Now in Couchbase version 7.0 the concept of scopes and collections have been introduced allowing greater flexibility in grouping data and also the ability to support multitenancy.
In older versions of Couchbase, data was organized like this (documents exist only in Buckets):
-
Cluster
-
Bucket
-
Document
In Couchbase 7.0, there are two new organizational layers, Scope and Collection, thus the hierarchy now looks like the following (documents exist only in Collections):
-
Cluster
-
Bucket
-
Scope
-
Collection
-
Document
Scopes are the level of organization below a buckets. Scopes contain collections and collections contain documents. There are different ways to use scopes, depending on what the Couchbase cluster is being used for. If it is supporting many different internal applications for a company, each application should have a scope of its own. If the cluster is being used to serve many client organizations, each running its own copy of an application, each copy should have a scope of its own. Similarly, if a cluster is being used by dev groups, perhaps for testing, the unit of allocation should be a scope. In each case, the owner can then create whatever collections they want under the scope they are assigned.
Collections are the lowest level of document organization, and directly contain documents. They are useful because they let you group documents more precisely than was possible before. Rather than dumping all different types of documents (products, orders, customers) into a single bucket and distinguishing them by a type field, you can instead create a collection for each type. And when you query, you can query against the collection, not just the whole bucket. You will also eventually be able to control access at the collection level.
Prior to Couchbase version 7.0 all services, including Eventing, were Bucket oriented where multiple sets of documents were written to a limited set of buckets (typically no more than 30 buckets). Non-homogeneous documents within the same bucket were typically differentiated by an additional type property.
{
"id": 10025,
"type": "hotel",
"brand": "Hilton",
*
*
}{
"id": 10,
"type": "airline",
"iata": "Q5",
*
*
}Every created bucket is automatically given a default scope, and within it, a default collection. Each is named _default. This allows a simple seamless migration from a Cluster/Bucket/Document model to a Cluster/Bucket/Scope/Collection/Document model without concern to any reorganization.
Thus a bucket called travelinfo prior to 7.0 essentially becomes a single collection travelinfo._default._default and the data set can remain unchanged after upgrading your cluster to 7.0.
