shorthand that instructs the SDK to load the document and provide it through the getDocument() method:
Query query = new Query();
query.setLimit(2);
query.setIncludeDocs(true);
ViewResponse response = client.query(view, query);
for (ViewRow row : response) {
System.out.println(row.getDocument());
}
This prints out the content of the first two documents in the index:
{
"address": [
"563 Second Street"
],
"city": "San Francisco",
"code": "94107",
"country": "United States",
"description": "The 21st Amendment Brewery offers a variety of award winning house made brews and American grilled cuisine in a comfortable loft like setting. Join us before and after Giants baseball games in our outdoor beer garden. A great location for functions and parties in our semi-private Brewers Loft. See you soon at the 21A!",
"geo": {
"accuracy": "ROOFTOP",
"lat": 37.7825,
"lon": -122.393
},
"name": "21st Amendment Brewery Cafe",
"phone": "1-415-369-0900",
"state": "California",
"type": "brewery",
"updated": "2010-10-24 13:54:07",
"website": "http://www.21st-amendment.com/"
}
{
"abv": 7.2,
"brewery_id": "21st_amendment_brewery_cafe",
"category": "North American Ale",
"description": "Deep golden color. Citrus and piney hop aromas. Assertive malt backbone supporting the overwhelming bitterness. Dry hopped in the fermenter with four types of hops giving an explosive hop aroma. Many refer to this IPA as Nectar of the Gods. Judge for yourself. Now Available in Cans!",
"ibu": 0.0,
"name": "21A IPA",
"srm": 0.0,
"style": "American-Style India Pale Ale",
"type": "beer",
"upc": 0,
"updated": "2010-07-22 20:00:20"
}
It is important to not confuse the getId() and getKey() methods. The getId() method always refers to the unique ID of a document. You can use it to locate the document through the client.get() method. The getKey() method refers to a string representation of the actual key in the index. The getValue() method refers to the value of the emit call.
The following example prints out more information about the last query:
for (ViewRow row : response) {
System.out.println("Document ID: " + row.getId());
System.out.println("Indey Key: " + row.getKey());
System.out.println("Index Value: " + row.getValue());
System.out.println("---");
}
Document ID: 21st_amendment_brewery_cafe
Indey Key: ["21st_amendment_brewery_cafe"]
Index Value: null
---
Document ID: 21st_amendment_brewery_cafe-21a_ipa
Indey Key: ["21st_amendment_brewery_cafe","21st_amendment_brewery_cafe-21a_ipa"]
Index Value: null
---
You can see that while the ID refers to the document ID (and won’t change, even if the index changes), both the key and value reflect the view definition.
Pagination¶
If you want to go through larger amounts of index data, it might make sense to load them in chunks (speak “pages”). Pagination is commonly found in web applications where a table is displayed and the user can click a button to get the next batch of data and so on. A naive approach might be implemented with setLimit() and setSkip(), keeping the limit at a fixed size (the page size) and increment skip by the numbers of pages you want to skip forward.
While this sounds pretty easy at first, it turns out that if the skip part gets very large, the performance degrades a lot. This has to do with how the indexer goes through the stored information. It can’t just skip directly to the skip marker you requested, but has to go through all N skipped documents to find the starting point. One can imagine that this is quite inefficient, so a second strategy can be used that requires more work on the client side, but is much faster.
Using a combination of startKey and startKeyDocID, you can hint the correct document ID to the indexer and because of the index structure stored it can jump directly to the desired document. This is also known as stateful pagination because the client needs to keep track of the next document to start with. So you need to keep in mind to fetch N+1 documents and use the last one as a starter for the next query. For reduced views, only skip and limit can be used because there is no distinct document ID to start from next.
Thankfully, you don’t need to do this on your own. The SDK provides a Paginator class that provides Java Iterable pages:
View view = client.getView("beer", "brewery_beers");
Query query = new Query();
query.setLimit(10);
int docsPerPage = 4;
Paginator pages = client.paginatedQuery(view, query, docsPerPage);
while (pages.hasNext()) {
System.out.println ("--Page:");
ViewResponse response = pages.next();
for (ViewRow row : response) {
System.out.println(row.getId());
}
}
The example sets a maximum limit of 10 documents and requests four documents per batch (page size). The output looks like this:
--Page:
21st_amendment_brewery_cafe
21st_amendment_brewery_cafe-21a_ipa
21st_amendment_brewery_cafe-563_stout
21st_amendment_brewery_cafe-amendment_pale_ale
--Page:
21st_amendment_brewery_cafe-bitter_american
21st_amendment_brewery_cafe-double_trouble_ipa
21st_amendment_brewery_cafe-general_pippo_s_porter
21st_amendment_brewery_cafe-north_star_red
--Page:
21st_amendment_brewery_cafe-oyster_point_oyster_stout
21st_amendment_brewery_cafe-potrero_esb
This technique can also be used if lots of data in a view needs to be analyzed. It will be done in smaller chunks which is easier for the underlying JVM, cluster connection, and so on.
Asynchronous Querying¶
The CouchbaseClient API provides asynchronous methods where possible, and view execution is no exception. All methods seen previously (especially getView and query) can be executed asynchronously. You can either use the Future directly, or attach a Listener to it and let the executor handle calling the callback. Here is a fully asynchronous execution of a view query. We are using a CountDownLatch to make the current thread wait until the execution is completed. If you use a completely reactive environment such as Akka or Play, this is not needed.
final CountDownLatch latch = new CountDownLatch(1);
final Query query = new Query();
query.setLimit(10);
client.asyncGetView("beer", "brewery_beers").addListener(new HttpCompletionListener() {
@Override
public void onComplete(HttpFuture<?> viewFuture) throws Exception {
if (viewFuture.getStatus().isSuccess()) {
View view = (View) viewFuture.get();
client.asyncQuery(view, query).addListener(new HttpCompletionListener() {
@Override
public void onComplete(HttpFuture<?> queryFuture) throws Exception {
if (queryFuture.getStatus().isSuccess()) {
ViewResponse response = (ViewResponse) queryFuture.get();
for (ViewRow row : response) {
System.out.println(row.getId());
}
}
latch.countDown(); // signal we are done
}
});
}
}
});
latch.await(); // wait for the latch to be counted down in the callback
You can also grab the HttpFuture directly from the async* methods and block on them as needed (or sending them over to your own thread pool for execution). Another reason why you want to use the HttpFuture is that you can change the default timeout for every query. If you only want to wait 50 seconds until a timeout arises, you can do it like this:
View view = client.asyncGetView("beer", "brewery_beers").get(50, TimeUnit.SECONDS);
Design Documents¶
Design documents are usually created through the UI. While this is convenient, sometimes you need things more automated. For example, in integration tests you might want to create a design document with one or more views automatically before each run.
