XDCR Advanced Filtering
XDCR Advanced Filtering allows specified subsets of documents to be replicated from their source collection.
Understanding XDCR Advanced Filtering
XDCR filtering allows a document to be included in or excluded from a filtered replication, based on the document’s fields and values.
XDCR applies the filter during replication processing, as the data is passed through the replication pipeline. Filter-evaluation is performed only in the following circumstances:
-
A document is either created or modified.
-
A replication is restarted for all documents.
Note that filter-evaluation is not performed based on the measurement of elapsed time: therefore, the replication of a document cannot be triggered by establishing a filter on a date time value within the document.
For example, a filter that associates a future date time, specified as a numeric value, with a key named expiration_time does not trigger replication when the specified date time is reached.
Case-sensitive matches can be made on:
-
id and xattrs values, within the document’s metadata.
-
Field-names and values, within the document’s data, nested to any degree.
Every document on which a match is successfully made is included in the filtered replication. Other documents are not included.
Match-requirements are specified by means of:
-
Regular Expressions. These can be used to specify case-sensitive character-matches, and thereby determine whether a field-name or value may entitle a document to be included in a replication. See the reference information provided in XDCR Regular Expressions.
-
Filtering Expressions. These allow comparisons and calculations to be made on the fields and values identified by means of regular expressions: based on the results, a document either is or is not included in a replication. See the reference information provided in XDCR Filtering Expressions.
Note that fields and values on which matches are to be made should typically be kept immutable. If the fields or values of a given document are changed after a replication has started (see Filter-Expression Editing, below), such a document may no longer meet the criterion for replication, and so go unreplicated in its new form — and yet may already reside in its previous form on the target cluster; since it formerly met the criterion, and was duly replicated. In consequence, a single document would be maintained with a different value on each cluster.
