Couchbase Cluster Auto-scaling
The Kubernetes Operator can be configured to enable automatic scaling for Couchbase clusters.
About Couchbase Cluster Auto-scaling
The Kubernetes Operator provides the necessary facilities for Couchbase clusters to be automatically scaled based on usage metrics. Thresholds can be set for native Kubernetes metrics (such as pod CPU utilization) as well as Couchbase metrics (such as bucket memory utilization) that, when crossed, trigger horizontal scaling of individual server classes.
Auto-scaling doesn’t incur any cluster downtime, and allows for each Couchbase Service to be scaled independently on the same cluster. For example, the Data Service can automatically scale in response to fluctuations in memory utilization, while the Query Service can automatically scale in response to CPU utilization.
The sections on this page describe the conceptual information about Couchbase cluster auto-scaling. For information on how to configure and administrate auto-scaling using the Kubernetes Operator, refer to Configure Couchbase Cluster Auto-scaling.
| Auto-scaling only supports adding or removing pod replicas of the associated server class. Auto-scaling does not currently scale a cluster vertically by swapping pods with ones that have larger or smaller resource requests. By extension, the size of persistent storage also cannot be auto-scaled and must be manually re-sized if required. |
How Auto-scaling Works
The Kubernetes Operator maintains Couchbase cluster topology according to the couchbaseclusters.spec.servers section of the CouchbaseCluster resource.
Within this section, server classes are defined with, among other things, specifications for the following:
-
The specific Couchbase Services that should run on a particular pod
-
The resources that should be assigned to that pod
-
The number of replicas of that pod that should exist in the Couchbase cluster
CouchbaseCluster Resource with Three Server ClassesapiVersion: couchbase.com/v2
kind: CouchbaseCluster
metadata:
name: cb-example
spec:
servers:
- name: data (1)
size: 3
services:
- data
resources:
limits:
cpu: 4
memory: 16Gi
requests:
cpu: 4
memory: 16Gi
- name: query
size: 2
services:
- query
- index| 1 | This server class, named data, specifies that the Couchbase cluster should include 3 nodes running exclusively the Data Service, and that those nodes should each have 4 vCPU and 16Gi memory. |
This ability to have independently-configurable server classes is how the Kubernetes Operator supports Multi-Dimensional Scaling. Depending on the observed performance of a Couchbase cluster over time, its constituent server classes can be independently scaled to meet the demands of current and future workloads.
Auto-scaling extends this capability by allowing server classes to automatically change in size (number of nodes) when observed metrics are detected to have crossed above or below user-configured thresholds.
The Kubernetes Operator provides this capability through an integration with the Kubernetes Horizontal Pod Autoscaler (HPA).
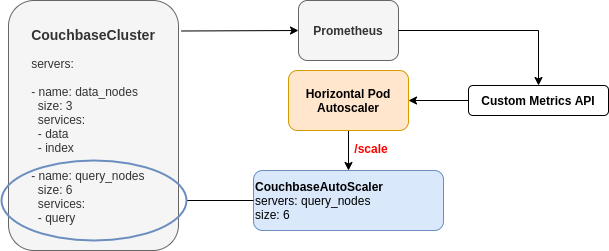
Cluster auto-scaling is fundamentally provided by the following components:
-
A
CouchbaseAutoscalercustom resource created and managed by the Kubernetes OperatorRefer to About the Couchbase Autoscaler
-
A
HorizontalPodAutoscalerresource created and managed by the userRefer to About the Horizontal Pod Autoscaler
-
A metrics pipeline configured and managed by the user
Refer to About Exposed Metrics
About the Couchbase Autoscaler
The Kubernetes Operator creates a separate CouchbaseAutoscaler custom resource for each server class that has auto-scaling enabled.
apiVersion: couchbase.com/v2
kind: CouchbaseCluster
metadata:
name: cb-example
spec:
servers:
- name: query
autoscaleEnabled: true (1)
size: 2
services:
- query| 1 | couchbaseclusters.spec.servers.autoscaleEnabled: Setting this field to true triggers the Kubernetes Operator to create a CouchbaseAutoscaler resource for the server class named query. |
Each CouchbaseAutoscaler resource is named using the format <server-class>.<couchbase-cluster>.