The Java SDK provides some methods that help you with that:
-
getDesignDoc: load a design document with its view definitions -
createDesignDoc: create a design document containing view definitions -
deleteDesignDoc: delete a design document
This example shows how to use the getDesignDoc method:
// Load the Design Document
DesignDocument beer = client.getDesignDoc("beer");
// Print the name and map function of all its views
for (ViewDesign view : beer.getViews()) {
System.out.println("Name: " + view.getName());
System.out.println("Map: " + view.getMap());
}
The DesignDocument object is your starting point and provides information about itself, but also about the views contained. You can iterate over all stored views and print their names, map and reduce functions. Executing the example code on the beer-sample bucket gives you the following:
Name: brewery_beers
Map: function(doc, meta) {
switch(doc.type) {
case "brewery":
emit([meta.id]);
break;
case "beer":
if (doc.brewery_id) {
emit([doc.brewery_id, meta.id]);
}
break;
}
}
Name: by_location
Map: function (doc, meta) {
if (doc.country, doc.state, doc.city) {
emit([doc.country, doc.state, doc.city], 1);
} else if (doc.country, doc.state) {
emit([doc.country, doc.state], 1);
} else if (doc.country) {
emit([doc.country], 1);
}
}
The same way you load a DesignDocument, you can create your own and save it. Note that there is no translation between Java and JavaScript going on, the best idea is to write the view in the UI and then copy it to a file or directly in the source code, depending on your needs. Make sure special characters are properly escaped (your IDE should help you with that).
Here is an example that creates a new design document, one view with a map and reduce function and saves it. You could then query it as normal.
DesignDocument designDoc = new DesignDocument("beers");
designDoc.setView(new ViewDesign("by_name", "function (doc, meta) {" +
" if (doc.type == \"beer\" && doc.name) {" +
" emit(doc.name, null);" +
" }" +
"}"));
client.createDesignDoc(designDoc);
You can also delete a design document completely:
client.deleteDesignDoc("beers");
Performance¶
If you are running Couchbase Server, you probably do because you care about performance and scalability. As a general rule of thumb, just because of its nature, views tend to be more feature rich, but also slower than key-based document lookups (like you would do with a get command). The main reason for this is that more work has to be done on the server side to locate the proper contents of the index and return it to the user. Walking a tree data structure on distributed nodes and merging the subresults back into one for the client takes more time than a simple document lookup on one server.
After this initial disclaimer, let’s see how we can get the maximum performance out of our views.
Understanding Staleness¶
When you are doing a view query, you can choose between data freshness and query performance. You can set the appropriate staleness option on the Query object through the setStale(Stale) method. The following options are available:
-
Stale.OK: When the query is executed on the server side, whatever is in the index at the moment is collected and sent back to the client. This is the most performant way of querying, but potentially also includes stale data or does not include recent documents (which the indexer did not pick up yet). Index updating is not triggered here, but the automatic index rebuilding process on the server side will update it eventually. -
Stale.UPDATE_AFTER: Like Stale.OK, but triggers the index rebuilding in the background after the index has been returned to the client. This provides a good compromise between data freshness and performance, and therefore is the default setting. -
Stale.FALSE: A full index update is done before the data is returned to the client. This option gives you the most accurate information about what’s in the view index, but is also slower than the others because it takes some time to update the index (depending on how many documents have been mutated after the last indexer run).
When you are writing unit tests and when you absolutely need 100% accurate data sets in your views you not only need to query with Stale.FALSE, but also write the data with a persistence constraint of PersistTo.MASTER. This is because the indexer picks up the data from disk, and the only way to make sure it has received the write is to wait until it actually has been persisted to disk.
Reusing View Definitions¶
Every time you call the .getView(String, String) method on the CouchbaseClient object, an HTTP request is sent to the server. As you’ve seen in the previous sections, a View object is nothing more than a representation of what the view is about. This information won’t change much in production.
As a best practice, call getView only once, and then cache the returned object and reuse it for every subsequent query call. That way you not only save bandwidth and latency, it also reduces the amount of work the server needs to do.
The reason you need to fetch the view information up front is so you know how the view is structured. If your view changes its characteristics (for example, a map function gets added or removed or the name changes) you need to reload the view. This needs to be handled appropriately for your application needs (for example, expose a command, rest endpoint or a JMX MBean). If just the content of the map function changes, there is no need to clear the cache.
Caching View Results¶
Another optimization that is very common is to cache the view result in another document. You can then treat it as any other cacheable object, optionally with a time to live attached. If the cached document doesn’t need to be read by another programming language, you can store it as a serialized java object (or any other binary format).
Suppose you want to get a list of document IDs that represent breweries and beers. A simple caching solution that keeps the list of IDs for 10 seconds in a separate document before fetching it again from the view might look like this:
private List<String> findBreweriesCached(CouchbaseClient client, View view) throws Exception {
int ttl = 10; // keep for 10 seconds
String key = "cache::" + view.getDesignDocumentName() + "::" + view.getViewName();
List<String> response = (List<String>) client.get(key);
if (response == null) {
ViewResponse result = client.query(view, new Query());
response = new ArrayList<String>();
for (ViewRow row : result) {
response.add(row.getId());
}
client.set(key, ttl, response).get();
}
return response;
}
Of course this can be modified to handle custom Query objects and timeout settings. The View instance is passed in explicitly because it can also be cached and reused in other spots of the application (also, proper error handling needs to be in place in a production setting).
Parallelism¶
One thread querying a view might not give you the throughput needed for your application. If you are benchmarking simple code like the following, you are more or less benchmarking network latency:
View view = client.getView("beer", "brewery_beers");
Query query = new Query();
while (true) {
client.query(view, new Query()); // do one query and wait for the result to arrive.
}
One approach is to use a ExecutorService and parallelize the query execution. With the addition of listeners after the 1.2 series, things got much easier, even on a single thread. To simulate a higher load, fire off 50 requests in parallel and wait until they come back. You can use the same approach if you need to query different views in parallel or process other operations at the same time:
View view = client.getView("beer", "brewery_beers");
Query query = new Query();
int factor = 50;
while (true) {
final CountDownLatch latch = new CountDownLatch(factor);
for (int i = 0; i < factor; i++) {
client.asyncQuery(view, new Query()).addListener(new HttpCompletionListener() {
@Override
public void onComplete(HttpFuture<?> future) throws Exception {
ViewResponse response = (ViewResponse) future.get();
// do something with the response here.
latch.countDown();
}
});
}
latch.await();
}
To see whether the server or the client is the bottleneck, you can use Stale.FALSE and a smaller limit clause to both take off some pressure from the server and the network. Of course, if you are testing for realistic scenarios (which you should), just use the values that you anticipate to produce a realistic load behavior.