However all types could be split up and moved into individual collections perhaps all airline documents to a keyspace of travelinfo.data.airline and all hotel documents to a keyspace of travelinfo.data.hotel.
The Eventing Service can be used to quickly and efficiently migrate a bucket into a set of collections. An example scriptlet ConvertBucketToCollections has been provided to demonstrate the migration of the beer-sample data set from a bucket paradigm to a collection paradigm.
|
The benefits of reorganizing to collections are numerous:
-
We no longer need the type property.
-
Operations such as query, XDCR, and backup and restore.
-
Increased efficiency of indexing, due to the Data Service being able to provide documents from specific collections to the Index Service.
-
Simplified querying, since query statements are able to easily specify particular subsets of documents.
-
Easier migration from relational databases to Couchbase Server, since collections can be designed to correspond to pre-existing relational tables.
-
Secure isolation of different document-types, within a bucket; allowing applications to be specifically authorized to use only their appropriate subsets of data.
For complete details on how to set up your keyspaces refer to creating buckets and creating scopes and collections.
Eventing in the collections world can just use the _default scope and the _default collection and essentially run without and changes. However there are opportunities for reorganizing the groupings of your data to lower the needed resources or increase throughput.
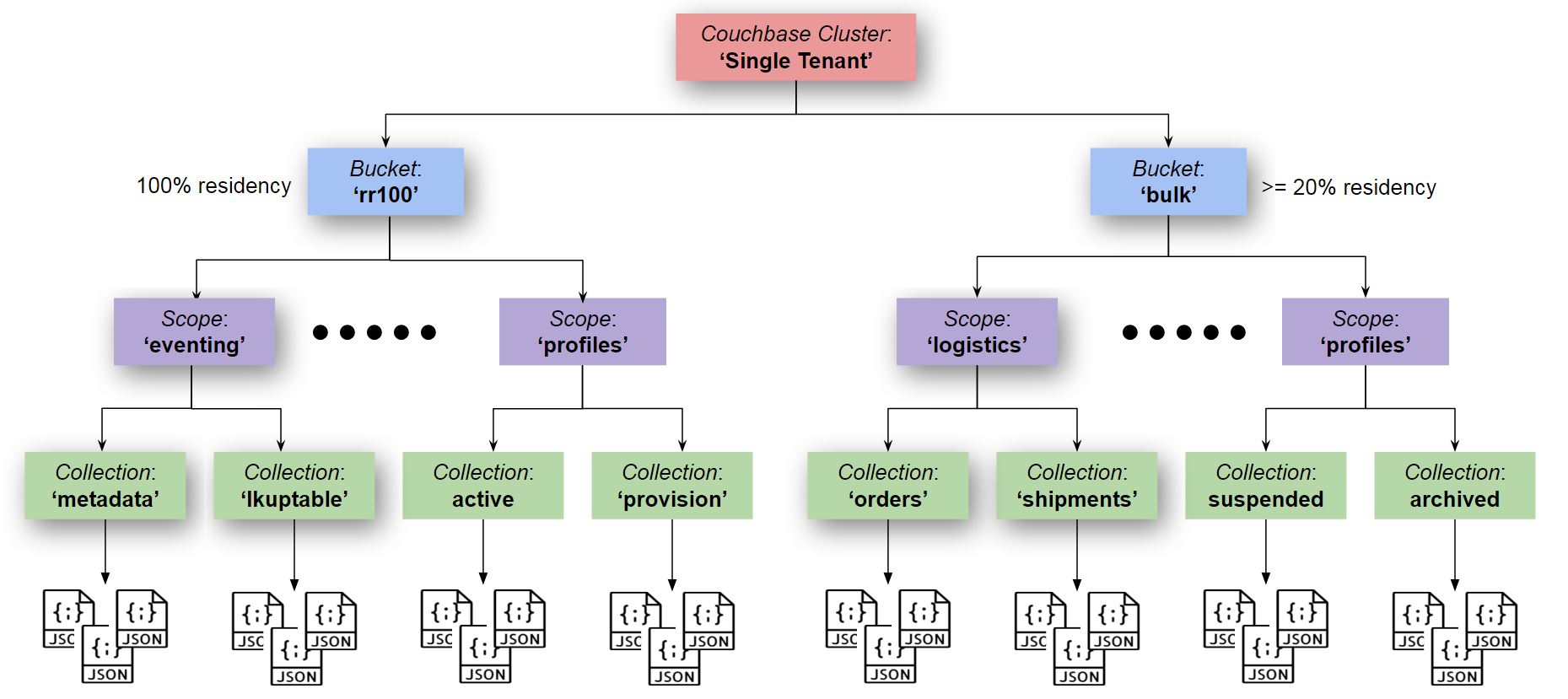
Eventing with Full Collections Support: Single Tenancy
Eventing with Full Collections Support: Multi Tenancy
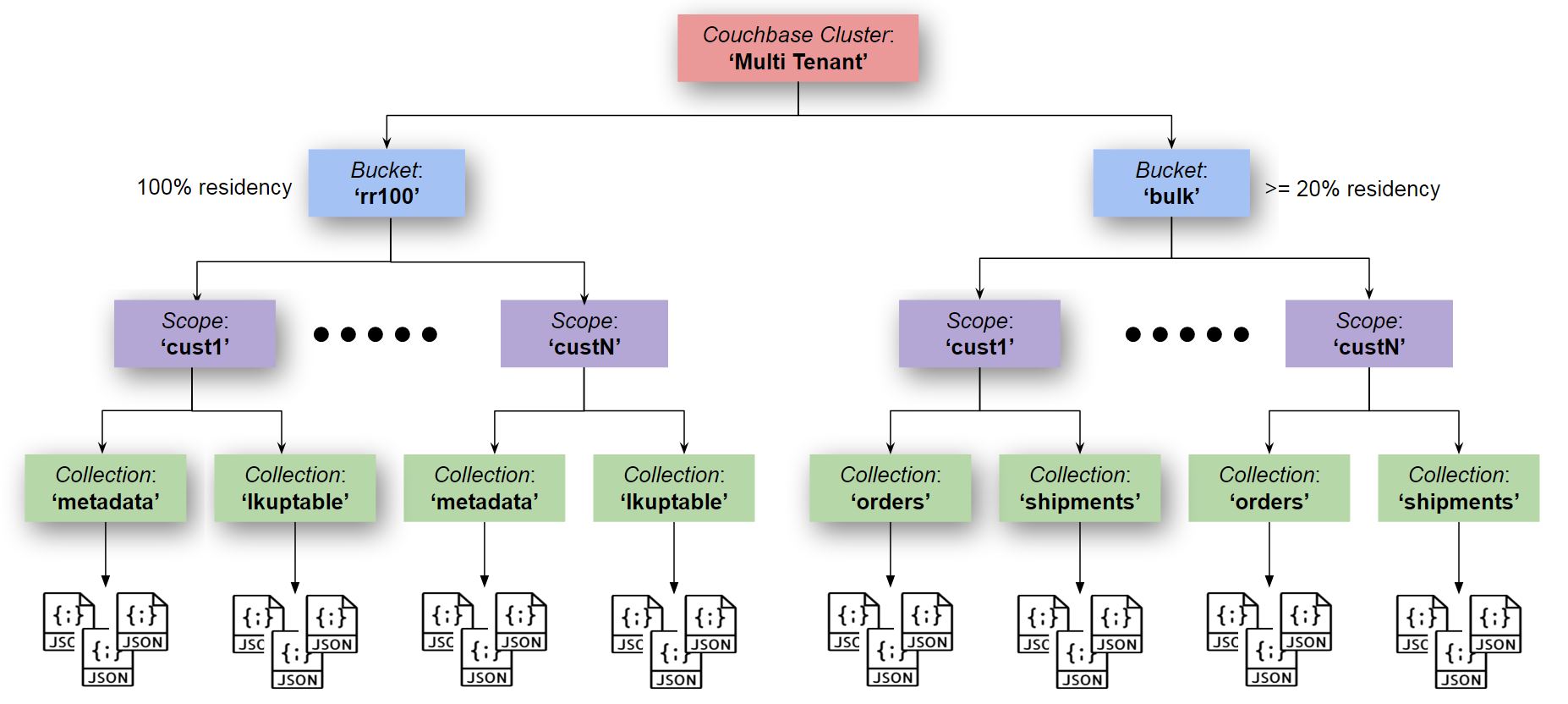
If we put the put ‘Eventing Storage’ (in collections) in the same bucket as with data with non 100% residency the Evening performance can easily drop by a factor of five (5) or more.
Of course you can put everything including the ‘Eventing Storage’ collection into a single bucket, if the bucket is 100% resident you will not suffer slowdowns but as the residency rate of this bucket drops you will start accessing your underlying disk for Eventing control documents (definitions, timers, and checkpoints). This behavior is analogous to swapping to disk when your active computer’s programs combined are larger than your computer’s memory.
Typically the overhead of the Eventing housekeeping area "Eventing Storage" is quite small, just 1024 documents per Function and occasional check point documents. However if Timers are used the size of this collection can grow to about 1K bytes x number of active timers (for 1M active timers this is 1.5G bytes). As such the enclosing bucket holding the ‘Eventing Storage’ needs to be sized appropriately.