Couchbase Scopes and Collections
From Couchbase Server 7 onward, all data and indexes belong to collections, collections are then grouped into scopes, and scopes belong to buckets. This page describes how this hierarchical data management works and how it is managed by the Operator.
Overview
|
This documentation refers to a Couchbase Server feature, particularly how it is represented by the Operator, and is accurate at the time of writing. Couchbase server may evolve over time, so consult the official documentation for up to date configuration limits and more detailed information. |
Consider the following conceptual diagram:
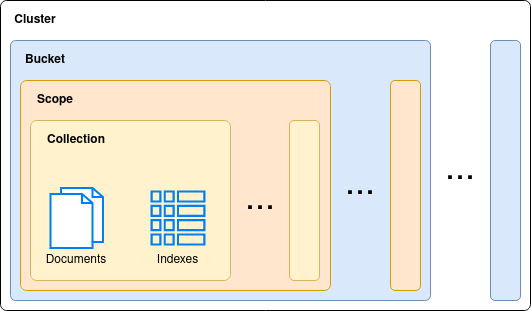
Collections
The finest-grained entity in a Couchbase cluster is the collection. A collection is — as it sounds — a collection of documents. Collections should be logical groupings of similar document types e.g. users, products, etc. This makes the logical organization of data far simpler than in versions of Couchbase Server prior to 7. Couchbase server currently supports up to 1000 collections per cluster.
Collections also contain indexes that apply to the collection’s documents. As indexes are specific to a collection, and a small subset of all documents on the system, this allows for higher performance and massive scalability of indexes. Couchbase server currently supports up to 10,000 indexes per cluster.
Collections enable fine-grain access control, and fine grain data replication with cross-datacenter replication (XDCR).
|
Legacy Behavior with Default Collections
To maintain the legacy behavior of Couchbase Server versions prior to 7, there is the concept of a default collection. A default collection belongs to the default scope of a bucket. Couchbase clients such as cross-datacenter replication (XDCR) and SDKs will transparently make use of a default scope and collection without any client-side configuration changes. A default collection cannot be modified, inheriting the configuration from the underlying bucket to maintain legacy behavior. A default collection can be deleted, but cannot be recreated. |
Scopes
A scope is simply a single-tier namespace for a group of collections to exist within. Collections within a scope must all have unique names, but collections in different scopes may share the same name. This property allows multi-tenancy.
For example, consider a white-box website that requires all the same collections to function. You can use scopes to define data collections with fixed names across all brands, while also allowing brand-specific configuration. Therefore it’s possible to create "cookie-cutter" websites with minimal modification to the client code, all that is required is to define what scope to use.
Scopes, and by extension multi-tenancy in general, allow high data density by aggregating multiple applications into a single database. To aid in this, scopes can define coarser-grain access control, and data replication, than collections.
|
Legacy Behavior with Default Scopes
Like collections, there is the concept of a default scope to maintain legacy behavior. Every bucket gets a default scope, and every default scope a default collection. The default scope is permanent, and cannot be deleted. |
Buckets
Buckets are the coarsest-grain data management entity. They may be used in a similar fashion to scopes by providing an additional layer of multi-tenant abstraction, however only a relatively limited number are supported.
Buckets act as namespaces, in the same manner as scopes. Buckets can also define coarse-grain access control and replication rules.
Configuration Precedence
In general, configuration applied to a bucket will be inherited by all the scopes and collections contained within, thus legacy applications using the default scope and collection, will continue to function with any RBAC or XDCR rules applied to buckets.
Where allowed, the most specific configuration will take precedence. For example, you can set the maximum time-to-live on documents at the bucket, and at the collection. As the collection is the finest-grained entity, it is the most specific, and so its time-to-live will be selected for documents in that collection.
Role-based access control is additive, so a role granted to a user at the bucket, will also apply to a collection within that bucket. Additional roles can be assigned to the user at the scope and collection level to provide escalated privilege.
Operator Data Model
Unsurprisingly — given the hierarchical nature of buckets, scopes and collections — the Operator models the topology with a directed graphs, or a forest of trees:
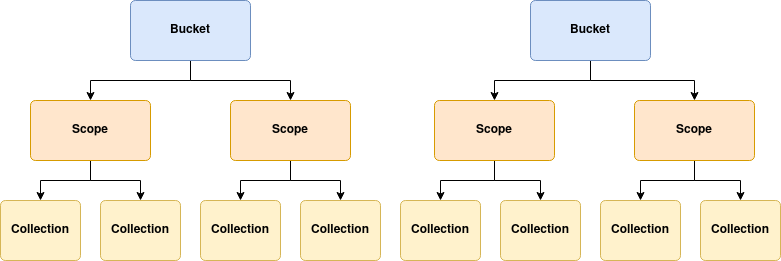
In this model, buckets refer to their set of desired scopes, and scopes to their set of desired collections.