Failure Handling¶
Because various things can go wrong in distributed systems, it’s also important to talk about failure handling and avoidance. Most of the potential issues can be worked around with defensive coding; that is, accepting that things can go wrong and provide code to handle it appropriately to the application context.
Because view queries are not mutating any state, the CouchbaseClient itself will retry the query if a non-success response gets returned from the server until it times out. This is done for responses that indicate a retry might be successful. One of the common examples is that if a node gets removed from the cluster and it doesn’t have any shards assigned to it (right before leaving the cluster at the end of a rebalance operation) it can’t serve view requests anymore. In such cases, the server responds with an HTTP redirect indicating that another node in the cluster should be tried, which the client does transparently to the application.
One of the common responses that is not retried is a 404, which tells the client that the view can’t be found on the server. If this happens, a InvalidViewException error is thrown:
Exception in thread "main" com.couchbase.client.protocol.views.InvalidViewException: Could not load view "bar" for design doc "foo"
at com.couchbase.client.CouchbaseClient.getView(CouchbaseClient.java:421)
at Main.main(Main.java:27)
Make sure that the view is deployed to production and available on the target cluster. Note that since it’s expected that if the View object is found, a subsequent 404 on the query method is retried (because it could indicate a temporary error).
If you construct an invalid View object intentionally and query the server, you’ll see the following:
client.asyncQuery(
new View("beer-sample", "foo", "bar", true, false),
new Query()
).get(10, TimeUnit.SECONDS);
2014-01-09 11:27:35.745 INFO com.couchbase.client.ViewNode$MyHttpRequestExecutionHandler: Retrying HTTP operation Request: GET /beer-sample/_design/foo/_view/bar HTTP/1.1, Response: HTTP/1.1 404 Object Not Found
Exception in thread "main" java.util.concurrent.TimeoutException: Timed out waiting for operation
at com.couchbase.client.internal.HttpFuture.waitForAndCheckOperation(HttpFuture.java:93)
at com.couchbase.client.internal.HttpFuture.get(HttpFuture.java:82)
If you always try to load a fresh View object this is not likely to happen, but could arise when you are caching View definitions that get deleted or renamed.
TimeoutExceptions can arise on all view method calls, most of the time because one part in the request/response cycles is slowing down (client, network or server). They should be caught, logged and investigated properly. The default timeout, while adjustable, is set to 75 seconds.
Always include null-checks when processing getDocument() calls because by definition a view is not 100% up-to-date on the state of the documents. This is especially important if you are storing documents with timeouts or deleting them on a regular basis. The following example checks for a null document:
View view = client.getView("beer", "brewery_beers");
ViewResponse response = client.query(view, new Query().setIncludeDocs(true));
for (ViewRow row : response) {
Object doc = row.getDocument();
if (doc != null) {
// do something with your document
}
}
Experimental: Spatial Views¶
Spatial iews are an experimental feature on both on the server and the client side as of the 2.x server releases. The documents queried need to follow the GeoJSON specification. You can create a spatial view from the UI with the following map function:
function (doc) {
if (doc.type == "brewery" && doc.geo.lon && doc.geo.lat) {
emit({ "type": "Point", "coordinates": [doc.geo.lon, doc.geo.lat]}, null);
}
}
Querying the spatial view from the Java SDK is similar to querying regular views:
SpatialView view = client.getSpatialView("beer", "points");
Query query = new Query();
query.setLimit(10);
ViewResponse response = client.query(view, query);
for (ViewRow row : response) {
System.out.println(row.getId() + ": " + row.getBbox());
}
vancouver_island_brewing: [-123.367,48.4344,-123.367,48.4344]
umpqua_brewing: [-123.342,43.2165,-123.342,43.2165]
yaletown_brewing: [-123.121,49.2755,-123.121,49.2755]
wild_duck_brewing: [-123.087,44.0521,-123.087,44.0521]
white_oak_cider: [-123.073,45.3498,-123.073,45.3498]
thirstybear_brewing: [-122.4,37.7855,-122.4,37.7855]
yakima_brewing_and_malting_grant_s_ales: [-120.506,46.6021,-120.506,46.6021]
tenaya_creek_restaurant_and_brewery: [-115.251,36.2154,-115.251,36.2154]
wyder_s_cider: [-114.083,51.034,-114.083,51.034]
uinta_brewing_compnay: [-111.954,40.7326,-111.954,40.7326]
You can also access the latitude and longitude parameters from the ViewRow response. Doing a query like this returns the first 10 rows from wherever in the world. If you just want to get those from Europe, you can use coordinates to set a bounding box at query time:
SpatialView view = client.getSpatialView("beer", "points");
Query query = new Query();
query.setLimit(10);
// Somewhere south-west of portugal
double lowerLeftLon = -10.37109375;
double lowerLeftLat = 33.578014746143985;
// Somewhere north-east of europe, over russia
double upperRightLon = 43.76953125;
double upperRightLat = 71.9653876991313;
query.setBbox(lowerLeftLon, lowerLeftLat, upperRightLon, upperRightLat);
ViewResponse response = client.query(view, query);
for (ViewRow row : response) {
System.out.println(row.getId() + ": " + row.getBbox());
}
dublin_brewing: [-6.2675,53.3441,-6.2675,53.3441]
st_james_s_gate_brewery: [-6.2675,53.3441,-6.2675,53.3441]
strangford_lough_brewing_company_ltd: [-5.6548,54.3906,-5.6548,54.3906]
st_austell_brewery: [-4.7883,50.3416,-4.7883,50.3416]
tennent_caledonian_brewery: [-4.2324,55.8593,-4.2324,55.8593]
williams_brothers_brewing_company: [-3.7954,56.1163,-3.7954,56.1163]
maclay_and_co: [-3.7528,56.1073,-3.7528,56.1073]
orkney_brewery: [-3.3135,59.0697,-3.3135,59.0697]
sa_brain_co_ltd: [-3.179,51.4736,-3.179,51.4736]
traquair_house_brewery: [-3.0636,55.619,-3.0636,55.619]
For more information about working with spatial views, see Writing geospatial views.