For the example above, the Kubernetes Operator would create a CouchbaseAutoscaler resource named query.cb-example.
Once created, the Kubernetes Operator keeps the size of the CouchbaseAutoscaler resource in sync with the size of its associated server class.
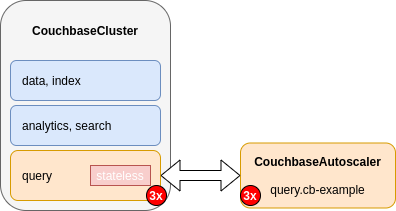
The CouchbaseAutoscaler resource acts as the necessary bridge between the HorizontalPodAutoscaler resource and the CouchbaseCluster resource.
The size of a CouchbaseAutoscaler resource is adjusted by the Horizontal Pod Autoscaler when the reported value of a user-specified metric crosses above or below a configured threshold.
Once the changes have been propagated from the HorizontalPodAutoscaler resource to the CouchbaseAutoscaler resource, the Kubernetes Operator will observe those changes and scale the server class accordingly.
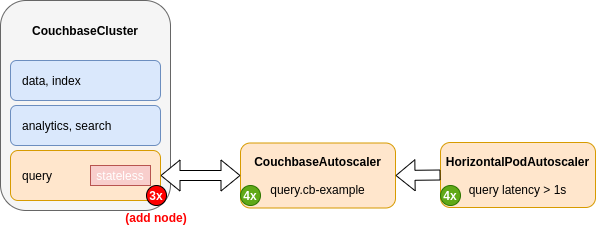
|
A |
Scale Subresource
The CouchbaseAutoscaler implements the Kubernetes scale subresource, which is what allows the CouchbaseAutoscaler to be used as a target reference for HorizontalPodAutoscaler resources.
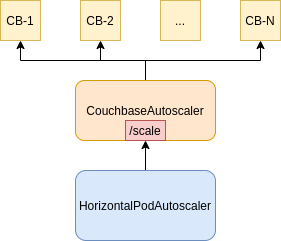
Implementing the /scale subresource allows CouchbaseAutoscaler resources to perform similar resizing operations to those of native Kubernetes deployments.
Therefore, manual scaling is also possible using kubectl:
$ kubectl scale couchbaseautoscalers --replicas=6 query.cb-exampleThe above command results in scaling the server class named query to support 6 replicas.
The Kubernetes Operator monitors the value of couchbaseautoscalers.spec.size and applies the value to couchbaseclusters.spec.servers.size.
The Horizontal Pod Autoscaler will reconcile the number of replicas with the last computed desired state.
Manual changes to the number of replicas will be reverted if the specified size falls outside of minReplicas or maxReplicas, or if the Horizontal Pod Autoscaler is currently recommending a different size.
|
About the Horizontal Pod Autoscaler
The Kubernetes Operator relies on the Kubernetes Horizontal Pod Autoscaler (HPA) to provide auto-scaling capabilities.
The Horizontal Pod Autoscaler is responsible for observing target metrics, making sizing calculations, and sending sizing requests to the CouchbaseAutoscaler.
The Horizontal Pod Autoscaler is configured via a HorizontalPodAutoscaler resource.
The HorizontalPodAutoscaler resource is the primary interface by which auto-scaling is configured, and must be manually created and managed by the user.
Simply enabling auto-scaling for a server class in the CouchbaseCluster resource will not result in any auto-scaling operations until a HorizontalPodAutoscaler resource has been manually created and configured to reference the appropriate CouchbaseAutoscaler resource.
The Kubernetes Operator has no facility for creating or managing HorizontalPodAutoscaler resources.
Deleting a CouchbaseCluster resource does not delete any associated HorizontalPodAutoscaler resources.
|
Referencing the Couchbase Autoscaler
A HorizontalPodAutoscaler resource needs to reference an existing CouchbaseAutoscaler resource in order for auto-scaling operations to occur for the associated server class.