This page explains XDCR Advanced Filtering at a conceptual level. For the practical steps involved, see Filter a Replication. See also the information provided in the XDCR Advanced Filtering Reference.
XDCR Advanced Filtering with Scopes and Collections
One filter can be applied per replication: this filter therefore affects all mappings between scopes and collections, whether implicit or explicit. The examples on this page show replications as extending from source bucket to target bucket: all mappings between source and target collections within these buckets should be understood to have the single filter applied to them. For more information, see XDCR with Scopes and Collections.
Note that in the special case of migration, multiple filters can be applied, each to one of multiple mappings: however, migration is intended only for the special case where data is initially established in newly created scopes and collections. See Migration, for more information.
No Filter Applied
When no filter is applied, all documents in the specified source bucket are replicated to the specified target bucket. For example:
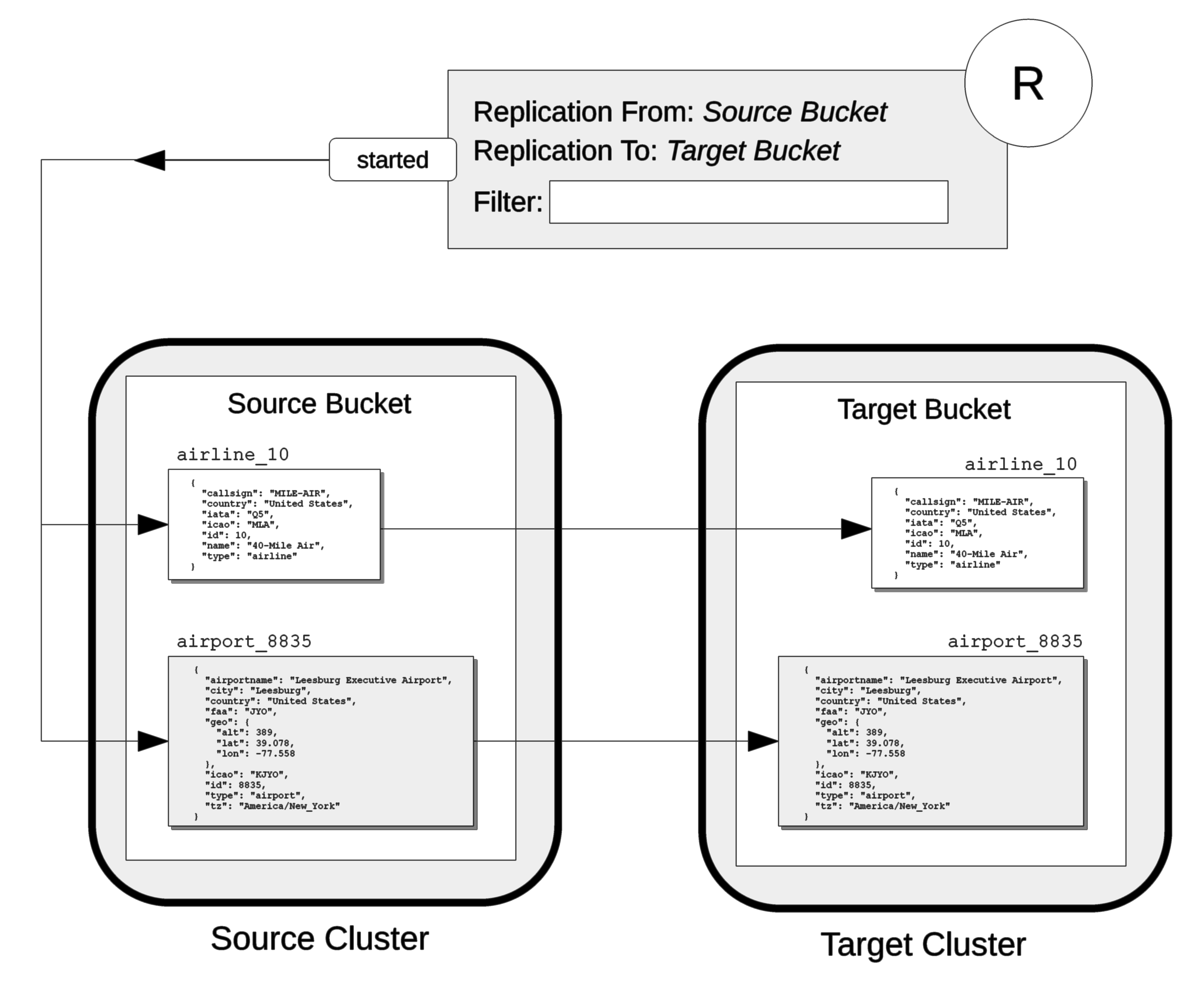
The replication R specifies as its source Source Bucket, on the Source Cluster; and specifies as its target Target Bucket, on the Target Cluster. The replication specifies no filter.
When it starts, the replication examines the documents in the source bucket, which are airline_10 and airport_8835.
Since no filter is applied, both documents are suitable for replication, and are duly replicated to the Target Bucket.
Filter Applied
When a filter is applied, on those documents whose fields or values provide a successful match are included in the replication. For example:
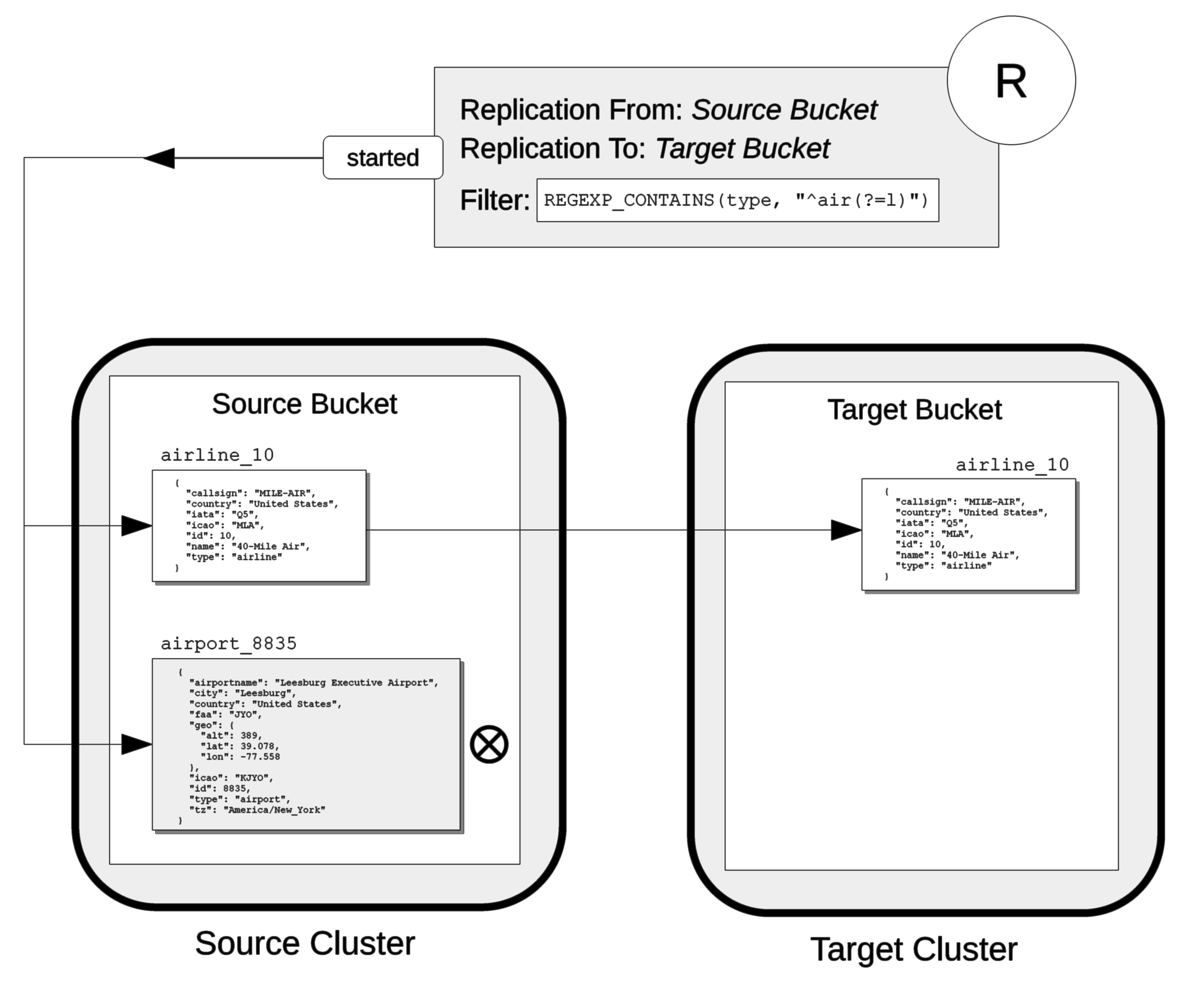
The replication R specifies as its source Source Bucket, on the Source Cluster; and specifies as its target Target Bucket, on the Target Cluster.
The replication specifies a filter: this requires that a document have a type field, whose value is a string that contains the substring air, and that this be followed by the substring l.
For details on this kind of expression (referred to as positive lookahead), see the reference provided for XDCR Filtering Expressions.
When it starts, the replication examines the documents in the source bucket.
The document airline_10 has a type field whose value provides a successful match; therefore, the document is replicated.