Advanced Usage¶
This Couchbase SDK Java provides a complete interface to Couchbase Server through the Java programming language. For more information about Couchbase Server and Java read the Java SDK Getting Started Guide followed by the in-depth Couchbase and Java tutorial. We require Java SE 6 or later for running the Couchbase Client Library.
This section covers the following topics:
Logging from the Java SDK
Handling time-outs
Bulk load and exponential back-off
Retrying after receiving a temporary failure
Configuring Logging¶
Occasionally when you are troubleshooting an issue with a clustered deployment, you might find it helpful to use additional information from the Couchbase Java SDK logging. The SDK uses JDK logging and this can be configured by specifying a run-time define and adding some additional logging properties. You can set up Java SDK logging in the following ways:
Use spymemcached to log from the Java SDK. Because the SDK uses spymemcached and is compatible with spymemcached, you can use the logging provided to output SDK-level information.
Set your JDK properties to log Couchbase Java SDK information.
Provide logging from your application.
To provide logging via spymemcached:
System.setProperty("net.spy.log.LoggerImpl", "net.spy.memcached.compat.log.SunLogger");
or
System.setProperty("net.spy.log.LoggerImpl", "net.spy.memcached.compat.log.Log4JLogger");
The default logger logs everything to the standard error stream. To provide logging via the JDK, if you are running a command-line Java program, you can run the program with logging by setting a property:
-Djava.util.logging.config.file=logging.properties
The other alternative is to create a logging.properties and add it to your classpath:
logging.properties
handlers = java.util.logging.ConsoleHandler
java.util.logging.ConsoleHandler.level = ALL
java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter
com.couchbase.client.vbucket.level = FINEST
com.couchbase.client.vbucket.config.level = FINEST
com.couchbase.client.level = FINEST
The final option is to provide logging from your Java application. If you are writing your application in an IDE that manages command-line operations for you, it might be easier if you express logging in your application code. Here is an example:
// Tell things using spymemcached logging to use internal SunLogger API
Properties systemProperties = System.getProperties();
systemProperties.put("net.spy.log.LoggerImpl", "net.spy.memcached.compat.log.SunLogger");
System.setProperties(systemProperties);
Logger.getLogger("net.spy.memcached").setLevel(Level.FINEST);
Logger.getLogger("com.couchbase.client").setLevel(Level.FINEST);
Logger.getLogger("com.couchbase.client.vbucket").setLevel(Level.FINEST);
//get the top Logger
Logger topLogger = java.util.logging.Logger.getLogger("");
// Handler for console (reuse it if it already exists)
Handler consoleHandler = null;
//see if there is already a console handler
for (Handler handler : topLogger.getHandlers()) {
if (handler instanceof ConsoleHandler) {
//found the console handler
consoleHandler = handler;
break;
}
}
if (consoleHandler == null) {
//there was no console handler found, create a new one
consoleHandler = new ConsoleHandler();
topLogger.addHandler(consoleHandler);
}
//set the console handler to fine:
consoleHandler.setLevel(java.util.logging.Level.FINEST);
Handling Time-outs¶
The Java client library has a set of synchronous and asynchronous methods. While it does not happen in most situations, occasionally network IO can become congested, nodes can fail, or memory pressure can lead to situations where an operation can time out.
When a time-out occurs, most of the synchronous methods on the client return a RuntimeException showing a time-out as the root cause. Because the asynchronous operations give more specific control over how long it takes for an operation to be successful or unsuccessful, asynchronous operations throw a checked TimeoutException.
As an application developer, it is best to think about what you would do after this time-out. This might be something such as showing the user a message, doing nothing, or going to some other system for additional data.
In some cases you might want to retry the operation, but you should consider this carefully before performing the retry in your code—a retry might exacerbate the underlying problem that caused the time-out. If you choose to do a retry, providing it in the form of a back-off or exponential back-off is advisable. This can be thought of as a pressure relief valve for intermittent resource problems. For more information on back-off and exponential back-off, see Bulk Load and Exponential Backoff.
Timing-out and Blocking¶
If your application creates a large number of asynchronous operations, you might encounter immediate time-outs in response to the requests. When you perform an asynchronous operation, Couchbase Java SDK creates an object and puts the object into a request queue. The object and the request are stored in Java run-time memory. In other words, they are stored in local to your Java application run-time memory and require some amount of Java Virtual Machine IO to be serviced.
Rather than write so many asynchronous operations that can overwhelm a JVM and generate out of memory errors for the JVM, you can rely on SDK-level time-outs. The default behavior of the Java SDK is to start to immediately time-out asynchronous operations if the queue of operations to be sent to the server is overwhelmed.
You can also choose to control the volume of asynchronous requests that are issued by your application by setting a time-out for blocking. You might want to do this for a bulk load of data so that you do not overwhelm your JVM. Here’s an example:
List<URI> baselist = new ArrayList<URI>();
baselist.add(new URI("http://localhost:8091/pools"));
CouchbaseConnectionFactoryBuilder cfb = new CouchbaseConnectionFactoryBuilder();
cfb.setOpQueueMaxBlockTime(5000); // wait up to 5 seconds when trying to enqueue an operation
CouchbaseClient myclient = new CouchbaseClient(cfb.buildCouchbaseConnection(baselist, "default", "default", ""));
Bulk Load and Exponential Back-off¶
When you bulk load data to Couchbase Server, you can accidentally overwhelm available memory in the Couchbase cluster before it can store data on disk. If this happens, Couchbase Server immediately sends a response indicating the operation cannot be handled at the moment but can be handled later.
This is sometimes referred to as handling temporary out-of-memory (OOM). Note, though, that the actual temporary failure could be sent back for reasons other than OOM. However, temporary OOM is the most common underlying cause for this error.
To handle this problem, you could perform an exponential back-off as part of your bulk load. The back-off essentially reduces the number of requests sent to Couchbase Server as it receives OOM errors:
package com.couchbase.sample.dataloader;
import com.couchbase.client.CouchbaseClient;
import java.io.IOException;
import java.net.URI;
import java.util.List;
import net.spy.memcached.internal.OperationFuture;
import net.spy.memcached.ops.OperationStatus;
/**
*
* The StoreHandler exists mainly to abstract the need to store things
* to the Couchbase Cluster even in environments where we may receive
* temporary failures.
*
* @author ingenthr
*/
public class StoreHandler {
CouchbaseClient cbc;
private final List<URI> baselist;
private final String bucketname;
private final String password;
/**
*
* Create a new StoreHandler. This will not be ready until it's initialized
* with the init() call.
