Views and Tabular Views
- Capella Analytics
- reference
This topic describes views and tabular views.
Views are virtual collections derived from actual stored collections. You can use views to present a subset of stored data, or to present a join or other transformation of stored data for some particular purpose.
Queries operate on views in the same way that they do on real stored data. In fact, a query can refer to both a stored collection and a view, perhaps joining them together. Views are not materialized. When a query refers to a view, the definition of the view is merged with the query to produce the desired result.
Examples in this topic use the sampleAnalytics database and the Commerce scope.
Refer to Example Data to install this example data.
To set the database and scope for a statement, you can use a USE Statements.
USE sampleAnalytics.Commerce;If you’re using the UI, you can use the query editor’s Query Context lists to set the database and scope.

Create a View
You can create a view by using a CREATE statement with the following syntax:
CreateView
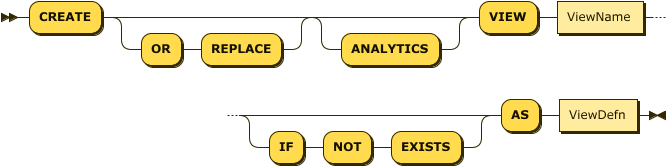
ViewName

ViewDefn
The CREATE VIEW statement specifies the QualifiedName of the view and the definition of the view.
The view definition is often the result of a query that defines the content, or it can be the QualifiedName of a collection or another view.
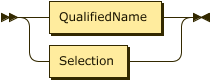
A view-defining query must conform to the syntax of a Selection.
That is, your query can include optional clauses such as WITH, UNION, and SELECT VALUE.
The QualifiedName of the view consists of an optional database name and optional scope name followed by an identifier.
For information about how Capella Analytics organizes entities into a database.scope.database_object hierarchy and resolves names, see Entities in Capella Analytics Services.
The database and scope where you create the view become the defaults for resolving names in the ViewDefn expression or query—the body of the view definition.
Views share the same namespace as collections. This means that you cannot create a view with the same name as another view or collection in the same scope. However, views and collections do not share the same namespace as synonyms: a synonym can coexist with a view or collection with the same name in the same scope. In this case, the view or collection takes precedence over the synonym.
The OR REPLACE and IF NOT EXISTS clauses specify the action to take if a view already exists with the specified name, as follows:
-
If you do not specify either
OR REPLACEorIF NOT EXISTS, an error results. -
If you specify only
OR REPLACE, the new view definition replaces the existing one. -
If you specify only
IF NOT EXISTS, Capella Analytics ignores the statement and retains the existing view definition. -
If you specify both of these clauses, an error results because the clauses contradict each other.
Examples
These examples use the Commerce example dataset.
The following view operates on the customers collection, showing the custid, name, and rating of each customer with a rating greater than 700, omitting the customer’s address.
CREATE VIEW good_customers AS
SELECT custid, name, rating
FROM customers
WHERE rating > 700;
To see which customers meet this rating threshold, query the good_customers view.
The following view unnests or flattens the items in each order and aggregates them to compute the total revenue for each order.
CREATE VIEW orders_summary AS SELECT o.orderno, o.order_date, o.custid, sum(i.qty * i.price) AS revenue FROM orders AS o UNNEST o.items AS i GROUP BY o.orderno, o.order_date, o.custid;
You can use the orders_summary view in the next query, which lists orders in the year 2020 that had more than 1000 in total revenue, in descending order by revenue.
SELECT s.orderno, s.order_date, s.revenue FROM orders_summary AS s WHERE date_part_str(s.order_date, "year") = 2020 AND s.revenue > 1000 ORDER BY revenue DESC;
You can find the metadata for views in the Metadata.`Dataset collection, identified by DatasetType = "VIEW".
For example:
SELECT *
FROM Metadata.`Dataset`
WHERE DatasetType = "VIEW";In the Capella Analytics UI, views and tabular views appear in the explorer of the workbench.
Create a Tabular View
A tabular analytics view (TAV) or tabular view is a special kind of view that enables Capella Analytics to interact with software tools that are designed to act on relational databases. A TAV always presents data in the form of a table, with uniform rows and columns and with a well-defined schema. Like any view, you can query a TAV with an ordinary SQL++ for Capella Analytics query. However, because its data is in the form of a table, a TAV is also accessible to relational tools.
Capella Analytics provides connectors to business intelligence tools that export TAVs so that you can visualize relational data. These connectors enable Tableau and Power BI to execute SQL queries against TAVs.
You use a CREATE VIEW statement with certain additional clauses to create a TAV, using the following syntax:
CreateTabularView
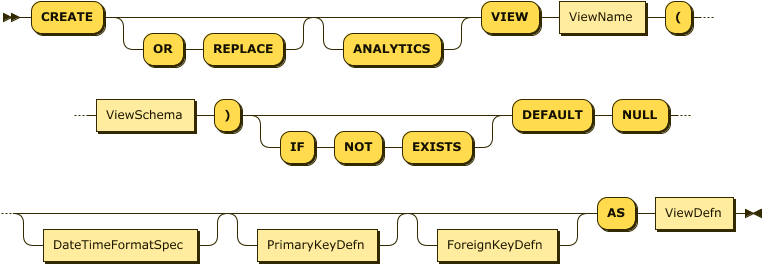
ViewSchema
ColumnName

