This section lists all supported DDL statements in Couchbase Analytics.
| A user must have one of the following RBAC roles to be able to execute DDL statements: Admin, Cluster Admin, Analytics Admin, or Analytics Manager. |
No CREATE/DROP or CONNECT/DISCONNECT statement can
be executed while the cluster topology changes (e.g. during rebalance). The evaluation of such DDL statements will fail
and it can be reattempted after the topology change has completed.
|
Entities
These are the entities that are required to create shadow copies of the Data Service keyspaces.
Analytics Scopes
An Analytics scope, or dataverse, is a container for the other Analytics entities
(links, collections, synonyms, indexes).
There is one Default Analytics scope that is available without creating it and that cannot be deleted.
Because the Default Analytics scope is always available, creating an Analytics scope is optional.
In Analytics, there is no entity equivalent to a Data service bucket, such as travel-sample:
the Analytics scope is the top-level entity.
To facilitate data sharing between the Data service and Couchbase Analytics,
an Analytics scope name can have one or two parts,
in which the first part represents a Data service bucket and the second part represents a Data service scope — this enables you to simulate the hierarchy of buckets and scopes used in the Data service.
Similarly, in Couchbase Analytics, there is no entity equivalent to a Data service namespace,
such as the default: namespace.
Analytics scope names cannot contain a colon as a separator.
When creating an Analytics scope and collection to shadow a Data service keyspace, you must simply omit the namespace.
Refer to Create Statements, Alter Statements, Use Statements, and Drop Statements.
Analytics Collections
An Analytics collection, or dataset, is a collection of data within an Analytics scope. By default, an Analytics collection is linked to the Data service of the local Couchbase cluster. This type of Analytics collection may be referred to as a local Analytics collection, or simply as an Analytics collection without qualification.
Local Analytics collections contain a shadow of the data of a keyspace.
An Analytics collection is updated as the keyspace that it shadows is updated.
An Analytics collection can contain the full content of the keyspace or a filtered subset.
Multiple Analytics collections can shadow the same keyspace.
An Analytics collection is created ON a keyspace with an optional filter expression.
The name of the Analytics collection is optional and defaults to the name of the keyspace.
Creating an Analytics collection fails if there is an existing Analytics collection with the same name
in the selected Analytics scope and IF NOT EXISTS is not specified.
Refer to Create Statements, Alter Statements, and Drop Statements.
Remotely-Linked Collections and External Collections
You can also create Analytics collections on remote links and external links. These enable you to query data from outside the local Couchbase cluster.
-
An Analytics collection on a remote link shadows the data from a remote Couchbase cluster to a local Analytics collection.
-
An external Analytics collection reads data directly from an external source, such as Amazon S3, without shadowing it locally.
| Backup and restore only operates on Analytics collections on the local link. Only the Analytics collection definition is backed up or restored, not the actual data. Backup and restore excludes Analytics collections on remote links and external links entirely. |
Before you can create an external Analytics collection, or an Analytics collection on a remote link, you must first create the appropriate link for your Analytics collection to use.
Refer to Remote Links and External Links, Create Statements, and Drop Statements.
Manage Collections with the Analytics Workbench
You can use the Analytics Workbench to create or drop Analytics collections on local links, remote links, and external links; and to connect or disconnect local links and remote links. Refer to Managing Collections.
Analytics Synonyms
An Analytics synonym is an alternative name for an Analytics collection. You can use a synonym anywhere that you would otherwise use the name of an Analytics collection. More information on how synonyms are resolved can be found in Appendix 3: Variable Bindings and Name Resolution.
Refer to Create Statements, Alter Statements, and Drop Statements.
Links
In Analytics, a link represents a connection to a data source.
The default type of link is a Local link.
The Local link represents a connection to the Data service on the local Couchbase cluster,
specifically to all keyspaces available to a specific user on the local cluster.
Every Analytics scope implicitly contains a Local link for all keyspaces in the local cluster that are available to the
current user.
In Couchbase Server 7.0 and later, the Local link for each Analytics scope is connected by default.
When you create a new Analytics collection on a connected link, data ingestion to that collection begins immediately.
You can disconnect the Local link to pause data ingestion to the local Analytics collections in that scope.
| You can always create or drop an Analytics collection on any link, even if the link is already connected, and even if the data source already has existing shadow Analytics collections. If the link is connected when you create a new Analytics collection, data ingestion to the new shadow Analytics collection starts at once. |
Refer to Connect Statements and Disconnect Statements.
Remote Links and External Links
You can also create remote links and external links. These enable you to access data from outside the local Couchbase cluster.
-
A remote link is a link to a remote Couchbase cluster.
-
An external link is a link to an external data source, such as Amazon S3.
After you have created a remote link or an external link, you must create an Analytics collection on that link to query the data.
A remote link is disconnected by default. When you create a new Analytics collection on a disconnected link, data ingestion to that collection does not begin immediately. You must connect the remote link to start data ingestion to the Analytics collections on that link.
An external link cannot be connected or disconnected. An external Analytics collection is available for query as soon as you create it.
To create, edit, or delete a remote or external link, you can use the command-line interface or the REST API. Refer to couchbase-cli analytics-link-setup or Analytics Links REST API.
Manage Links with the Analytics Workbench
You can also use the Analytics Workbench to create, edit, or delete remote links and external links. Refer to Managing Links.
Indexes
An index is a materialized access path for data in an Analytics collection.
You can create more than one index on the same Analytics collection.
Each index name must be unique within an Analytics collection.
Creating an index fails if there is an existing index with the same name
in the target Analytics collection and IF NOT EXISTS is not specified.
For each JSON document ingested into an Analytics collection, the system computes the indexed key for each index. The index key of a secondary index is computed as follows:
-
The target field values are extracted from the JSON document according to the specified path of fields;
-
For non-numeric typed index fields (i.e., the specified type is
STRING), if the specified type of the field is the same as the actual field value’s type, the value becomes part of the indexed key, otherwise the indexed key cannot be built; -
For numeric typed index fields (i.e., the specified type is
DOUBLEorBIGINT), the actual field value can be cast to the specified type and it becomes part of the indexed key. If the cast is impossible, the indexed key cannot be built;
After the indexed key has been built, it is inserted into the secondary index. In case the index key cannot be built, there is no entry made in the index for this object.
Secondary indexes are automatically maintained by the system during data ingestion (i.e., when their corresponding links are connected and populating their Analytics collections). In addition, they are automatically rebalanced when their shadow Analytics collections are rebalanced.
Refer to Create Statements and Drop Statements.
Array Indexes
Couchbase Analytics also provides array indexes, which enable you to index values within an array, or fields within an object nested in an array.
You can create an array index by providing a sequence of UNNEST and SELECT keywords to identify the field to be indexed.
There are some differences between array indexes and standard indexes concerning the types of data that they can contain, and how the query optimizer utilizes them. Refer to Using Indexes and Array Index Parameter.
Functions
For details about user-defined functions, refer to User-Defined Functions and Appendix 5: Python UDFs.
Views
For details about views and tabular views, refer to Analytics Views.
Statements
In addition to queries, SQL++ for Analytics (the Couchbase Analytics implementation of SQL++) supports statements for data definition, and to connect Couchbase Analytics to Data Service keyspaces or external data sources.
Stmnt