*
* @param baselist
* @param bucketname
* @param password
*/
public StoreHandler(List<URI> baselist, String bucketname, String password) {
this.baselist = baselist; // TODO: maybe copy this?
this.bucketname = bucketname;
this.password = password;
}
/**
* Initialize this StoreHandler.
*
* This will build the connections for the StoreHandler and prepare it
* for use. Initialization is separated from creation to ensure we would
* not throw exceptions from the constructor.
*
*
* @return StoreHandler
* @throws IOException
*/
public StoreHandler init() throws IOException {
// I prefer to avoid exceptions from constructors, a legacy we're kind
// of stuck with, so wrapped here
cbc = new CouchbaseClient(baselist, bucketname, password);
return this;
}
/**
*
* Perform a regular, asynchronous set.
*
* @param key
* @param exp
* @param value
* @return the OperationFuture<Boolean> that wraps this set operation
*/
public OperationFuture<Boolean> set(String key, int exp, Object value) {
return cbc.set(key, exp, cbc);
}
/**
* Continuously try a set with exponential backoff until number of tries or
* successful. The exponential backoff will wait a maximum of 1 second, or
* whatever
*
* @param key
* @param exp
* @param value
* @param tries number of tries before giving up
* @return the OperationFuture<Boolean> that wraps this set operation
*/
public OperationFuture<Boolean> contSet(String key, int exp, Object value,
int tries) {
OperationFuture<Boolean> result = null;
OperationStatus status;
int backoffexp = 0;
try {
do {
if (backoffexp > tries) {
throw new RuntimeException("Could not perform a set after "
+ tries + " tries.");
}
result = cbc.set(key, exp, value);
status = result.getStatus(); // blocking call, improve if needed
if (status.isSuccess()) {
break;
}
if (backoffexp > 0) {
double backoffMillis = Math.pow(2, backoffexp);
backoffMillis = Math.min(1000, backoffMillis); // 1 sec max
Thread.sleep((int) backoffMillis);
System.err.println("Backing off, tries so far: " + backoffexp);
}
backoffexp++;
if (!status.isSuccess()) {
System.err.println("Failed with status: " + status.getMessage());
}
} while (status.getMessage().equals("Temporary failure"));
} catch (InterruptedException ex) {
System.err.println("Interrupted while trying to set. Exception:"
+ ex.getMessage());
}
if (result == null) {
throw new RuntimeException("Could not carry out operation."); // rare
}
// note that other failure cases fall through. status.isSuccess() can be
// checked for success or failure or the message can be retrieved.
return result;
}
}
There is also a setting you can provide at the connection-level for Couchbase Java SDK that helps you avoid too many asynchronous requests:
List<URI> baselist = new ArrayList<URI>();
baselist.add(new URI("http://localhost:8091/pools"));
CouchbaseConnectionFactoryBuilder cfb = new CouchbaseConnectionFactoryBuilder();
cfb.setOpTimeout(10000); // wait up to 10 seconds for an operation to succeed
cfb.setOpQueueMaxBlockTime(5000); // wait up to 5 seconds when trying to enqueue an operation
CouchbaseClient myclient = new CouchbaseClient(cfb.buildCouchbaseConnection(baselist, "default", "default", ""));
Retrying After Receiving a Temporary Failure¶
If you send too many requests all at once to Couchbase, you can create an out of memory problem, and the server sends back a temporary failure message. The message indicates you can retry the operation, however, the server will not slow down significantly; it just does not handle the request. In contrast, other database systems will become slower for all operations under load.
This gives your application a bit more control because the temporary failure messages gives you the opportunity to provide a back-off mechanism and retry operations in your application logic.
Java Virtual Machine Tuning Guidelines¶
Generally speaking, there is no reason to adjust any Java Virtual Machine parameters when using the Couchbase Java Client. In general, you should not start with specific tuning, but instead should use defaults from the application server first, and then measure application metrics such as throughput and response time. Then, if there is a need to make an improvement, make adjustments and remeasure.
The recommendations here are based on the Oracle (formerly Sun) HotSpot Virtual Machine and derivations such as the Java Virtual Machine shipped with Mac OS X and the OpenJDK project. Other Java virtual machines likely behave similarly.
By default, garbage collection (GC) times can easily go over 1 second. This can lead to higher than expected response times or even time-outs, as the default time-out is 2.5 seconds. This is true with simple tests even on systems with lots of CPUs and a good amount of memory.
The reason for this is that for the most part, by default, the JVM is weighted toward throughput instead of latency. Of course, much of this can be controlled with GC tuning on the JVM. For the HotSpot JVM, refer to this white paper: http://www.oracle.com/technetwork/java/javase/memorymanagement-whitepaper-150215.pdf
In the referenced white paper, the Concurrent Mark Sweep collector is recommended if your application needs short pauses. It also recommends advising the JVM to try to shorten pause times. Given the Couchbase client’s 2.5 second default time-out, with our basic testing we found the following to be useful:
-XX:+UseConcMarkSweepGC -XX:MaxGCPauseMillis=850
The white paper refers to a couple of tools that might be useful in gathering information on JVM GC performance. For example, adding -XX:+PrintGCDetails and -XX:+PrintGCTimeStamps is a simple way to generate log messages that you might correlate to application behavior. The logs might show a full GC event that takes several seconds during which no processing occurs and operations might time-out. Depending on your application’s workload, adjusting parameters related to how to perform a full GC, which collector to use, how long to pause the VM during GC, and even adding incremental mode might help, . One other common tool for getting information is JConsole. JConsole is more of an interactive tool, but it might help you identify changes to make in the different memory spaces used by the JVM to further reduce the need to run a GC on the old generation.
There is a CPU time trade-off when setting these tuning parameters. The white paper describes some additional tuning parameters that you can use.
If you are using JDK 7 update 4 or later, the G1 collector might be an even better option. Again, you should be guided by measuring performance from the application level.
Even with these, our testing showed some GC times near 0.5 seconds. While the Couchbase Client allows tuning of the time-out time to drop as low as you want, we do not recommend dropping it much below 1 second unless you are planning to tune other parts of the system beyond the JVM.
For example, most people run applications on networks that do not offer guaranteed response time. If the network is oversubscribed or minor blips occur on the network, there can be TCP retransmissions. While many TCP implementations ignore it, RFC 2988 specifies rounding up to 1 second when calculating TCP retransmit time-outs.
Achieving either maximum throughput or minimum per-operation latency can be enhanced with JVM tuning, supported by overall system tuning at the extremes.