This is accomplished by defining the scaleTargetRef settings within HorizontalPodAutoscalerSpec:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: query-hpa
spec:
scaleTargetRef:
apiVersion: couchbase.com/v2
kind: CouchbaseAutoscaler (1)
name: query.cb-example (2)| 1 | scaleTargetRef.kind: This field must be set to CouchbaseAutoscaler, which is the kind of custom resource that gets automatically created by the Kubernetes Operator when auto-scaling is enabled for a server class. |
| 2 | scaleTargetRef.name: This field needs to reference the unique name of the CouchbaseAutoscaler custom resource.
As discussed in About the Couchbase Autoscaler, CouchbaseAutoscaler resources are created with the name format <server-class>.<couchbase-cluster>. |
Target Metrics and Thresholds
The HorizontalPodAutoscaler resource must target a specific metric, along with an associated threshold for that metric.
The Horizontal Pod Autoscaler monitors the targeted metric, and when the reported value of that metric is observed to have crossed above or below the specified threshold, the Horizontal Pod Autoscaler will consider scaling the Couchbase cluster.
The HorizontalPodAutoscaler resource is capable of targeting any metric that is exposed to the Kubernetes API.
Target metrics can originate from a resource metric server or a custom metric server.
Refer to About Exposed Metrics for more information.
Targeting Couchbase Metrics
The following example shows how Couchbase metrics are targeted in the HorizontalPodAutoscaler configuration.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: query-hpa
spec:
scaleTargetRef:
apiVersion: couchbase.com/v2
kind: CouchbaseAutoscaler
name: query.cb-example
metrics:
- type: Pods (1)
pods:
metric:
name: cbquery_requests_1000ms (2)
target:
type: AverageValue (3)
averageValue: 7 (4)| 1 | When targeting Couchbase metrics, MetricSpec must be set to type: Pods. |
| 2 | The MetricIdentifier must include the name of the Couchbase metric to target for monitoring.
In this example, cbquery_requests_1000ms is specified, which is a metric that measures the number of requests that are exceeding 1000ms. |
| 3 | When targeting Couchbase metrics, the MetricTarget should be set to type: AverageValue so that the metric is averaged across all of the pods in the relevant server class. |
| 4 | averageValue is the value of the average of the metric across all pods in the relevant server class (as a quantity).
This is the threshold value that, when crossed, will trigger the Horizontal Pod Autoscaler to consider scaling the server class.
In this example, the value has been set to |
Label Selectors
Some Couchbase metrics may require the use of label selectors.
A label selector is defined in the MetricIdentifier and gets passed as an additional parameter to the metrics server so that metrics can be individually scoped.
To better understand the need for label selectors, and how to use them, consider the scenario of auto-scaling the Data Service based on memory utilization. Since each individual bucket reserves its own memory quota, it is almost never a good idea to scale the cluster based on the overall memory utilization of the Data Service. This is because buckets are likely to reach their own individual memory quotas before that of the Data Service. Therefore, when auto-scaling the Data Service based on memory utilization, it is better to do so based on the memory quotas of individual buckets.
The Couchbase metric for bucket memory utilization is cbbucketinfo_basic_quota_user_percent, and it is produced for each bucket in the cluster.
If this metric is targeted without any additional scoping, the Horizontal Pod Autoscaler will make its calculation based on the sum of the memory quota utilization values across all buckets across all data pods, which will likely cause erratic scaling behavior.
Therefore, label selectors are required for this metric to be scoped to individual buckets.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: data-hpa
spec:
scaleTargetRef:
apiVersion: couchbase.com/v2
kind: CouchbaseAutoscaler
name: data.cb-example
metrics:
- type: Pods
pods:
metric:
name: cbbucketinfo_basic_quota_user_percent (1)
selector:
matchLabels: (2)
bucket: travel-sample (3)
target:
type: AverageValue
averageValue: 70 (4)
- type: Pods
pods:
metric:
name: cbbucketinfo_basic_quota_user_percent
selector:
matchLabels:
bucket: default
target:
type: AverageValue
averageValue: 80| 1 | The name of the metric is defined in the same way as the previous example. |
| 2 | The MetricIdentifier is now defined with a label selector. |
| 3 | The label for the travel-sample bucket is specified, thus instructing the Horizontal Pod Autoscaler to monitor the value of cbbucketinfo_basic_quota_user_percent specifically for the travel-sample bucket. |
| 4 | averageValue in this example, is the average memory quota utilization of the travel-sample bucket across all data pods.