SingleStmnt
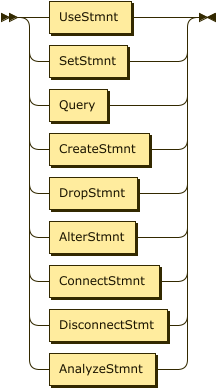
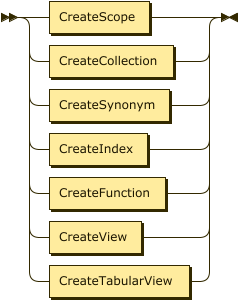
Create Statements
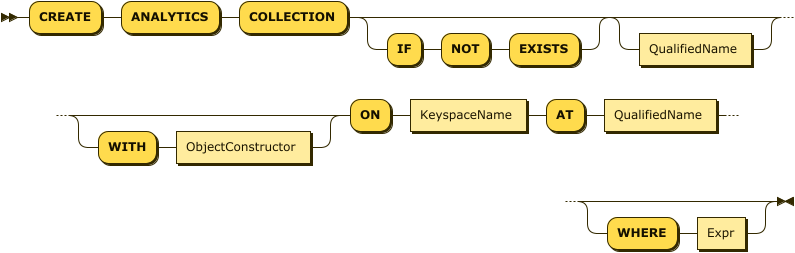
The CREATE statement is used to create Analytics scopes, collections, synonyms, and indexes.
CreateStmnt
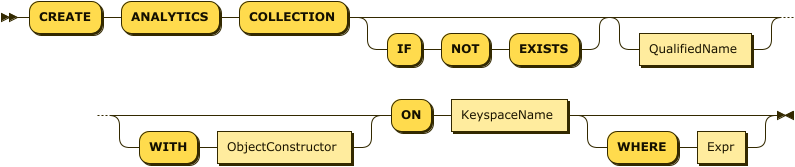
Analytics Scope Specification