Release Notes¶
The following sections provide release notes for individual release versions of Couchbase Client Library Java. To browse or submit new issues, see the Couchbase Java Issues Tracker.
Release Notes for Couchbase Client Library Java 1.4.11 GA (7 December 2015)¶
This is the 11th release for the 1.4 series and brings additional APIs which have been left out before.
- JCBC-881: When durability requirements are specified on mutation methods, it is now possible to also pass in a custom transcoder.
Release Notes for Couchbase Client Library Java 1.4.10 GA (7 August 2015)¶
This is the tenth bug fix release for the 1.4 series and brings correctness and stability improvements during failure scenarios for both couchbase and memcached buckets.
JCBC-816: The reconfiguration (which includes grabbing a new config and applying it to the system) has been made more resilient during edge-cases. Those edge-cases include close to no load, as well as full cluster (all nodes) restarts. In the first case the heuristics have been improved to proactively pick up a new configuration more quickly, and in the second case the code has been made more resilient to consecutive failed attempts for grabbing a new configuration.
JCBC-770: A bug has been fixed where memcached buckets did fail to pick up a new configuration when the original streaming connection was teared down.
Release Notes for Couchbase Client Library Java 1.4.9 GA (3 April 2015)¶
This is the ninth bug fix release for the 1.4 series and brings correctness and stability improvements.
JCBC-738: The possibility of a
ClassCastExceptionhas been eliminated when aHttpFutureis used and a timeout is happening. This type of future is also returned when a view request is made.JCBC-741: The active node is now always included in an
observecall (internally used with durability requirements likeReplicateToandPersistTo) to reliably discover concurrent modifications. Previously, when onlyReplicateTowas used and the same document was modified concurrently the operation would just time out. Now it fails quickly and reports the failure case in the operation status. This behavior is now consistent with the one whenPersistTois also included in the durability requirement.SPY-183: The touch operation is now properly cloned, which previously led to false timeouts during rebalance and unavailable node scenarios (only on the touch operation).
Release Notes for Couchbase Client Library Java 1.4.8 GA (2 March 2015)¶
This is the eighth bug fix release for the 1.4 series and brings one for PersistTo/ReplicateTo future status flags.
-
JCBC-700: The “done” variable was not properly set when a
observefuture was already correctly completed. This impacts the user when a callback on thePersistTo/ReplicateTooverloaded methods is used and/or theisDone()method is called. Other futures are not affected.
Release Notes for Couchbase Client Library Java 1.4.7 GA (19 January 2015)¶
This is the seventh bug fix release for the 1.4 series and most importantly brings stability improvements when the carrier configuration node dies silently.
JCBC-681: When the node where the carrier configuration is fetched from silently dies (that is, without closing the socket proactively), the SDK now provides better heuristics to detect it is not responding anymore. In this new approach, the regular NOOP poll interval is piggybacked and open requests are tracked. If more than 3 responses are not coming back with a successful response, a configuration rebootstrap in the background is initiated. Because the poll cycles are 5 second intervals, this will most likely happen 15 seconds after the first missing heartbeat. The rebootstrap cycle is transparent to the application, so no changes need to be made.
SPY-181: GetAndLock operations are now properly cloned, which fixes the issue of those operations occasionally timing out during bootstrap, rebalance, or failover.
JCBC-647, SPY-182: Two messages that misleadingly reported at WARN level have been removed because they do not actually report an unstable condition. One of them is the
handling node not setmessage reported when an operation needs to be cloned, and the other one is related toPersistToandReplicateTo, which are now more clever about selecting the proper nodes to fan out and do not trigger a warning message.
Release Notes for Couchbase Client Library Java 1.4.6 GA (1 December 2014)¶
This is the sixth bug fix release for the 1.4 series and brings one critical reconnect bug fix and a regression fix for non-Oracle JVMs introduced in 1.4.5.
Fixes in 1.4.6
SPY-179: A wrong reconnect delay ceiling was applied, leading to very long reconnect delays when the node in question was down for a longer time. The fix applied now correctly translates the “max reconnect time” and applies the proper ceiling. This allows the client to recover much quicker when a node has been down for a longer time.
JCBC-620: The newly introduced diagnostics feature optionally uses some private packages that might not be available in all environments. This prevented startup in unsupported environments because the class loader would complain immediately. Proper guards are now in place to conditionally use the feature when available and gracefully degrade if not.
SPY-178: When memcached buckets are used and the
KetamaNodeLocatormethod is accessed directly, thegetReadonlyCopymethod was subject to iterator failures when used in combination with the-XX:+AggressiveOptsJVM flag.
Release Notes for Couchbase Client Library Java 1.4.5 GA (16 October 2014)¶
This is the fifth bug fix release for the 1.4 series and brings stability improvements for configuration management and optional diagnostics.
Enhancements in 1.4.5
-
JCBC-531: Optional support for diagnostics has been added. When DEBUG logging is enabled, very verbose diagnostics information about the runtime will be logged on startup. In addition, a manual call to
Diagnostics.collectAndFormat()can be used to print run time information in failure cases or during error handling scenarios (for better analysis afterwards). Information also includes GC pauses, heap statistics and version information. Every single property is utilized through MXBeans internally.
Fixes in 1.4.5
- JCBC-566: Under certain conditions, a scheduled configuration update was not performed, leaving the client with an outdated configuration - this has been fixed.
- JCBC-567: On a complete fresh config reload, the new code makes sure that carrier publication always is tried first, regardless if the HTTP fallback was used first.
Release Notes for Couchbase Client Library Java 1.4.4 GA (5 August 2014)¶
This is the fourth bug fix release for the 1.4 series and provides general stability improvements and bug fixes. Users seeing intermittent view errors or experiencing client hangs on full cluster restarts are encouraged to upgrade.
Enhancements in 1.4.4
- JCBC-490: Unparsable JSON content for View results is now logged with an error so that it is easier to debug and analyze.
Fixes in 1.4.4
- JCBC-488: If view operations are (transparently) retried, this change makes sure that authorization and host headers are replaced instead of appended. This fixes the scenario where the same header is added multiple times, leading to view errors because the server is not able to handle that request.
- JCBC-464: In case of a full rebootstrap (which is the case for full cluster restarts), the code now makes sure that no old configurations are around that change the bootstrap process a little bit and cause unexpected exceptions. Now every try to rebootstrap looks the same, making the code easier to reason about and fixing NullPointerException in some cases.