The document airport_8835 does have a type field, but its value does not contain a string that provides a successful match; therefore, the document is not replicated.
Multiple Filters Applied
To support replication, multiple filters can be applied in either of two ways:
-
By means of ORing, within a single replication. This allows a document to be replicated if any one of the specified filters makes a successful match. For information, see the XDCR Advanced Filtering Reference.
-
By means of individual or multiple ORed filters, specified across multiple replications. For example:
The replication R1 specifies as its source Source Bucket, on the Source Cluster; and specifies as its target Target Bucket 1, on the Target Cluster 1.
The replication specifies a filter: as in the previous example, this requires that a document have a type field, whose value is a string that contains the substring air, and that this be followed by the substring l.
When it starts, the replication examines the documents in the source bucket.
The document airline_10 has a type field whose value provides a successful match; therefore, the document is replicated to Target Bucket 1.
The document airport_8835 does have a type field, but its value does not contain a string that provides a successful match; therefore, the document is not replicated.
As R1, the replication R2 specifies as its source Source Bucket, on the Source Cluster.
However, it specifies as its target Target Bucket 2, on the Target Cluster 2.
The replication specifies a filter: this requires that a document have a type field, whose value is a string that contains the substring air, and that this be followed by the substring p.
The document airport_8835 has a type field whose value provides a successful match; therefore, the document is replicated to Target Bucket 2.
The document airline_10 does have a type field, but its value does not contain a string that provides a successful match; therefore, the document is not replicated.
Thus, each of the two documents in the source is replicated to one, distinct target bucket, on its own target cluster. Note that many variants of this example can be designed; including replicated the contents of a single source bucket to multiple target buckets on a single target cluster.
Filter-Expression Editing
The filter-expressions defined for a particular replication can be edited after their initial definition and use. This allows a single replication to employ multiple different filters and filter-combinations, sequentially.