Analytics Collection Specification



CollectionFieldDef
The QualifiedName is the full name of the Analytics collection to create.
It consists of an optional Analytics scope name and a name for the Analytics collection.
If no Analytics scope name is given,
the Analytics collection is created in the scope defined by the immediately preceding USE statement,
or the scope defined by the query_context parameter, or the Default Analytics scope,
according to the rules for Resolving Database Entities.
The QualifiedName may be omitted if you are creating a local Analytics collection,
or an Analytics collection on a remote link,
and the data source is just a bucket name — refer to the ON clause below.
The ON clause enables you to specify the data source for the Analytics collection.
For a local Analytics collection,
the KeyspaceName in this clause represents the keyspace which this Analytics collection will shadow.
For an Analytics collection on a remote link,
the KeyspaceName in this clause represents a keyspace on the remote Couchbase cluster.
For an external Analytics collection, the Identifier in this clause represents an external data source,
such as an Amazon S3 bucket.
The KeyspaceName may consist of a bucket name, followed by an optional scope name and collection name.
It may not contain a namespace — the default: namespace is assumed.
If the KeyspaceName contains just a bucket name,
the Data service scope is assumed to be the default scope within that bucket,
and the Data service collection is assumed to be the default collection within that scope.
Note also that if the KeyspaceName contains just a bucket name,
the QualifiedName of the Analytics collection may be omitted.
In this case, the bucket name is used as the Analytics collection name.
The WITH clause enables you to specify parameters for the Analytics collection.
The ObjectConstructor represents an object containing key-value pairs, one for each parameter.
The following parameters are available.
Note that many of these parameters only apply when creating an external Analytics collection.
| Name | Description | Schema |
|---|---|---|
storage-block-compression |
Determines the storage compression used for this Analytics collection. This parameter takes a nested object value — |
object |
format |
(Only used when creating an external Analytics collection.) |
enum (json, csv, tsv, parquet) |
header |
(Only used when creating an external Analytics collection, and only if it has the format CSV or TSV.) |
boolean |
redact-warnings |
(Only used when creating an external Analytics collection, and only if it has the format CSV or TSV.) |
boolean |
null |
(Only used when creating an external Analytics collection, and only if it has the format CSV or TSV.) |
string |
include |
(Only used when creating an external Analytics collection. May not be used if the exclude parameter is present.) |
string, or array of strings |
exclude |
(Only used when creating an external Analytics collection. May not be used if the include parameter is present.) |
string, or array of strings |
Note that for an external collection, data in JSON, CSV, or TSV format may be stored in compressed GZIP files, with the extension .gz or .gzip.
The WHERE clause is only used when creating an Analytics collection on a local link, or a remote link.
It enables you to filter the documents in the Analytics collection.
The Expr in this clause must be deterministic,
and it may not contain a user-defined function.
The AT clause is only used when creating an Analytics collection on a remote link, or an external Analytics collection.
The QualifiedName in this clause is the name of the remote or external link on which the Analytics collection is to be created.
If this QualifiedName contains a scope name,
the statement looks for the link within the specified Analytics scope.
Otherwise, it looks for the link in the same scope as the Analytics collection.
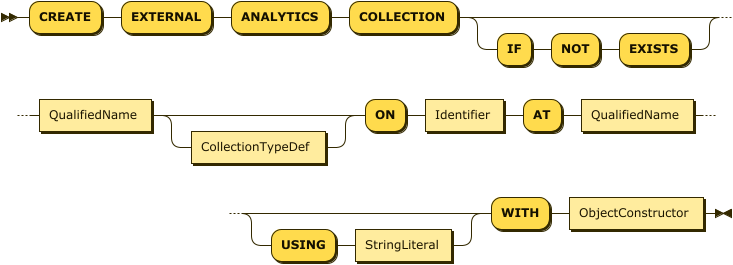
The CollectionTypeDef is only used when creating an external Analytics collection,
and only if it has the format CSV or TSV.
