CREATE an External Collection
- Capella Analytics
- reference
This topic describes how you use the CREATE statement to create a collection so that you can query OLAP data on an external data source.
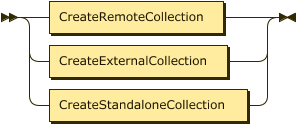
To create a link to an external data source, you use the Capella Analytics UI. See Set Up an External Data Source.
Syntax
CreateExternalCollection EBNF
CreateExternalCollection ::= "CREATE" "EXTERNAL" "ANALYTICS"? "COLLECTION" ("IF" "NOT" "EXISTS")?
QualifiedName
CollectionTypeDef?
"ON" Identifier
"AT" LinkName
( ( 'PATH' | 'USING' ) StringLiteral )?
"WITH" ObjectConstructorCreateExternalCollection Diagram
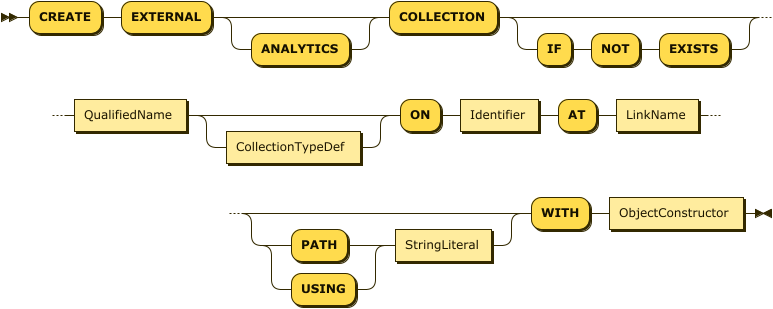
You must include the keyword EXTERNAL when creating this type of collection.
|
Show QualifiedName Diagram

Show CollectionTypeDef Diagram

Show CollectionFieldDef Diagram
Examples
The following examples create external Capella Analytics collections for data stored in cloud object stores.
Use backtick characters (``) to delimit identifiers that include the - operator symbol.
|
CREATE EXTERNAL COLLECTION music.myPlaylist.countrySongs
ON `data-music`
AT musicLink
PATH "music/myPlaylist/countrySongs"
WITH {"format": "json"};Show another example
CREATE EXTERNAL COLLECTION music.myPlaylist.rockSongs
ON `data-music`
AT musicLink
PATH "music/myPlaylist/rockSongs"
WITH {"format": "json"};Arguments
- ON
-
The
ONclause identifies the bucket or container name on the external data source, such as an Amazon S3 bucket, a Google Cloud Storage (GCS) bucket, or an Azure Blob Storage container. Supply only the name of the bucket or container, not a URL.
- AT
-
The
ATclause specifies the name of the link that contains credentials for the cloud object stores. The specified link must have the type of cloud object store.
- PATH
-
The
PATH, orUSING, clause is a string that specifies the location of the data files relative to the bucket name provided by theONclause. Do not supply a filename as part of the path.For example, the path can contain one or more cloud object stores prefixes delimited by slashes
/, such as:PATH "music/myPlaylist/rockSongs"For your query to include files located at the bucket, or top, level of the storage organization, you supply an empty path:
PATH ""External collections use the provided PATH to query the files in the specified location in the external object store. You can use the PATH to point to a desired subset of data only, leading to better performance as Capella Analytics does not query any files outside the provided PATH. For information about using dynamic prefixes in the path, which give you the ability to specify the exact prefix name in the WHERE clauses of your queries, see Design a Location Path and Optimize Performance of External Analytics Collections in Couchbase.
To specify particular filenames in the path to query, you can supply either an
includeor anexcludeparameter in theWITHclause.
- WITH
-
The
WITHclause enables you to specify parameters for the collection. ItsObjectConstructorrepresents an object containing key-value pairs, one for each parameter. You can define the following parameters.
| Name | Description | Schema |
|---|---|---|
format |
Specifies the format of the external data.
Accepts one of the following string values: |
enum: json, csv, tsv, parquet, avro |
table format |
An external dataset pointing to a Deltalake Table. This enables you to create external datasets based on Delta Lake tables.
|
Parquet |
decimal-to-double |
Delta DECIMAL values are converted to doubles, with the possibility of precision loss. The flag decimal-to-double must be set upon creating the dataset. |
Boolean |
timestamp-to-long |
By default, Delta timestamps are converted to long. Set this flag to |
Boolean |
date-to-int |
By default, Delta date are converted to int. Set this flag to |
Boolean |
timezone |
The timezone flag adjusts temporal types (e.g., DATETIME) stored in UTC within Delta table to a specified local timezone (e.g., PST). |
String |
header |
Only used if the format is CSV or TSV. |
Boolean |
escape |
Specifies the character used to escape the QUOTE and carriage return value. Default: same as the QUOTE value (the quote character is displayed twice if it appears in the data) |
String |
quote |
A character used to enclose strings. Default: " Value: NONE, ', " |
String |
redact-warnings |
Only used if the format is CSV or TSV. |
Boolean |
null |
Only used if the format is CSV or TSV. |
string |
exclude |
Applies only if the include parameter is not present. |
string, or array of strings |
include |
Applies only if the exclude parameter is not present. |
string, or array of strings |
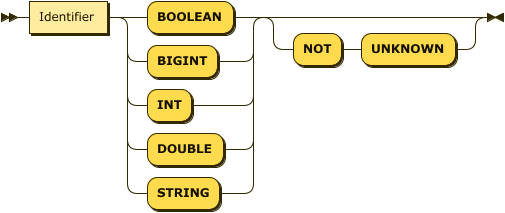
- CollectionTypeDef
-
You use the
CollectionTypeDefif the files in the external data store have a format of CSV or TSV. It consists of a comma-separated list of field definitions and their desired field types. These definitions guide the transformation of each CSV or TSV record into a JSON object. Each field definition consists of:-
The name to assign to the field.
-
The data type of the field. This can be any of the primitive data types, where
INTis an alias forBIGINT. If the field does not contain a value of this data type, Capella Analytics ignores the record and issues a warning. -
Optionally, the
NOT UNKNOWNflag. When this flag is present, if this field ismissingornull, Capella Analytics ignores the record.
-
Data in JSON, CSV, or TSV format can be in compressed gzip files, with the extension .gz or .gzip.
For more information about external collections, see Set Up an External Data Source.
Data Type Mapping: Parquet and Avro
For files that have a format of Parquet or Avro, Capella Analytics maps data types as follows:
| Parquet/Avro Data Type | Capella Analytics Data Type |
|---|---|
INT |
INT |
LONG |
INT |
FLOAT |
DOUBLE |
DOUBLE |
DOUBLE |
BYTES |
BINARY |
STRING |
STRING |
BOOLEAN |
BOOLEAN |
NULL |
NULL |
Union (nullable)* |
NULL/ANY |
Record |
OBJECT |
Array |
ARRAY |
MAP |
ARRAY of OBJECT in the form |
*Avro only