ViewTypeRef
DateTimeFormatSpec

PrimaryKeyDefn

ForeignKeyDefn

SQL++ for Capella Analytics handles the clauses that are in common with a CREATE VIEW statement in the same way.
Details about the additional clauses follow.
Arguments
- ViewSchema
-
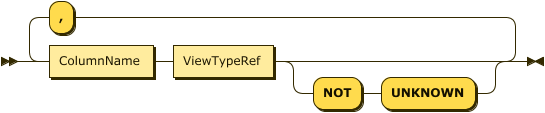
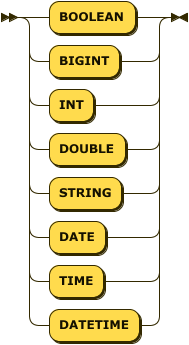
This clause identifies the view as a TAV and specifies the column names of the resulting table and their data types. TAVs support the following data types:
BOOLEAN
STRING
BIGINTor its synonymINT
DOUBLE
DATE(includes date only, no timezone)
TIME(includes time only, no timezone)
DATETIME(includes date and time, no timezone)Capella Analytics casts the values returned by the view definition query into the data type specified for each column. Whenever this casting process fails, the query returns a NULL value with a warning message. Columns that you designate as
NOT UNKNOWNin theViewSchemacannot contain NULL or MISSING values. The view excludes any row that has a NULL or MISSING value in a NOT UNKNOWN column from the view.Columns that you include in the PRIMARY KEY clause are automatically treated as NOT UNKNOWN columns.
- DEFAULT NULL
-
This required clause documents that Capella Analytics replaces missing data values by NULL, unless you specify NOT UNKNOWN for the column. This convention is necessary because relational databases use NULL to represent missing values.
- DateTimeFormatSpec
-
This clause specifies the format used to represent values in columns of type DATE, TIME, and DATETIME. For information about permissible formats, based on the ISO 8601 Standard, see Temporal Formats. If you do not specify formats, Capella Analytics applies these default formats:
For DATE columns:
"YYYY-MM-DD"
For TIME columns:"hh:mm:ss.s"
For DATETIME columns:"YYYY-MM-DDThh:mm:ss.s"Capella Analytics ignores time zones appearing in TIME or DATETIME values.
- PRIMARY KEY and FOREIGN KEY
-
These optional clauses allow you to specify which columns in the TAV serve as primary or foreign keys. Tools like the Tableau Connector can access and exploit this information. However, because Capella Analytics does not enforce the primary and foreign key relationships, these specifications require the NOT ENFORCED clause. The
QualifiedNamefollowing REFERENCES in a FOREIGN KEY clause must be the name of a TAV. These specifications can include self-references. For example, themanagerfield in anemployeeview might be a foreign key referencing another row in theemployeeview.
- ViewDefn
-
SQL++ for Capella Analytics handles the view definition body, which is often a query, in the same way as in an ordinary CREATE VIEW statement. However, the view definition must generate tabular data with column names that match the column names in the
ViewSchema, and the values in these columns must be castable into the types specified in theViewSchema. If the casting process fails, Capella Analytics returns a NULL value, or, if NOT UNKNOWN is specified, excludes the row. The correspondence between the column names in theViewSchemaand the column names generated by theViewDefnis based on name-matching, not on relative position. In other words, each column in theViewSchemamust have a column in theViewDefnwith the same name and a compatible, castable type, but the columns need not be in the same order.
Examples
The simplest form of a TAV makes an existing collection available for querying by relational tools. This is possible if the existing collection already has a tabular form—that is, it consists of an array of objects with no nested arrays or nested objects.
Suppose that a standalone collection named staff contains the following data:
[
{ "empno": 105, "name": "B. Happy", "hiredate": "03/15/2021"},
{ "empno": 107, "name": "Y. Knott", "hiredate": "06/30/2021"}
]You can make this collection available to SQL queries by creating the following TAV.
The view definition provides the schema information expected by relational tools.
The DATE clause is necessary because the dates have MM/DD/YYYY format instead of the standard ISO 8601 format.
CREATE OR REPLACE VIEW staff_table (
empno BIGINT,
name STRING,
hiredate DATE
)
DEFAULT NULL
DATE "MM/DD/YYYY"
AS staff;You can make data that includes nested objects accessible to relational tools by applying a process called normalization. TAVs use normalization to convert the nested data into tabular form. The following examples apply normalization techniques to the Commerce example dataset.
This definition of customers_view flattens the nested objects in the address object. The resulting view contains fields for addr_street, addr_city, and addr_zipcode.
CREATE OR REPLACE VIEW customers_view (
custid STRING, name STRING, rating BIGINT,
adr_street STRING, adr_city STRING, adr_zipcode STRING)
DEFAULT NULL
PRIMARY KEY (custid) NOT ENFORCED
AS
SELECT custid, name, rating, address.street AS adr_street,
address.city AS adr_city, address.zipcode AS adr_zipcode
FROM customers;If each object in a collection contains a nested array of objects, you can remove the nested array from the main view table and put it into a side view table.
A foreign key links the side table to the main table.
The view definition in the following example uses this technique, which is common in traditional relational schema design.
This example moves the items array from orders into a separate tabular view.
CREATE OR REPLACE VIEW orders_view (
orderno BIGINT, custid STRING, order_date DATE, ship_date DATE)
DEFAULT NULL
PRIMARY KEY (orderno) NOT ENFORCED
FOREIGN KEY (custid) REFERENCES customers_view NOT ENFORCED
AS
SELECT orderno, custid, order_date, ship_date
FROM orders;CREATE OR REPLACE VIEW items_view (
orderno BIGINT, itemno BIGINT, qty BIGINT, price DOUBLE)
DEFAULT NULL
PRIMARY KEY (orderno, itemno) NOT ENFORCED
FOREIGN KEY (orderno) REFERENCES orders_view NOT ENFORCED
AS
SELECT o.orderno, i.itemno, i.qty, i.price
FROM orders AS o UNNEST o.items AS i;Business intelligence tools can use the resulting normalized tabular view schema as if it was relational data. This includes the possibility of referencing TAVs in queries produced by user actions in BI tools.
Use Indexes with Views
You can use indexes to improve performance of queries on views, including TAVs. You must create the index on the underlying collection rather than on the view itself. For more information about the creation and use of indexes in Capella Analytics, see Using Indexes.
When you create an index to support a TAV, include an additional CAST clause in the CREATE INDEX statement.
This clause specifies how to cast each data value into a specified type before indexing, and that, if the cast fails, to index the data value as NULL.
The CAST clause can also specify DATE, TIME, or DATETIME formatting if other than the standard ISO 8601.
IndexCastDefault