It consists of a comma-separated list of field definitions,
which guides the transformation of each CSV or TSV record into a JSON object.
Each field definition consists of:
-
A name to be assigned to the field.
-
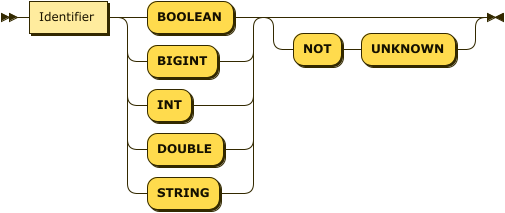
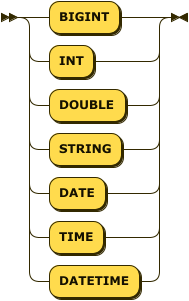
The data type of the field. This may be any of the primitive data types, where
INTis an alias forBIGINT. If this field does not contain a value of this data type, the record is ignored. -
Optionally, the
NOT UNKNOWNflag. When this flag is present, if this field ismissingornull, the record is ignored.
Every time a record is ignored because it does not match the type definition, a warning is issued.
The USING clause is only used when creating an external Analytics collection.
The expression in this clause must resolve to a string containing a path to the location of the data,
relative to the external data source.
Examples
The following example creates 2 Analytics collections in the travel Analytics scope:
an Analytics collection called hotels on the `travel-sample`.inventory.hotel keyspace,
and an Analytics collection called airports on the `travel-sample`.inventory.airport keyspace.
For the airports Analytics collection, the snappy storage compression scheme is explicitly specified.
Note that back-ticks are necessary for reserved keywords, such as type, or certain operators, such as -.
CREATE ANALYTICS COLLECTION travel.hotels
ON `travel-sample`.inventory.hotel;
CREATE ANALYTICS COLLECTION travel.airports
WITH {"storage-block-compression": {"scheme": "snappy"}}
ON `travel-sample`.inventory.airport;
The following example creates an Analytics collection in the travel Analytics scope called restaurants, and filters
the content for the Analytics collection by the value of the activity field of the record.
The Analytics collection uses data from the `travel-sample`.inventory.landmark keyspace at the remote
Couchbase cluster which is connected via the remote link called myCbLink in the Default Analytics scope.
CREATE ANALYTICS COLLECTION travel.restaurants ON `travel-sample`.inventory.landmark AT Default.myCbLink WHERE activity = "eat";
The following example creates an external Analytics collection in the travel Analytics scope called customers.
The Analytics collection uses data from the Amazon S3 bucket called TravelShop,
which is connected via the link called myS3Link in the travel Analytics scope.
The files containing the data are located in json-data/customers and use JSON Lines format.
The only files included are those with the extension .json, and with 2018 and 2019 as part of the file name.
CREATE EXTERNAL ANALYTICS COLLECTION travel.customers
ON TravelShop
AT travel.myS3Link
USING "json-data/customers"
WITH {
"format": "json",
"include": ["*2018*.json", "*2019*.json"]
};
The following example creates an external Analytics collection in the travel Analytics scope called bookings.
The Analytics collection uses data from the Amazon S3 bucket called TravelShop,
which is connected on the link called myS3Link in the travel Analytics scope.
The files containing the data are located in csv-data/accounts and have CSV format.
The only files included are those with the extension .csv, in subdirectories ranging from 2015 to 2019, and whose file name does not end with 2, 3, or 4.
Each CSV file is expected to have a header row, which is excluded.
In each row, the first column is expected to be a bigint which cannot be null,
the second column is expected to be a string which cannot be null,
the third column is expected to be a double which cannot be null,
and the fourth column is expected to be a string.
If any of the rows do not meet this data model, they will not be included.
These fields will be given the names id, datetime, amount, and details respectively.
CREATE EXTERNAL ANALYTICS COLLECTION travel.bookings(
id INT NOT UNKNOWN,
datetime STRING NOT UNKNOWN,
amount DOUBLE NOT UNKNOWN
details STRING,
) ON TravelShop
AT travel.myS3Link
USING "csv-data/accounts"
WITH {
"format": "csv",
"header": true,
"include": "201[5-9]/*[!234].csv"
};
Synonym Specification
CreateSynonym