Note that once a document has been replicated, it can only be removed from the target by being removed from the source. Therefore, if a replication’s filter-expression is changed, although it changes the criterion whereby documents are to be replicated in future, it does not affect the presence on those documents already replicated to the target according to the old criterion. If the intention is to populate the target only with documents that meet the new criterion, those documents on the target that do not meet the criterion must either be manually removed, or removed by means of flushing: see XDCR Bucket Flush, for details.
Note also that a replication only prepares to replicate all documents in the source bucket during its initial process; and afterwards, only considers mutations as candidates for replication. See XDCR Process, for details. Two options are therefore made available, whereby the continuance of a replication can be configured, following the editing of a filter-expression:
-
Restart. The current instance of the replication is ended, and a new instance is started, with the new filtering criterion. This causes a new running of the replication’s initial process, whereby all documents in the source bucket are examined. In consequence, documents that already meet the new filtering criterion, but were not replicated according to the old filtering criterion, and have not been mutated, are determined to be candidates for replication. This is the default.
-
Continue. The current instance of the replication continues, with the new filtering criterion. The replication’s initial process is not re-run. Therefore, documents that already meet the new filtering criterion, but were not replicated according to the old filtering criterion, and have not been mutated, are not replicated — unless they are mutated subsequently.
For example, it might be desirable to modify the replication shown above in Figure 2 — which searches for the string air, followed by the string l — without deleting and recreating the replication.
The possible results are shown below.
Restart
In the following illustration, the filter-expression used in Figure 2 is changed, to search for the string air, followed by the string p.
The restart option is specified.
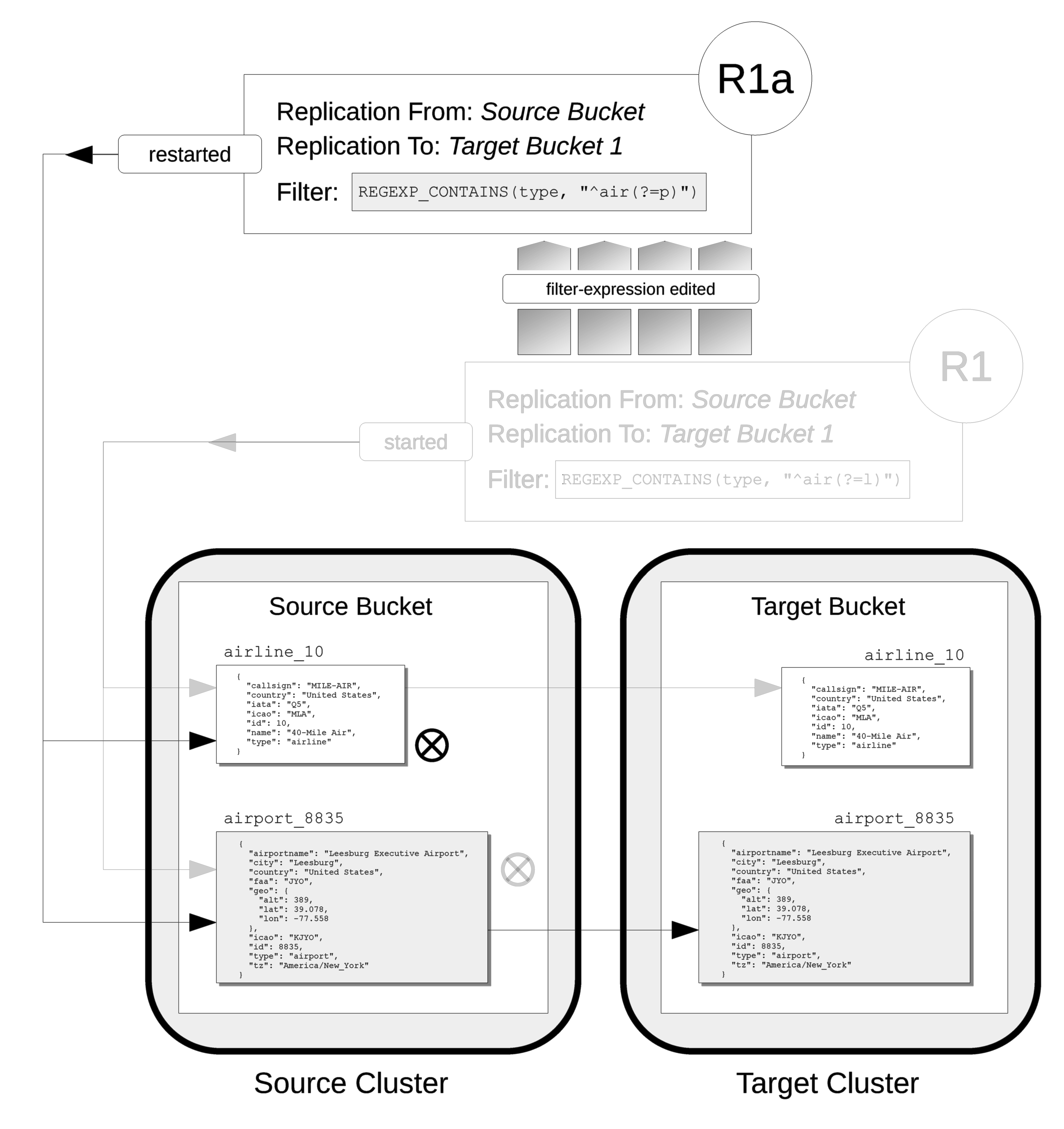
In its original version, R1, the replication had identified, during its initial process, the document airline_10, which was duly replicated to the target bucket.