Setting a value of 70 means that the Horizontal Pod Autoscaler will auto-scale the number of data pods when specifically the travel-sample bucket crosses above or below 70% of its individual memory quota. |
Targeting Kubernetes Resource Metrics
The following example shows how Kubernetes resource metrics are targeted in the HorizontalPodAutoscaler configuration.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: query-hpa
spec:
scaleTargetRef:
apiVersion: couchbase.com/v2
kind: CouchbaseAutoscaler
name: query.cb-example
metrics:
- type: Resource (1)
resource:
name: cpu (2)
target:
type: Utilization (3)
averageUtilization: 70 (4)| 1 | When targeting Kubernetes resource metrics, MetricSpec must be set to type: Resource. |
| 2 | The ResourceMetricSource must include the name of the Kubernetes resource metric (e.g. cpu and memory) to target for monitoring.
In this example, cpu is specified, which is a metric that measures the pod CPU usage as a percentage. |
| 3 | When targeting Kubernetes resource metrics, the MetricTarget should be set to type: Utilization so that the metric is averaged across all of the pods in the relevant server class. |
| 4 | averageUtilization the value of the average of the resource metric across all pods in the relevant server class, represented as a percentage of the requested value of the resource for the pods.
This is the threshold value that, when crossed, will trigger the Horizontal Pod Autoscaler to consider scaling the server class.
In this example, the value has been set to 70.
As the Horizontal Pod Autoscaler monitors the target metric (cpu), it continuously takes the current sum of the reported value from each pod in the query server class, and divides it by the number of pods.
If resulting value ever crosses above or below 70, then the Horizontal Pod Autoscaler will consider scaling the number of query pods. |
Sizing Constraints
The Horizontal Pod Autoscaler applies constraints to the sizing values that are allowed to be propagated to the CouchbaseAutoscaler resource.
Specifically, defining minReplicas and maxReplicas within the HorizontalPodAutoscalerSpec sets lower and upper boundaries for the size of the server class.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: query-hpa
spec:
minReplicas: 2 (1)
maxReplicas: 6 (2)| 1 | minReplicas: This field sets the minimum number of Couchbase nodes for the relevant server class, and defaults to 1.
In this example, the value is set to 2, which means that the number of Couchbase nodes in the query server class will never be down-scaled to fewer than two nodes, even if the Horizontal Pod Autoscaler detects that the value for the target metric is below the target threshold.
Setting |
| 2 | maxReplicas: This field sets the maximum number of Couchbase nodes for the relevant server class.
This field is required and it cannot be set to a value lower than what is defined for minReplicas.
In this example, the value is set to 6, which means that the number of Couchbase nodes in the query server class will never be up-scaled to greater than six nodes, even if the Horizontal Pod Autoscaler detects that the value for the target metric is above the target threshold.
Setting a value for |
Refer to the algorithm details of the Horizontal Pod Autoscaler for additional information about how scaling decisions are determined.
Scaling Behavior
The Horizontal Pod Autoscaler provides fine-grained controls for configuring behaviors for scaling up and down.
These behaviors are configured via policies specified in the behavior field in the HorizontalPodAutoscalerSpec.
The following subsections describe some of the more relevant details related to configuring scaling behavior. For additional information and examples, refer to the Kubernetes documentation related to scaling policies.
Scaling Policies
behavior:
scaleUp: (1)
policies:
- type: Pods (2)
value: 1 (3)
periodSeconds: 15 (4)
selectPolicy: Max (5)
scaleDown:
policies:
- type: Percent
value: 100
periodSeconds: 15| 1 | Policies can be specified under scaleUp or scaleDown.
More than one policy can be specified, but a minimum of one policy is required for each action (unless policy selection is explicitly disabled).
If no user-supplied values are specified in the policy fields, then the default values are used. |
||
| 2 | The policy type can be Pods or Percent.
Note that for scaleUp policies, the Pods type is recommended for Couchbase.
Refer to Scaling Increments for more information. |
||
| 3 | Depending on the policy type, the value field represents either an absolute number of pods or a percentage of pods.
Note that for scaleUp policies with type: Pods, the recommended setting is 1.