There are two methods provided for one node to reference its children:
- Explicit reference
-
A bucket can directly reference a named scope resource, and a scope can directly reference a named collection resource. This is by far the easiest referencing method to understand, however when referencing hundreds of individual resources, the configuration can become quite unwieldy.
- Implicit reference
-
A bucket can reference scopes, and scopes can reference collections implicitly with Kubernetes label selection. Being able to mentally picture the relationship between tree nodes is difficult, however the configuration is greatly simplified in that a single selector can reference many resources.
Unlike the label selection that is used to select buckets by a
CouchbaseClusterresource — as described in the Kubernetes label selection, implicit referencing of scopes and collections defaults to "select nothing", rather than "select everything".
Both methods can be used at the same time if you so desire.
|
The remainder of this page will use explicit resource references due to clarity, however the two methods can be used interchangeably and yield the same result. |
Resource Grouping
As previously discussed in the scopes and collections overview, Couchbase Server can support up to 1000 collections. Using the basic data model as outlined above could potentially result in over 1000 resources to manage.
Not only is managing such a large number of resources difficult and error prone, but it also places a great strain on the Kubernetes control plane. For these reasons, we support — indeed recommend — the use of resource groups:
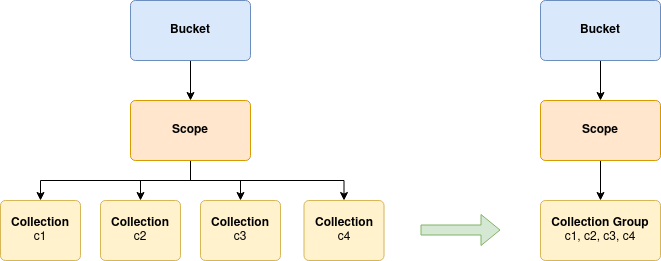
In the above example we have depicted four collections, however this could be any number. The Operator provides a collection group resource that allows the individual collections to be coalesced into a single resource.
Resource groups act like a template that is expanded at runtime. Internally, the Operator will take a collection group and expand it into a number of individual collections, each with a unique name — as defined by the collection group — and a set of common configuration parameters.
It is important to note that due to shared configuration, collection groups can only be used where all collections in the group are intended to have the same configuration.
Due to the flexibility of the data model, a scope can reference multiple collections, and collection groups at the same time. The collection groups can be used to define configuration shared among a subset of collections in a scope, with minimal configuration.
Resource groups can also form the basis of role-based access control rules, defining security boundaries.
While we’ve only illustrated the use of collection groups, the Operator also provides scope groups too that act in a similar fashion. This leads us on to resource sharing…
Resource Sharing
Consider the following progression:
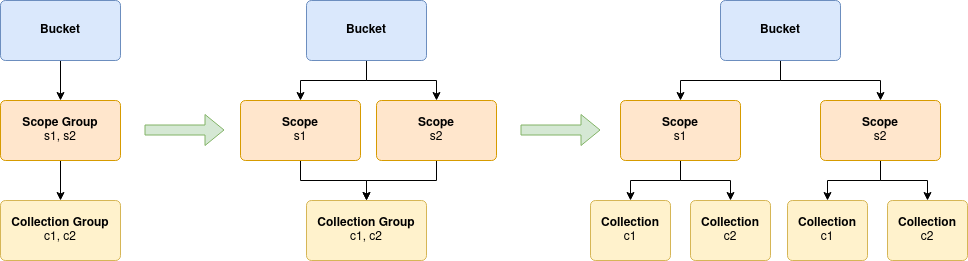
This depicts how the Operator would internally act upon a scope group, with a referenced collection group:
-
The first step shows the very terse configuration, we only require 3 resources to define this entire topology.
-
The next step shows the configuration after scope group expansion. What’s important to note here, is like collection groups, the configuration is shared by all instances of the scope group expansion, in particular the collection group.
-
The final step shows what the scopes and collections topology would look like in Couchbase Server.
In every step, the configuration is completely valid, and can be represented by Couchbase custom resource types.
The most interesting step is number two. Here we are showing that resources can be written once, and then shared between parent resources by simply referencing them.