- JCBC-505: The View Query object experienced a concurrency issue because a regular expression matcher was reset instead of recreated (which is not thread safe). In most cases this is not a problem because the Query object is created and used from only one thread, but if used through the Paginator and/or shared across threads this can lead to exceptions in the matcher logic. This is now fixed.
- JCBC-503: During shutdown, internally observers were not released for the configuration logic, possibly leading to memory leaks during operations like application redeployment because the memory could not be freed after shutdown.
Release Notes for Couchbase Client Library Java 1.4.3 GA (1 July 2014)¶
This is the third bug fix release for the 1.4 series and provides important bug fixes if you are using replica reads and the new carrier publication mechanism. It also includes a heap memory optimization for larger get responses.
Enhancements in 1.4.3
- SPY-175: The memory usage for get responses with payloads has been reduced, which will be more noticeable on the heap with larger payloads and higher traffic.
Fixes in 1.4.3
JCBC-480, JCBC-482: Replica reads (
getFromReplica,getsFromReplicaand their async variants) are now reacting properly during certain failure conditions (when the document on the replica does not exist). In addition, an important bug withgetsFromReplicahas been fixed to make sure it gets scheduled appropriately to target the replica nodes.JCBC-477: Before this change, the bulk get, which is used internally when
setIncludeDocsis set to true, was not supplied with the timeout used for the view request itself. This is normally not an issue because key-value operations are much quicker than the default view timeout. In certain scenarios it can come up, so the timeout is now properly passed down.JCBC-476: The
Node expected to receive data is inactivelog message has been changed to the INFO level and contains a clearer message of what is reflected underneath. It now says that the operation is queued properly, will be retried and the SDK checks for a new configuration eventually.JCBC-475: The configuration management (especially with the carrier mode and during shutdown) has been reworked a little and hardened so it reacts better during node restarts and in the shutdown process of the SDK (to avoid running threads after shutdown).
Known Issues in 1.4.3
-
JCBC-401: When durability requirements (
PersistToorReplicateTo) are used, a custom timeout such as.get(1, TimeUnit.MINUTES)is ignored if it is higher than the defaultobsTimeoutsetting for theCouchbaseConnectionFactoryclass. The work-around is to set a higher value throughCouchbaseConnectionFactoryBuilderand then just use.get()or a possibly lower timeout setting.
Release Notes for Couchbase Client Library Java 1.4.2 GA (5 June 2014)¶
The 1.4.2 release is the second bug fix release for the 1.4 series. It fixes very important issues found on the 1.4 branch, so all users running on 1.4.0 or 1.4.1 should upgrade.
Fixes in 1.4.2
JCBC-460: A bug has been fixed where pushed configurations with replica-vbucket changes only did not count as significant and got discarded. This can be an issue if persistence or replication constraints are used since config changes might not be picked up correctly.
SPY-170: A concurrency issue has been fixed in
StringUtils.isJSONObject(), which could lead to false negatives when validating in a concurrent environment.JCBC-463, SPY-171: There have been some changes made which help with hardening the shutdown procedure in general and making it more fault tolerant. The code now makes sure to also shut down the JCBC-opened resources even if shutting down the spy I/O thread fails. Also, the spy I/O thread now always sets running to false, which makes it terminate even if something goes wrong during the shutdown phase (preventing it from being active).
JCBC-424, SPY-172: The NIO selector is now woken up manually if no load is going through, giving the Java client a chance to perform tasks. One of the currently implemented tasks is sending a NOOP broadcast if the last write is longer behind than 5 seconds. This helps to discover broken channels if no load is going through and also prevents restrictive firewalls from timing out the connections prematurely.
JCBC-413: A race condition has been fixed in the ClusterManager, now making sure that the consumer is notified once the result is set properly.
JCBC-359, JCBC-408, JCBC-409: The API documentation (Javadoc) has been enhanced in various places, most notably in the
CouchbaseConnectionFactoryBuilderclass.JCBC-461: Since only one streaming connection can be open, the number of Netty worker threads has been limited to 1, reducing the risk of opening more threads than needed in failure cases.
Known Issues in 1.4.2
-
JCBC-401: When durability requirements (
PersistToorReplicateTo) are used, a custom timeout such as.get(1, TimeUnit.MINUTES)is ignored if it is higher than the defaultobsTimeoutsetting for theCouchbaseConnectionFactoryclass. The work-around is to set a higher value throughCouchbaseConnectionFactoryBuilderand then just use.get()or a possibly lower timeout setting.
Release Notes for Couchbase Client Library Java 1.4.1 GA (8 May 2014)¶
The 1.4.1 release is the first bug fix release for the 1.4 series. It fixes very important issues found on the 1.4 branch, so all users running on 1.4.0 should upgrade.
Fixes in 1.4.1
SPY-163: A deadlock has been fixed in the
asyncGetBulkmethod (which is also facilitated by the view querying mechanism ifsetIncludeDocs(true)is used) that happened when an empty list of keys is passed in. This can happen also if a view request does not return results, so the empty list is passed down the stack, resulting in a thread that does not respond.SPY-167: A deadlock has been fixed that occasionally comes up as a race condition between adding a listener and notifying the already subscribed listeners. The behavior also has been cleared up so that a listener is notified only once.
JCBC-453, JCBC-457: Faster configuration fetching under certain conditions (if the new carrier configuration mechanism is used) if the cluster is unstable.
SPY-164, SPY-166, SPY-169: Increased robustness when cloning (redistributing/retrying) operations.
SPY-162: If a custom Nagle setting has been set through the builder, it is now also applied if a node gets reconnected after a socket close/service interruption.
SPY-168: The utility method
isJsonObjecthas been hardened to perform a null and empty string check before doing regular expression and string matching. This should prevent regex exceptions on specific JDK versions.
Known Issues in 1.4.1
-
JCBC-401: When durability requirements (
PersistToorReplicateTo) are used, a custom timeout such as.get(1, TimeUnit.MINUTES)is ignored if it is higher than the defaultobsTimeoutsetting for theCouchbaseConnectionFactoryclass. The work-around is to set a higher value throughCouchbaseConnectionFactoryBuilderand then just use.get()or a possibly lower timeout setting.
Release Notes for Couchbase Client Library Java 1.4.0 GA (15 April 2014)¶
The 1.4.0 release is the first production-ready release for the 1.4 series.
Here are some of the highlights of the 1.4.0 release. For more specific information, read the release notes for Developer Preview 1 and Developer Preview 2.
- Transparent, optimized connection management (support for Couchbase Server 2.5+ carrier publication feature)
- The total number of view rows are exposed on the
ViewResult. - (Async)ReplicaRead methods have been added that also return the CAS value in addition to the document itself.