Refer to Scaling Increments for more information. |
||
| 4 | The periodSeconds field defines the length of time in the past for which the policy must hold true before successive scaling changes in the same direction are allowed to occur.
|
||
| 5 | The selectPolicy field controls which policy is chosen by the Horizontal Pod Autoscaler if more than one policy is defined.
When set to Min, the Horizontal Pod Autoscaler selects the policy which allows the smallest change in the replica count.
When set to Max (the default), the Horizontal Pod Autoscaler selects the policy which allows the greatest change in the replica count.
|
The Kubernetes Operator can only auto-scale one server class at a time.
This is an important point to consider when enabling auto-scaling for multiple server classes on the same Couchbase cluster.
If any associated HorizontalPodAutoscaler resource makes a new scaling recommendation while the cluster is currently undergoing a scaling operation based on a previous recommendation, then the new recommendation will not be honored until the current scaling operation is complete.
For example, in a hypothetical scenario where the Kubernetes Operator has already begun scaling up a server class named data when another HorizontalPodAutoscaler resource recommends scaling up a server class named query on the same cluster, the Kubernetes Operator will not balance in any query replicas until the data server class has been scaled up to the desired size.
(Note that this scenario is only possible when the Couchbase Stabilization Period is disabled.)
|
Scaling Increments
It is possible to configure scaling policies for scaleUp and scaleDown that allow for scaling in increments of greater than one replica.
(In fact, the default policies of the Horizontal Pod Autoscaler allow for this.)
However, scaling up in increments of more than one replica is unlikely if sensible metrics/thresholds are set.
Therefore, this section is provided primarily for information purposes.
Though, it is still recommended to explicitly set the scaleUp increment to 1.
|
The value specified in the policy determines the maximum change in number of replicas that the Horizontal Pod Autoscaler can recommend in a single operation.
For example, if a pod scaleUp policy is set to value: 2, the Horizontal Pod Autoscaler is allowed to increase the size of the server class by up to two additional replicas in a single operation (e.g. from size: 2 to size: 3, or from size: 2 to size: 4).
The change in number of replicas being recommended by the Horizontal Pod Autoscaler is known as the scaling increment.
It’s important to remember that the Horizontal Pod Autoscaler makes recommendations by setting the target size for the server class.
For example, if the server class is currently running at size: 2, and the Horizontal Pod Autoscaler recommends scaling up by two additional replicas, the Horizontal Pod Autoscaler will institute its recommendation by setting the relevant CouchbaseAutoscaler resource directly to size: 4.
However, it is recommended that scaleUp policies be configured to only allow scaling in increments of one replica.
behavior:
scaleUp:
policies:
- type: Pods
value: 1 (1)
periodSeconds: 15| 1 | This policy specifies that the Horizontal Pod Autoscaler will only make scale-up recommendations in increments of one replica. |
Configuring the Horizontal Pod Autoscaler to scale up the server class by increments of one replica allows the targeted metric more opportunity to stabilize under the target threshold with less risk of over-scaling and causing additional rebalances. Before considering scaling up by larger increments, greater importance should be placed on identifying the most relevant metric and threshold for a given application, and then testing it under simulated workloads to confirm whether a larger scaling increment is called for.
The scaling increment does not have the same ramifications when scaling down as when scaling up.
Therefore it is recommended to keep the default scaleDown settings unless testing shows that non-default settings are needed.
Refer to Couchbase Cluster Auto-scaling Best Practices for help with identifying appropriate baseline metrics and thresholds.
Stabilization Windows
If the targeted metric fluctuates back and forth across the configured scaling threshold over a short period of time, it can cause the cluster to scale up and down unnecessarily as it chases after the metric. This behavior is sometimes referred to as "flapping" or "thrashing".
The Horizontal Pod Autoscaler and the Kubernetes Operator both provide different but equally important mechanisms to control the flapping of pod replicas. These controls, described in the subsections below, are meant to be used in tandem with each other, and should be tested using different permutations when determining the appropriate auto-scaling configuration for a particular workload.