This particular model is the shared-collection model, and fits nicely into the multi-tenancy use-case discussed in the scopes overview. We have defined a common set of collections (e.g. users, products, orders), that can be used by multiple scopes (e.g. brand 1, brand 2), and therefore you only need to write one group of collections and one client application in order to have multiple branded instances of the same application. The only modification that needs to be made by each client instance is to specify the scope to use.
It follows that the Operator also allows sharing of scopes by buckets:
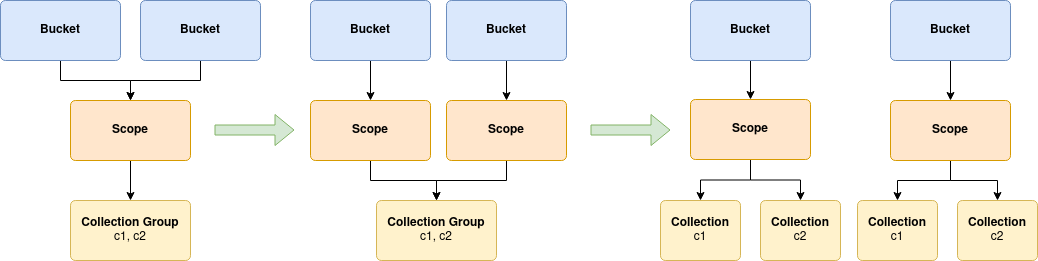
In this example, the illustrated scope is shared by multiple buckets. The end result is that each bucket contains the same set of scopes with the same sets of collections. This model is the shared-scope model.
It is very similar to the shared-collection model, but conceptually, it has a second layer of data organization and namespacing provided by the bucket. Again, this supports a multi-tenancy model.
Operator Configuration
The following shows how collections are configured:
apiVersion: couchbase.com/v2
kind: CouchbaseCollectionGroup
metadata:
name: my-collection-group (1)
spec:
names: (2)
- collection1
- collection2| 1 | The name of the resource in Kubernetes. This is the name explicitly referenced by a parent node. |
| 2 | For a resource group, the Kubernetes resource name plays no part in Couchbase configuration. Instead an explicit list of resource names, in this case corresponding to Couchbase collection names must be specified. |
The following shows how scopes are configured to reference collections:
apiVersion: couchbase.com/v2
kind: CouchbaseScope
metadata:
name: my-scope (1)
spec:
name: special$name (2)
defaultScope: false (3)
collections:
managed: true (4)
preserveDefaultCollection: false (5)
resources: (6)
- kind: CouchbaseCollectionGroup (7)
name: my-collection-group| 1 | The name of the resource in Kubernetes. This is the name explicitly referenced by a parent node. This is also the default collection name in Couchbase. |
| 2 | If specified, the specification name overrides the default resource name as the Couchbase collection name. This allows the use of characters valid for Couchbase collection names, that are not valid Kubernetes resource names. |
| 3 | If set to true, this scope represents the default scope.
Internally, this will ignore any name field, and use the internal default name.
The default scope can only be defined as a single scope, not with a scope group.
Internally all, buckets will have a default scope associated with them if one is not specified.
The implicit default scope will not be managed. |
| 4 | Control over collection management is opt in.
If set to true then the Operator will create and delete collections as referenced by the explicit resources, or the label selector.
If set to false then the Operator will make no attempt to manage collections within this scope, allowing explicit control by the end user. |
| 5 | When collections are managed, and this is the default scope, then this controls whether the default collection should be kept-alive or not.
If set to true then it will be preserved.
If set to false then it will be permanently deleted. |
| 6 | This defines a list of referenced collection resources. |
| 7 | Resources are referenced by resource kind — which may be CouchbaseCollection or CouchbaseCollectionGroup — and the Kubernetes resource name. |
The following shows how buckets are configured to reference scopes:
apiVersion: couchbase.com/v2
kind: CouchbaseBucket
metadata:
name: my-bucket
spec:
scopes:
managed: true (1)
resources: (2)
- kind: CouchbaseScope (3)
name: my-scope| 1 | Control over scope management is opt in.
If set to true then the Operator will create and delete scopes as referenced by the explicit resources, or the label selector.
If set to false then the Operator will make no attempt to manage scopes within this bucket, allowing explicit control by the end user. |
| 2 | This defines a list of referenced scope resources. |
| 3 | Resources are referenced by resource kind — which may be CouchbaseScope or CouchbaseScopeGroup — and the Kubernetes resource name. |