Couchbase Resource Label Selection
The Kubernetes Operator manages a Couchbase deployment by aggregating many different types of Kubernetes custom resources. By labeling resources, the Kubernetes Operator knows which resources to select and aggregate into a logical configuration.
Overview
The CouchbaseCluster resource does not contain a single, monolithic configuration for an entire Couchbase cluster.
Instead, configurations for things like buckets, replications, users, etc. are defined as separate resources, which the Kubernetes Operator then selects and aggregates into a logical configuration.
(One of the main reasons for this design is to allow for custom resource RBAC.)
All of the Couchbase resources outside of the main CouchbaseCluster type are collected by the Kubernetes Operator using a list operation in the namespace of the Couchbase cluster.
The list operation is optionally supplied with a user-defined label selector.
Any resource that has the same set of labels that match the label selector of a CouchbaseCluster resource will be aggregated.
Default Selection Behavior
Let’s take the CouchbaseBucket resource for example.
By default, when bucket management is enabled in the CouchbaseCluster, but no label selector is defined, the Kubernetes Operator will select and aggregate any "label-less" bucket resources for management on the cluster.
Refer to diagram below:
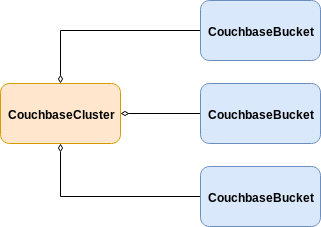
This default arrangement is well suited for when a single CouchbaseCluster resource is deployed in a single namespace.
However, when multiple CouchbaseCluster resources are deployed in the same namespace, this arrangement results in the Kubernetes Operator selecting and aggregating all CouchbaseBucket resources to all CouchbaseCluster resources — meaning that each cluster would be managing the same buckets.
Refer to diagram below:
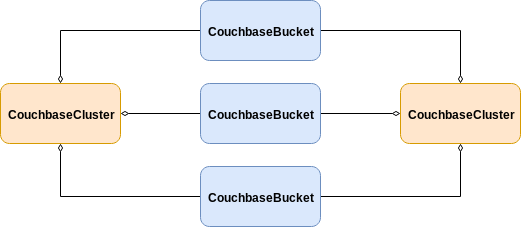
While you might desire the sharing of resources for the purposes of reducing configuration overhead, it can lead to surprising outcomes if you are not aware of the underlying selection algorithm.
For this reason, it is recommended that you specify explicit labels for resources, along with their corresponding label selectors for CouchbaseCluster resources.
This ensures that the Kubernetes Operator will only select and aggregate the appropriate resource for each cluster.
Using Resource Labels
To properly use resource labels, you’ll need to specify a label for each resource, as well as a corresponding label selector for each CouchbaseCluster resource.
It’s recommended that you start by adding a label selector to the CouchbaseCluster resource.
apiVersion: couchbase.com/v2
kind: CouchbaseCluster
metadata:
name: my-cluster
spec:
buckets:
managed: true
selector:
matchLabels:
cluster: my-clusterThe CouchbaseCluster configuration above will only select CouchbaseBucket resources that are labeled with cluster: my-cluster.
apiVersion: couchbase.com/v2
kind: CouchbaseBucket
metadata:
name: my-bucket
labels:
cluster: my-clusterThe reason for defining the label selector first is that without a label selector defined, the Kubernetes Operator will immediately aggregate any unlabeled resources to the CouchbaseCluster once it’s deployed.
As discussed in the previous section, this can have deleterious effects if you have more than one CouchbaseCluster resource already deployed in the same namespace.
However, by deploying the CouchbaseCluster resource with the bucket label selector cluster: my-cluster in this example, you can ensure that the cluster will only select CouchbaseBucket resources that have the matching cluster: my-cluster label.
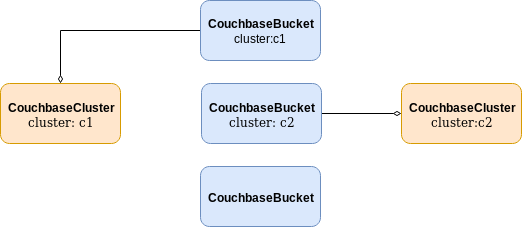
You might notice that in the above configuration examples, the cluster has the same name as the bucket label (my-cluster).
This is not a requirement and has no bearing on label selection.
Only what is specified in the selector and labels fields is used.
However, using the cluster name as the resource label can be helpful when you need to identify which cluster a resource is aggregated to.
|
Sharing Resources
Resource sharing can still be achieved with label selection in the following ways:
-
Multiple
CouchbaseClusterresources can have the same label selector defined. When a resource has the shared label, all of theCouchbaseClusterresources will select that resource. -
A resource can have multiple different labels. When different
CouchbaseClusterresources use different label selectors, they will share a resource if it has the labels required by both clusters.
In the previous sections, it was demonstrated that a bucket should be labeled such that it is specific to a cluster.
With XDCR replications, however, the selector is per-remote cluster.
Therefore, it is important to label and select replications so they are specific to a source cluster and a remote cluster.
But if you intend to replicate a bucket from a source cluster to all defined remote clusters, the system is flexible enough to do so with a single CouchbaseReplication resource.