Couchbase Stabilization Period
Both during and directly after a rebalance operation, some metrics may behave erratically while the cluster continues to stabilize. If the Horizontal Pod Autoscaler is monitoring a targeted metric that is unstable due to rebalance, it may lead the Horizontal Pod Autoscaler to erroneously scale the cluster in undesirable ways.
The Couchbase Stabilization Period is an internal safety mechanism provided by the Kubernetes Operator that is meant to help prevent the types of over-scaling caused by metrics instability during rebalance.
When the Couchbase Stabilization Period is specified, the Kubernetes Operator will put all HorizontalPodAutoscaler resources associated with the Couchbase cluster into maintenance mode during rebalance operations.
When in maintenance mode, the Horizontal Pod Autoscaler will not monitor targeted metrics, and therefore will stop making scaling recommendations.
Once the rebalance operation is complete, the Horizontal Pod Autoscaler will remain in maintenance mode for the duration of the stabilization period, after which it will resume monitoring metrics.
The Couchbase Stabilization Period is specified in the CouchbaseCluster resource.
apiVersion: couchbase.com/v2
kind: CouchbaseCluster
metadata:
name: cb-example
spec:
autoscaleStabilizationPeriod: 30s (1)| 1 | couchbaseclusters.spec.autoscaleStabilizationPeriod: When set to 0s, HorizontalPodAutoscaler resources will exit maintenance mode as soon as the cluster finishes rebalancing.
When set to a value greater than 0s, HorizontalPodAutoscaler resources will remain in maintenance mode for the specified amount of time after rebalance is complete.
|
It is important to note that once the HorizontalPodAutoscaler is reactivated that it will immediately access the targeted metrics and compare thresholds to determine if further scaling is required.
Another thing to keep in mind is that the Couchbase Stabilization Period forces all HorizontalPodAutoscaler resources associated with the Couchbase cluster into maintenance mode.
Therefore all server classes that have auto-scaling enabled will not be subject to scaling during this period.
In most scenarios, the native stabilization windows provided by the Horizontal Pod Autoscaler should provide the necessary controls for restricting the flapping of replicas. In general, the Couchbase Stabilization Period should only be used when the cluster needs additional time to stabilize after rebalance, or if the target metric can be adversely affected during rebalance (such as CPU and network I/O metrics). Refer to Couchbase Cluster Auto-scaling Best Practices for additional guidance on setting this value in production environments.
Horizontal Pod Stabilization
The Horizontal Pod Autoscaler provides a configurable stabilization window as a method to control undesirable scaling caused by fluctuating metrics.
When the Horizontal Pod Autoscaler calculates whether to scale the cluster, it looks backward in time at all of the previously desired sizes that were computed during the specified stabilization window and picks the largest value to use when computing the new desired size.
A stabilization window can be configured for both scaleUp and scaleDown.
behavior:
scaleUp:
stabilizationWindowSeconds: 30 (1)
policies:
- type: Pods
value: 1
periodSeconds: 15
scaleDown:
stabilizationWindowSeconds: 300 (2)| 1 | In this example, when the target metric indicates that the cluster should scale up, the Horizontal Pod Autoscaler will consider all desired states in the past 30 seconds. |
| 2 | In this example, when the target metric indicates that the cluster should scale down, the Horizontal Pod Autoscaler will consider all desired states in the past 5 minutes. |
If no stabilization window is specified for scaleUp or scaleDown, the Horizontal Pod Autoscaler uses a default value.
The default scaleDown stabilization window works well enough for most use-cases, and should not need to be modified.
However, the default value for scaleUp is 0, which is not ideal.
A minimum scaleUp stabilization window of 30 seconds is generally recommended, unless indicated otherwise in Couchbase Cluster Auto-scaling Best Practices.
About Exposed Metrics
Metrics play the most important role in Couchbase cluster auto-scaling. Metrics provide the means for the Horizontal Pod Autoscaler to measure cluster performance and respond accordingly when target thresholds are crossed. The Horizontal Pod Autoscaler can only monitor metrics through the Kubernetes API, therefore metrics affecting the Couchbase cluster must be exposed within the Kubernetes cluster in order to provide auto-scaling capabilities.
Resource Metrics
Resource metrics such as cpu and memory from pods and nodes are collected by Metrics Server, and exposed through the Kubernetes Metrics API.