The original filter-expression is edited, so that the replication becomes R1a; and the replication is restarted.
During its initial process, it examines all documents in the source bucket; finding no match on airline_10, but finding a match on airport_8835, which is duly replicated to the target bucket.
Subsequently, R1a will examine all mutations, and will replicate those on which it achieves a successful match.
Continue
In the following illustration, the filter-expression used in Figure 2 is again changed to search for the string air, followed by the string p.
This time, the continue option is specified.
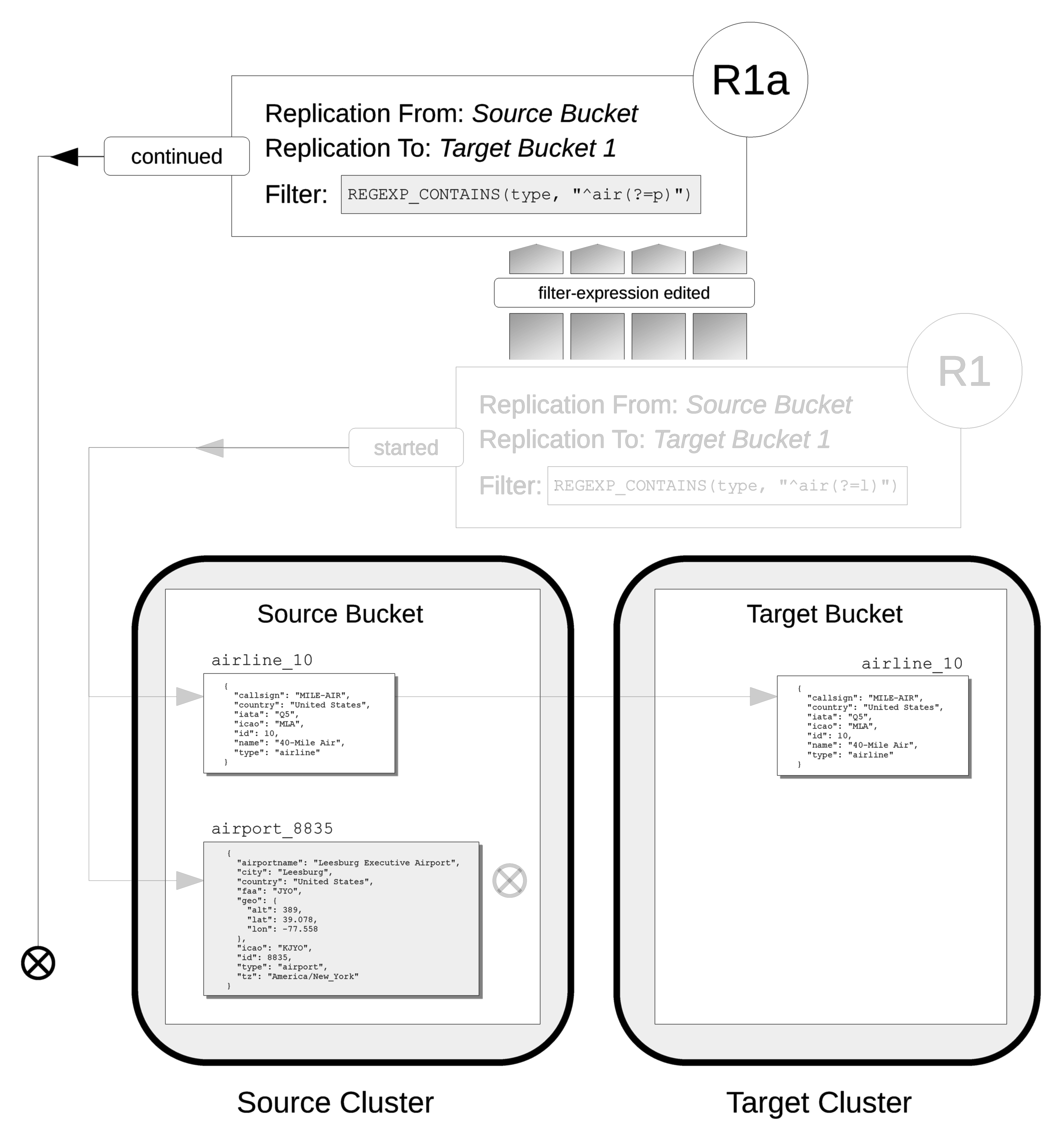
In its original version, R1, the replication had identified, during its initial process, the document airline_10, which was duly replicated to the target bucket.