Examples
The orders_summary view defined in the second example, is based on the orders collection and contains a custid field.
The following statement creates an index on the custid field of the underlying collection.
This index might improve performance of queries that search for the orders of a particular customer, either through the orders table or through the orders_summary view.
This example does not require a CAST clause because orders_summary is not a tabular view (TAV).
CREATE INDEX idx1 ON orders(custid:STRING);
The next example creates an index that might improve the performance of queries that search for staff members hired on a particular date.
It can be used against either the staff collection or the example tabular view named staff_table.
You include the DATE clause in this statement because the hiredate values use a nonstandard format.
CREATE INDEX idx2 ON staff(hiredate:DATE) CAST(DEFAULT NULL DATE "MM/DD/YYYY");
Drop a View
You can drop any view or TAV using the following statement:
DropView

The QualifiedName identifies the view to drop.
For information about how Capella Analytics organizes entities into a database.scope.database_object hierarchy and resolves names, see Entities in Capella Analytics Services.
When you drop a view, note the following:
-
If the target database or scope does not exist, the
DROPstatement fails. -
If the target database or scope exists but does not contain a view with the specified name, the
DROPstatement fails unless you specify IF EXISTS. -
If a collection with the same name exists in the target scope, the
DROPstatement fails. -
If an existing view or user-defined function depends on the view to drop, the
DROPstatement fails.
When you drop a view, Capella Analytics deletes its descriptive metadata from the System.Metadata.`Dataset` collection, and removes the view from the explorer in the workbench.