vBucketはCouchbaseクラスタのキー空間の部分集合の所有者として定義されています。これらvBucketsは、情報がクラスタ全体に効果的に分散できるように使われています。vBucketシステムは、データの配布と複数ノードでのレプリカ(バケットのデータのコピー)の両方をサポートするために使用します。
クライアントは、対応するvBucketへのノードと直接通信することにより、バケットに格納されている情報にアクセスします。プロキシや、再分散のアーキテクチャではなく、データを保持するノードにクライアントが直接アクセスすることができます。結果はデータの論理パーティショニングから物理トポロジーを抽象化しています。このアーキテクチャによって、CoucbaseServerは弾力性をもちます。
このアーキテクチャは、予め定義されたリストからサーバを決定するために、クライアント側のキーのハッシュ値を使用するmemcachedで使用されている方法とは異なります。これは、トポロジーの変更に対応するために、サーバ一覧のアクティブな管理や、Ketamaのように特殊なハッシュアルゴリズムを必要とします。この方法によって、RDBMSで用いられているような典型的なシャーディング方法よりも、フレキシブルに変化に対応することが可能です
注記
vBucketsは、ユーザーがアクセス可能なコンポーネントではありませんが、Couchbase Serverの重要な構成要素であり、可用性とエラスティック性のサポートには不可欠です。
すべてのドキュメントIDはvBucketに属します。マッピング関数は、与えられたドキュメントが属するvBucketを計算するために使用されます。Couchbase Serverでは、そのマッピング関数は、ドキュメントIDを入力として、vBucket識別子を出力するハッシュ関数です。vBucket識別子を計算し、そのvBucketを"ホスト"するサーバを探すためにテーブルを参照します。そのテーブルはvBucketごとに1行ずつ、vBucketとそれをホストするサーバのペア情報が含まれています。このテーブルに存在するサーバは複数のvBucketを担当することができます(通常そうなります)。
下の図は、サーバーへのマッピングキー(vBucketのマップ)の動作の仕組みを示しています。 クラスタ内には3つのサーバがあります。クライアントはKEYに対応する値を取得(get)しようとしています。クライアントはまずKEYを所有しているvBucketを特定するためにキーをハッシュ化します。この例では、ハッシュの計算によりvBucket 8 (vB8) となり、vBucketマップを調べて、クライアントはサーバCがvB8をホストしていると判別します。get操作は、サーバCに送信されます。
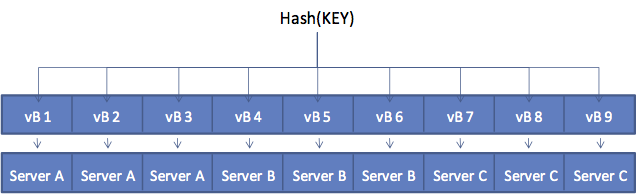
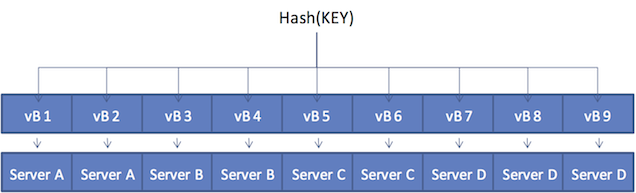
しばらくして、サーバーをクラスタに追加する必要があるとします。新しいノードであるサーバーDがクラスタに追加され、vBucketのマップが更新されます。
注記
vBucketのマップはリバランスしている間に更新されます。そして、更新されたマップは、他のノードや接続中の "スマート"クライアント、およびMoxiプロキシサービスを含むすべてのクラスタの参加者に送信されます。
新しい4ノードのクラスタモデルでは、クライアントが再びキーの値をgetしたいとき、ハッシュアルゴリズムでvBucket8 (vB8) を解決します。しかし新しいvBucketのマップは、vBucketをサーバーDにマッピングしています。クライアントは、情報を得るためにサーバーDと直接通信することとなります。