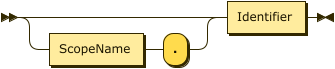
The first QualifiedName is the full name of the synonym.
It consists of an optional Analytics scope name, followed by an identifier.
If this QualifiedName contains a scope name, the synonym is created within the specified Analytics scope.
Otherwise, the synonym is created in the scope defined by the immediately preceding USE statement,
or the scope defined by the query_context parameter, or the Default Analytics scope,
according to the rules for Resolving Database Entities.
The FOR clause enables you to specify the target of the synonym.
The QualifiedName in this clause is the full name of an Analytics collection.
Again, it consists of an optional Analytics scope name, followed by an identifier.
If this QualifiedName contains a scope name,
the CREATE ANALYTICS SYNONYM statement looks for the target collection within the specified Analytics scope.
Otherwise, it looks for the target collection in the same scope as the synonym.
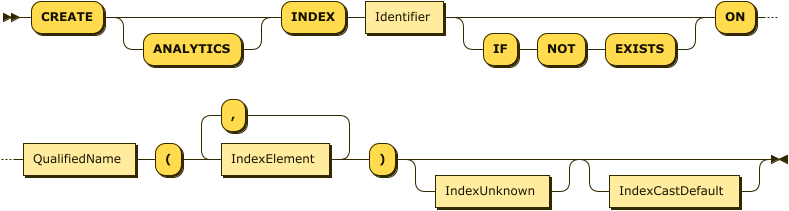
Index Specification