The original filter-expression is edited, so that the replication becomes R1a; and the replication is continued.
There is no repetition of the initial process: therefore, the existing documents airline_10 and airport_8835 are not re-examined; and no replication occurs.
Subsequently, R1a will examine all mutations, and will replicate those on which it achieves a successful match. This is illustrated as follows:
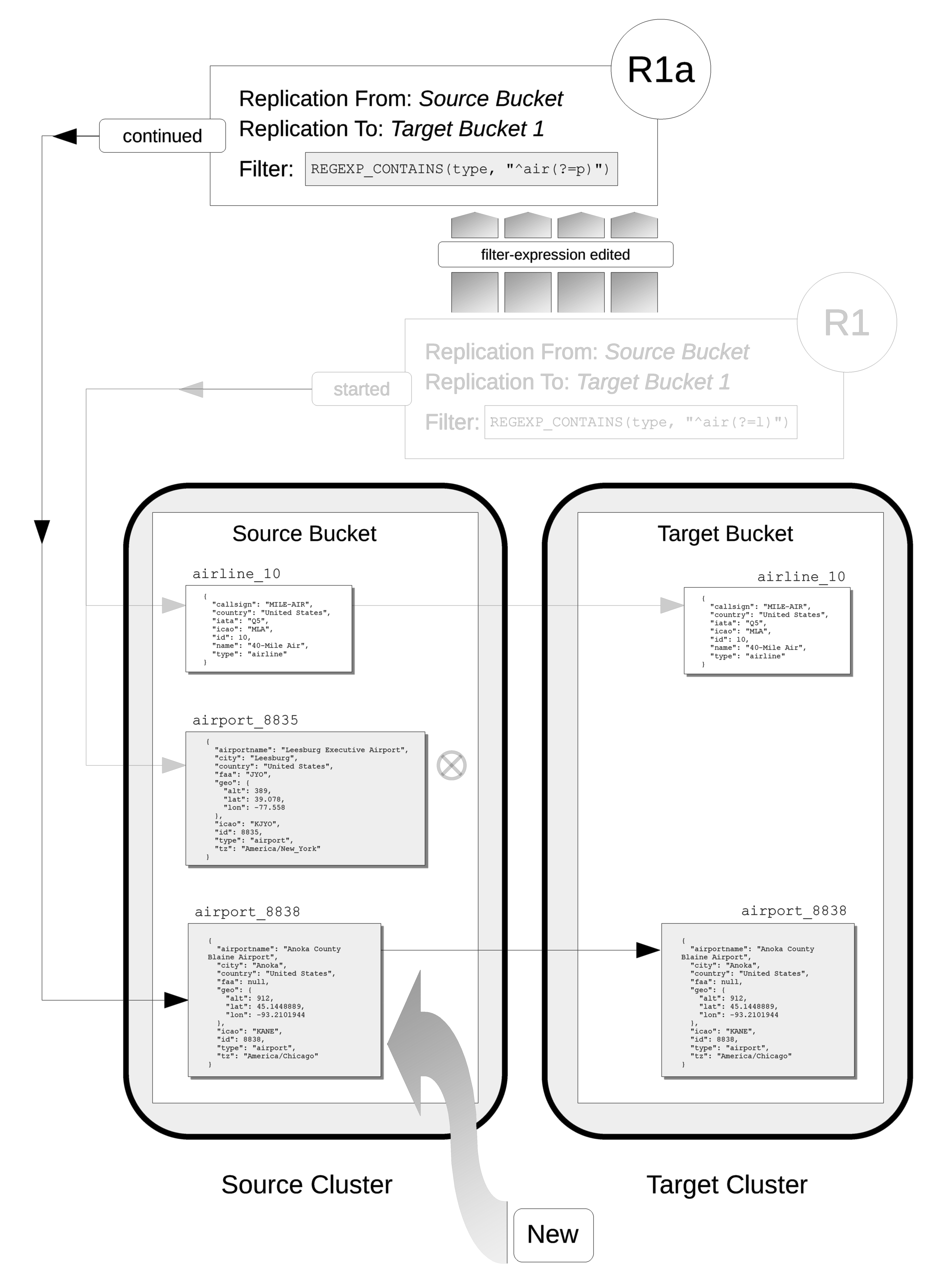
The new document airline_8838 is added the source bucket, and is examined by R1a.