Metrics Server may not be deployed by default in your Kubernetes cluster.
You can run the following command to check if Metrics Server is properly installed and exposing the necessary resource metrics:
$ kubectl get --raw /apis/metrics.k8s.io/v1beta1The response should contain an APIResourceList with the type of resources that can be fetched.
If you receive a NotFound error, then you’ll need to install Metrics Server if you plan on performing auto-scaling based on resource metrics.
Couchbase Metrics
Couchbase metrics need to be exposed through the Kubernetes custom metrics API in order to use them for auto-scaling. This is a requirement if you wish to use metrics like memory quota and query latency as targets to determine when auto-scaling should occur.
Couchbase metrics may be collected by the native Prometheus Endpoint that is exposed in Couchbase Server versions 7.0+.
You can run the following command to verify that your cluster is capable of performing auto-scaling based on metrics exposed by the Prometheus Endpoint:
$ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1If you receive a NotFound error then you will need to install a custom metrics service.
The recommended custom metrics service to use with the Kubernetes Operator is the Prometheus Adapter.
When performing auto-scaling based on Couchbase Server metrics, the discovery of available metrics can be performed through Prometheus queries that are beyond the scope of this document. However, the Couchbase Server docs contain a list of the Couchbase metrics available.
Couchbase Native Metrics
Couchbase Server version 7.0+ expose a Prometheus endpoint which can be used in conjunction with Prometheus Operator.
To configure your cluster for use with the Prometheus Operator, you must first install the kube-prometheus Project.
This project provides the ServiceMonitor custom resource that allows Prometheus to monitor the Couchbase metric service.
The following is an example ServiceMonitor that monitors metrics from a Couchbase cluster named cb-example:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: couchbase-prometheus
spec:
endpoints:
- interval: 5s
port: couchbase-ui (1)
basicAuth: (2)
password:
name: cb-example-auth
key: password
username:
name: cb-example-auth
key: username
namespaceSelector:
matchNames:
- default (3)
selector:
matchLabels:
app: couchbase (4)| 1 | Name of the Couchbase console service which exposes cluster metrics.
Requires couchbaseclusters.spec.networking.exposeAdminConsole is enabled to allow the creation of a service pointing to the Couchbase admin port. |
| 2 | Provides authentication to Prometheus for metric collection.
This secret must be created in the same namespace as the Prometheus Operator, that defaults to monitoring. |
| 3 | Namespace in which the Couchbase console service is running. |
| 4 | Match labels of the Couchbase console service. |
When the ServiceMonitor is created, a new Prometheus target is created which can be used for querying metrics.
About the Kubernetes Cluster Autoscaler
The Kubernetes Cluster Autoscaler provides the means to automatically scale the underlying Kubernetes cluster. Automatically scaling the Kubernetes cluster is recommended for production deployments as it adds an additional dimension of scalability for adding and removing pods because the underlying physical hardware is being scaled alongside of the Couchbase cluster. Also, since production deployments tend to schedule pods with specific resource limits and requests with performance expectations, Kubernetes cluster auto-scaling more easily allows for 1-to-1 matching of Couchbase pods with the underlying Kubernetes worker nodes without concern that a worker node is sharing resources with several Couchbase pods.
Couchbase cluster auto-scaling will work with Kubernetes cluster auto-scaling without any additional configuration. As the Horizontal Pod Autoscaler requests additional Couchbase pods, resource pressure will be applied (or removed) from Kubernetes, and Kubernetes will automatically add (or remove) the number of required physical worker nodes. The following tutorial provides a good explanation of how to use the Kubernetes Cluster Autoscaler: https://learnk8s.io/kubernetes-autoscaling-strategies
Several managed Kubernetes services such as EKS and AKS offer Kubernetes cluster auto-scaling. Refer to the Kubernetes Cluster Autoscaler FAQ for additional information about cloud providers that offer Kubernetes cluster auto-scaling.
Related Links
-
Tutorial: Auto-scaling the Couchbase Query Service
-
Tutorial: Auto-scaling the Couchbase Data Service
-
Tutorial: Auto-scaling the Couchbase Index Service
-
Reference: CouchbaseAutoscaler Resource
-
Reference: Auto-scaling Lifecycle Events