IndexUnknown
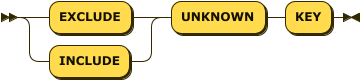
For the CREATE ANALYTICS INDEX statement, the first Identifier is the index name.
The QualifiedName identifies the Analytics collection on which the index is built.
It consists of an optional Analytics scope name and the name of the Analytics collection.
If no Analytics scope name is given,
the Analytics collection is assumed to be in the scope defined by the immediately preceding USE statement,
or the scope defined by the query_context parameter, or the Default Analytics scope,
according to the rules for Resolving Database Entities.
The index definition is contained within brackets, and consists of a list of index elements.
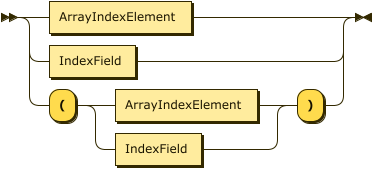
Within the index definition, each IndexElement may be either an ArrayIndexElement, or a simple IndexField.
If the index definition contains one or more array index elements, an array index is created; if it contains only simple index fields, a standard (non-array) index is created.
The IndexElement may itself be bracketed to eliminate ambiguity, in cases where the index definition contains both array index elements and simple index fields.
Within an ArrayIndexElement, the UNNEST keyword denotes a field or nested field that contains an array, and the SELECT denotes one or more fields or nested fields inside an object of the aforementioned array.
If an array contains only primitive types (strings, integers, etc.), then only UNNEST is specified.
Each indexed field in the array index element must have a type identifier.
The IndexField consists of a NestedField that specifies a field path into the indexed JSON document,
and a type identifier.
The IndexUnknown modifier enables you to specify whether to make an entry or not in a standard (non-array) index when the indexed key’s value is NULL or MISSING.
The following table outlines the behavior of INCLUDE UNKNOWN KEY and EXCLUDE UNKNOWN KEY:
| Modifier | All keys NULL or MISSING | Some keys NULL or MISSING | No NULL or MISSING |
|---|---|---|---|
INCLUDE UNKNOWN KEY |
Entry included ✓ |
Entry included ✓ |
Entry included ✓ |
EXCLUDE UNKNOWN KEY |
Entry excluded ✗ |
Entry included ✓ |
Entry included ✓ |
If you omit this modifier, then the default is INCLUDE UNKNOWN KEY.
| Array indexes cannot include NULL or MISSING values. You must specify EXCLUDE UNKNOWN KEY when defining an array index. |
Examples
The following example creates standard indexes on the identified fields for the specified types.
CREATE ANALYTICS INDEX airport_name_idx on travel.airports (airportname: string); CREATE ANALYTICS INDEX hotel_name_idx on travel.hotels (name: string); CREATE ANALYTICS INDEX hotel_loc_idx on travel.hotels (geo.lon: double, geo.lat: double);
The following example creates an array index on an array of primitive data types — in this case, an array of strings.
CREATE ANALYTICS INDEX travelHotelLikesIdx ON travel.hotels (UNNEST public_likes: string) EXCLUDE UNKNOWN KEY;
The following example creates an array index on two nested integer fields in an array of objects.
CREATE ANALYTICS INDEX travelHotelCleanServiceIdx
ON travel.hotels (UNNEST reviews
SELECT ratings.Cleanliness: bigint,
ratings.Service: bigint)
EXCLUDE UNKNOWN KEY;
The following example creates an array index on two nested integer fields in an array of objects, and one string field outside of an array.
CREATE ANALYTICS INDEX travelHotelCityCleanServiceIdx
ON travel.hotels (city: string,
UNNEST reviews
SELECT ratings.Cleanliness: bigint,
ratings.Service: bigint)
EXCLUDE UNKNOWN KEY;
Use Statements
The USE statement sets the ScopeName to be the default Analytics scope for the following statement.
If the following statement does not explicitly specify an Analytics scope,
the statement defaults to the the scope defined by the immediately preceding USE statement,
or the scope defined by the query_context parameter, or the Default Analytics scope,
according to the rules for Resolving Database Entities.
UseStmnt

The USE statement only works in a conjunction with another statement in a single request.
Example
This example sets travel to be the default Analytics scope for the statement immediately following.
USE travel;
Drop Statements
The DROP statement is the inverse of the CREATE statement. It can be used to drop Analytics scopes, collections, synonyms, and indexes.
DropStmnt
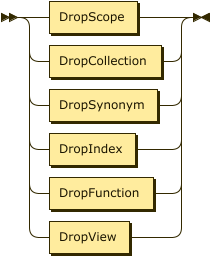
DropScope