A successful match is made, and airline_8838 is duly replicated to the target bucket.
Using Deletion Filters
Deletion filters control whether the deletion of a document at source causes deletion of a replica document that exists on the replication-target. For the UI each filter is selected by means of a checkbox. For the CLI and REST API, parameter-values must be specified.
Examples of filtering are provided in Filter a Replication.
Deletion-Filter Types
Deletion filters are of three types, and control the following.
Replication of Expirations
Configured through the UI with the Do not replicate document expirations checkbox; through the CLI with the filter-expiration flag; and through the REST API with the filterExpiration flag.
Selecting this option means that if, having been replicated, the document at source expires and is deleted, the replicated copy of the document will not be deleted.
Conversely, if this option is not selected or left false (which are the defaults), expirations at source are replicated; meaning that the replicated copy of the document will be deleted.
Replication of Deletions
Configured through the UI with the Do not replicate DELETE operations checkbox; through the CLI with the filter-deletion flag; and through the REST API with the filterDeletion flag.
Selecting this option determines that if, having been replicated, the document at source is deleted, the replicated copy of the document will not be deleted.
Conversely, leaving this option unselected or false (which are the defaults) replicates deletions that occur at source, meaning that the replicated copy of the document will be deleted.
Replication of TTL
Configured through the UI with the Remove TTL from replicated items checkbox; through the CLI with the reset-expiry flag; and with the REST API with the filterBypassExpiry flag.
Selecting this option determines that the TTL that a document bears at source is not made part of the replicated copy of the document: instead, the TTL of the replicated copy is set to 0.
Conversely, if this option is not selected or left false (which are the defaults), the TTL is made part of the replicated copy of the document, and may thereby determine when the replicated copy of the document expires.
Note, however, that the TTL applied to the replicated document at the target may be that of either the collection or the bucket in which it resides: for information, see Expiration.
Deletion Filters versus Filter Expressions
By default, any source-document deletion (or expiration) is replicated to the target; resulting in a corresponding target-document deletion. Note that such replication is not prevented by the specifying of a filter that is formed with regular and other filtering expressions: such expressions only determine which non-deleted documents are to be replicated. Therefore, to ensure that document-deletions (and expirations) are not replicated, deletion filters must specifically be configured.
Tombstones, DCP Events, and Replication
When a document is deleted or is expired, a tombstone is created. Tombstones and their management are described in Tombstones. In order to replicate a deletion or an expiration, XDCR must be able to receive, on the source, a DCP event that corresponds to the creation of a tombstone for the deleted or expired document. On receipt of the DCP event, XDCR generates its own, corresponding deletion or expiration event; and replicates this to the target.
However, in some instances, even if a tombstone has been created, XDCR may not receive the DCP event. For example:
-
A document is deleted and then immediately recreated, such that DCP interprets the tombstone to have been at once superseded by the recreated document; and so does not send an event.
-
A replication is deleted; then, source documents are deleted or expired. Tombstones are created; but no DCP event is sent to XDCR, since no replication exists. Subsequently, the replication is recreated: the replication will from this point only receive DCP events that correspond to future deletions and expirations.
Note, however, that conversely, creation of a new replication in this way, if performed with greater immediacy, may indeed result in DCP sending events; and allow XDCR, in turn, to replicate deletion and expiration events to the target.
Expiration, TTL, and Replication
TTL can be established on individual documents, on collections, and on buckets. The relationship between these settings, and the way the setting on an individual document is resolved when replicated to the target, is fully described in Expiration.