- Additional asynchronous mutation methods have been exposed (increment and decrement with expiration and default).
- Type-safe status codes on the
OperationStatusmake it easier to check for error and success states. - Authentication timeouts are now customizable, and the error handling is much better around redistribution during authentication.
- A development pom.xml has been added to make it easier to contribute.
Known Issues in 1.4.0
-
JCBC-401: When durability requirements (
PersistToorReplicateTo) are used, a custom timeout such as.get(1, TimeUnit.MINUTES)is ignored if it is higher than the defaultobsTimeoutsetting for theCouchbaseConnectionFactoryclass. The workaround is to set a higher value throughCouchbaseConnectionFactoryBuilderand then just use.get()or a possibly lower timeout setting.
Release Notes for Couchbase Client Library Java 1.4.0, Developer Preview 2 (4 April 2014)¶
The 1.4.0-dp2 release is the second developer preview for the 1.4 series.
New Features and Behavior Changes in 1.4.0-dp2
JCBC-421: Rewriting the Query internals for better performance. The
Queryview object has been rewritten completely for much better performance, removing bottlenecks and allowing much quicker creation (especially if fields with a JSON type are used). The rewrite is completely transparent to the user, nothing needs to be changed on the application side.JCBC-426: Since Carrier Configuration and/or HTTP are selected automatically, there is now also a way to disable one of the two bootstrap phases manually. This is only exposed through a system property since it is not intended for everyday use. It should only be used when a failure is discovered in the new carrier configuration process and old behaviour needs to be used temporarily.
Either cbclient.disableCarrierBootstrap or cbclient.disableHttpBootstrap can be set to “true” to force disabling the bootstrap type. If you disable HTTP bootstrap against clusters < 2.5.0 or if you use memcached bucket types, bootstrapping will fail because they solely rely on the HTTP mechanism.
JCBC-436: In some scenarios, you might need to specify a larger auth timeout per node. This can be done through the
setAuthWaitTimesetting in theCouchbaseConnectionFactoryBuilderclass (in milliseconds, default is 2500).SPY-156: More (async) mutate methods are exposed, which helps with default settings and expirations. Their sync counterparts have been exposed previously already. The following async methods are now available:
Future<Long> asyncIncr(String key, long by, long def);
Future<Long> asyncIncr(String key, int by, long def);
Future<Long> asyncIncr(String key, long by, long def, int exp);
Future<Long> asyncIncr(String key, int by, long def, int exp);
Future<Long> asyncDecr(String key, long by, long def);
Future<Long> asyncDecr(String key, int by, long def);
Future<Long> asyncDecr(String key, long by, long def, int exp);
Future<Long> asyncDecr(String key, int by, long def, int exp);
- Add development pom.xml: A maven pom file has been added to the source code to make it easier to get set up with all the dependencies and therefore making it easier to contribute.
Fixes in 1.4.0-dp2
- General fixes and stabilization around the new carrier publication feature.
- SPY-158: The “max reconnect delay” on the factory builder incorrectly assumed seconds instead of the advertised milliseconds, leading to wrong reconnect behavior. This is now fixed and works as advertised on the builder.
- SPY-161: When an operation gets cancelled, now all its “children” get cancelled as well. Children get created if an operation needs to be cloned, for example on “not my vbucket” responses. This avoids the situation where operations are kept around longer than needed because their parent cancellation was never passed to them appropriately.
Known Issues in 1.4.0-dp2
-
JCBC-401: When durability requirements (PersistTo/ReplicateTo) are used, a custom timeout (for example
.get(1, TimeUnit.MINUTES))is ignored if it is higher than the defaultobsTimeoutsetting on theCouchbaseConnectionFactory. The workaround here is to set a higher value through theCouchbaseConnectionFactoryBuilderand then just use.get()or a possibly lower timeout setting.
Release Notes for Couchbase Client Library Java 1.4.0, Developer Preview 1 (25 February 2014)¶
The 1.4.0-dp release is the first developer preview for the 1.4 series.
New Features and Behavior Changes in 1.4.0-dp
- JCBC-337: Adding support for Carrier Configuration to the Java SDK. Carrier Configuration allows to fetch the cluster configuration over the binary protocol, removing the need for the HTTP streaming configuration on couchbase buckets. This only works in combination with Couchbase Server 2.5.0 and forward, otherwise - transparently - HTTP will still be used.
Note that if the cluster gets upgraded from < 2.5.0 to 2.5.0, HTTP will still be used on the client side. After a restart, Carrier Configuration will be picked up automatically.
From a configuration perspective, nothing needs to be changed on the application side, it will be automatically picked up if supported on the server side.
- JCBC-417: Replica support with the CAS value has been added.
The client now exposes the (async)GetsFromReplica methods, which work exactly like the (async)GetFromReplica, aside that they expose the CasValue instead of the object directly.
-
JCBC-240: The total number of rows returned for a View has been added to the
ViewResponse.
The #getTotalRows method exposes the total number of rows, which may be a superset of the rows returned (because the result has been filtered for one reason or another). Note that if used together with pagination (or any other “state imposing” mechanism), keep in mind that the total rows can change if the view itself changes.
-
SPY-153: A type-safe
StatusCodehas been added to theOperationStatusinstances, which makes it easier to compare responses, instead of having to compare strings which is rather error prone.
Here is a usage example:
OperationFuture<Boolean> set = client.set("statusCode1", 0, "value");
set.get();
assertEquals(StatusCode.SUCCESS, set.getStatus().getStatusCode());
GetFuture<Object> get = client.asyncGet("statusCode1");
get.get();
assertEquals(StatusCode.SUCCESS, get.getStatus().getStatusCode());
OperationFuture<Boolean> add = client.add("statusCode1", 0, "value2");
add.get();
assertEquals(StatusCode.ERR_EXISTS, add.getStatus().getStatusCode());
See the client documentation for a full list of status codes that can be returned in various situations.
Fixes in 1.4.0-dp
- SPY-155: A bug has been fixed where future listeners were not notified because of a race condition.
Known Issues in 1.4.0-dp
-
JCBC-401: When durability requirements (PersistTo/ReplicateTo) are used, a custom timeout (for example
.get(1, TimeUnit.MINUTES))is ignored if it is higer than the defaultobsTimeoutsetting on theCouchbaseConnectionFactory. The work-around here is to set a higher value through theCouchbaseConnectionFactoryBuilderand then just use.get()or a possibly lower timeout setting.