Synonym for ANALYTICS SCOPE: DATAVERSE
DropCollection

Synonym for ANALYTICS COLLECTION: DATASET
DropSynonym

DropIndex

DoubleQualifiedName

For the DROP ANALYTICS SCOPE statement, the ScopeName is the Analytics scope name.
For the DROP ANALYTICS COLLECTION statement, the QualifiedName is the full name of the Analytics collection.
It consists of an optional Analytics scope name and the name of the Analytics collection.
For the DROP ANALYTICS SYNONYM statement, the QualifiedName is the full name of the Analytics synonym.
It consists of an optional Analytics scope name and the name of the Analytics synonym.
For the DROP ANALYTICS INDEX statement, the DoubleQualifiedName is the full name of the index.
It consists of an optional Analytics scope name, the name of the Analytics collection, and the name of the index.
When dropping a collection, synonym, or index, if no Analytics scope name is given,
the database entity is assumed to be in the scope defined by the immediately preceding USE statement,
or the scope defined by the query_context parameter, or the Default Analytics scope,
according to the rules for Resolving Database Entities.
You cannot drop an Analytics collection if is used by a user-defined function in the same or a different Analytics scope.
When you drop an Analytics scope, any user-defined functions in that scope are dropped also. However, you cannot drop an Analytics scope if there are any user-defined functions in other scopes which depend on user-defined functions or Analytics collections within the scope being dropped.
Examples
This example drops the travel Analytics scope, if it already exists.
Dropping an Analytics scope disconnects any links and drops any Analytics collections contained in it.
DROP ANALYTICS SCOPE travel IF EXISTS;
This example removes the Analytics collections and all contained data.
DROP ANALYTICS COLLECTION travel.restaurants; DROP ANALYTICS COLLECTION travel.customers; DROP ANALYTICS COLLECTION travel.bookings;
The following example drops the synonym.
DROP ANALYTICS SYNONYM travel.accommodation;
The following example drops the indexes.
DROP ANALYTICS INDEX travel.airports.airport_name_idx; DROP ANALYTICS INDEX travel.hotels.hotel_name_idx; DROP ANALYTICS INDEX travel.hotels.hotel_loc_idx;
Alter Statements
AlterStmnt

AlterCollectionEnable
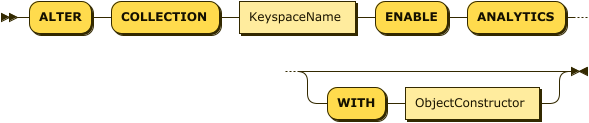
AlterCollectionDisable

The ALTER COLLECTION statements enable you to make a local Data Service keyspace available in Analytics with a single command, or remove the Data Service keyspace from Analytics with a similar single command.
The KeyspaceName specifies the local Data service keyspace that you want to make available in Analytics.
For more details, refer to Create Statements.
The WITH clause enables you to provide parameters for the Analytics collection.
The ObjectConstructor represents an object containing key-value pairs, one for each parameter.
For more details, refer to Create Statements.
When used with the ENABLE ANALYTICS keywords, the ALTER COLLECTION statement creates an Analytics scope that corresponds to the specified Data service scope, and within that Analytics scope, an Analytics collection that corresponds to the specified Data service collection. (If there is already an Analytics scope with the same name as the specified Data service scope, the Analytics collection is created within the existing Analytics scope.) The Analytics collection then uses the Data service collection as its data source. This is equivalent to running CREATE ANALYTICS SCOPE followed by CREATE ANALYTICS COLLECTION.
The name of the automatically-created Analytics scope is made up of the name of the specified Data service bucket, followed by the name of the specified Data service scope. The name of the automatically-created Analytics collection is the name of the specified Data service collection.
If you specify the default collection within the default scope within the Data service bucket,
the ALTER COLLECTION statement also creates a synonym for the collection within the Default Analytics scope.
The name of the synonym is the same as the specified Data service bucket.
This is equivalent to running CREATE ANALYTICS SYNONYM,
and enables you to refer to the collection using just the bucket name.
If an Analytics scope already exists with the same name as the specified Data service scope,
and it contains an Analytics collection with the same name as the specified Data service collection,
the ALTER COLLECTION statement fails.
Similarly, if an Analytics synonym already exists in the Default scope with the same name
as the specified Data service bucket, the ALTER COLLECTION statement fails.
|
When used with the DISABLE ANALYTICS keywords, the ALTER COLLECTION statement drops the Analytics collection, and the synonym for the Analytics collection if it exists, but does not drop the Analytics scope. This is equivalent to running DROP ANALYTICS COLLECTION, and if necessary DROP ANALYTICS SYNONYM.
Examples
The following example creates an Analytics scope called `travel-sample`.inventory.
Within that scope, it creates an Analytics collection called airline.
The Analytics collection uses the airline collection within the inventory scope in the travel-sample bucket
as its data source.
ALTER COLLECTION `travel-sample`.inventory.airline ENABLE ANALYTICS;
The following example creates an Analytics scope called `travel-sample`._default.
Within this scope, it creates an Analytics collection also called _default.
It then creates a synonym travel-sample for this Analytics collection in the Default Analytics scope.
The Analytics collection uses the default collection within the default scope in the travel-sample bucket
as its data source.
ALTER COLLECTION `travel-sample` ENABLE ANALYTICS;
The following example drops the airline Analytics collection,
but leaves the `travel-sample`.inventory Analytics scope in place.
ALTER COLLECTION `travel-sample`.inventory.airline DISABLE ANALYTICS;
The following example drops the travel-sample Analytics synonym and the _default Analytics collection,
but leaves the `travel-sample`._default Analytics scope in place.
ALTER COLLECTION `travel-sample` DISABLE ANALYTICS;
Connect Statements
The CONNECT statement connects all Analytics collections on the given Analytics links(s) to their specified data sources, and starts data ingestion. The CONNECT statement is not applicable to external links.
ConnectStmnt