When a deletion or expiration event is replicated to the target, the replica-document at the target is deleted or expired irrespective of its current TTL. Thus, the replica-document’s TTL may have been modified on the target, such that it specifies expiration at a later point in time than that specified by the TTL of the source document: nevertheless, when the source document expires, an expiration event is replicated, and the replica-document on the target is immediately expired.
For more information, see Configuring Deletion Filters to Prevent Data-Loss, immediately below.
Configuring Deletion Filters to Prevent Data-Loss
Appropriate deletion-filter settings protect data. However, in certain circumstances, inappropriate deletion-filter settings may cause loss of data. For example:
-
By means of replication 1, documents of type A and type B are replicated to the target.
-
Replication 1 is deleted.
-
Documents of type A are deleted on the source; with the expectation that they will continue to exist on the target.
-
Replication 2 is created, with the default deletion-filter settings, so as to replicate to the target all future changes on the source to documents of type B.
Here, the (incorrectly) expected outcome has been that documents of both type A and type B continue to exist on the target. However, since document-deletions are replicated by default, replication 2 has deleted documents of type A from the target; and the actual outcome is therefore that only documents of type B exist on the target; with documents of type A existing on neither source nor target.
To avoid this outcome, replication 2 could be created with deletion filters configured to prevent the replication of deletions: the prior deletions of documents of type A from the source would thereby not be replicated to the target. Note, however, that this would also prevent the replication of future source-deletions of type B documents.
Configuring Deletion-Filters to Prevent Replication of Stale Data
In certain circumstances, inappropriate deletion-filter settings may allow stale data to be inadvertently replicated to the target. For example:
-
A replication is established to replicate documents of type A and type B to the target. Deletion-filter settings are configured to prevent replication of deletions that occur on the source.
-
After the replication has commenced, for reasons of security, documents of type A are deleted from the source.
Here, the (incorrectly) expected outcome has been that security requirements have been complied with, since documents of type A have been deleted from the source. However, since deletion-filters have been configured not to replicate deletions, documents of type A, subsequent to their replication, continue to exist on the target as stale data; and do so in contravention of security requirements.
To avoid this outcome, the replication should be created with the default deletion-settings, so as to permit the replication of deletions. This ensures that deletions made on the source also occur on the target.
Deletion Filters and Migration
The appropriate configuring of deletion filters is critically important in cases of migration where documents are being assigned to newly created collections, with their source collection (often the default collection of a legacy bucket) intended subsequently to be dropped. For example, the following sequence results in loss of data:
-
The default collection of a legacy bucket is determined to contain only documents that are either of type A or of type B.
-
Migration is configured to replicate documents of type A from the source, default collection to a new, target collection, named A; and documents of type B to another new, target collection, named B. Deletion filters are left at their default settings.
-
Migration proceeds. Eventually, all type A documents exist both in the source collection, and in the new, target collection A; and all type B documents exist both in the source collection, and in the new, target collection B.
-
The source, default collection is dropped; and all its data thereby deleted.
Here, the (incorrectly) expected result has been that all documents will continue to exist; in the new, target collections, A and B. However, since the migration was not deleted prior to the deletion of the source data, and since the default settings of the deletion filters specified that document-deletions should be replicated; the actual result is that all documents from the target collections A and B have been deleted, along with the source, default collection, and all its data.
Guarding Against Accidental Data-Loss during Migration
Either of the following approaches can be used to ensure that no migrated data is lost:
-
Configure deletion filters to prohibit the replication of deletions and/or expirations. This ensures that only documents and their mutations are replicated to their new collection.
Note, however, that if read-write application-access continues to be granted to the source collection during the life of the migration, application-deletions and/or expirations that occur on the source are not replicated to the target collection; eventually rendering source and target collections inconsistent.
-
Keep deletion filters at their default setting, to permit the replication of deletions and/or expirations. When the migration is judged to have completed, delete the migration prior to the deletion of any source data. Then, once the migration is deleted, delete source data as appropriate.
Note that if a new replication is subsequently created between the same source and target collections, with deletion filters configured to permit the replication of deletions and/or expirations, the deletions and/or expirations will be replicated to the target if the tombstones produced by the source-data deletions and/or expirations have not yet been purged.
Note that before and during migration, both the Backup Service and cbbackupmgr can be used to protect data.
Configuring Deletion Filters
For information on configuring deletion filters with the UI, see Deletion Filters; with the CLI, see xdcr-replicate; with the REST API, see Creating XDCR Replications.