LinkSpecification
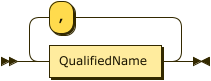
The LinkSpecification is a comma separated list of one or more links to connect.
Each item in the list is the full name of a link,
consisting of (optionally) the name of the Analytics scope where the link was created,
and the name of the link.
For the local link, the name of the link is Local; for remote links,
it is the name given to the link when it was created.
If no Analytics scope name is given,
the link is assumed to be in the scope defined by the immediately preceding USE statement,
or the scope defined by the query_context parameter, or the Default Analytics scope,
according to the rules for Resolving Database Entities.
The WITH clause enables you to provide parameters for the connection.
The ObjectConstructor represents an object containing key-value pairs, one for each parameter.
Only one parameter is currently supported for the connection:
the force parameter, which takes a Boolean value (true / false).
In Couchbase Server 7.0 and later, this parameter is ignored and has no effect.
| This parameter is deprecated and will generate a warning if used. It will be removed in a future version of Couchbase Server. |
Examples
The following example connects all Analytics collections that use the link Local in the current Analytics scope to their Data
Service keyspaces, and starts shadowing.
CONNECT LINK Local;
The following example connects all Analytics collections on the remote link called myCbLink and starts shadowing.
CONNECT LINK myCbLink;
Disconnect Statements
The DISCONNECT statement is the inverse of the CONNECT statement. It disconnects all Analytics collections on the given Analytics link(s). The DISCONNECT statement is not applicable to external links.
DisconnectStmnt

Examples
The following example stops shadowing for all Analytics collections that use the link Local in the current Analytics scope,
and disconnects their Data Service keyspaces.
DISCONNECT LINK Local;
The following example stops shadowing and disconnects all Analytics collections on the remote link called myCbLink.
DISCONNECT LINK myCbLink;
Metadata Introspection
Metadata entities can be introspected by querying the Analytics collections in the Metadata Analytics scope.
The Metadata Analytics scope contains the Analytics collections Dataverse, Dataset, Synonym, Index, Function, and Link.
Each Analytics collection contains the queryable metadata for each entity type.
Because the name of each of these collections is a reserved word in SQL++ for Analytics, note that you must delimit the collection name with backticks (`), as shown in the examples below.
The following example returns the qualified names of all Analytics collections that are not in the Metadata Analytics scope.
SELECT VALUE d.DataverseName || '.' || d.DatasetName FROM Metadata.`Dataset` d WHERE d.DataverseName <> "Metadata"
The following example returns information about all standard (non-array) indexes.
SELECT * FROM Metadata.`Index` WHERE IndexStructure = "BTREE";
The following example returns information about all array indexes.
SELECT * FROM Metadata.`Index` WHERE IndexStructure = "ARRAY";
| While Analytics scopes, Analytics collections, and indexes are created and removed by the corresponding CREATE and DROP statements, and remote links and external links are created and removed by the command-line interface or the REST API, the lifecycle of local links is managed by the system — they are created and removed as needed. |