Troubleshooting and FAQs
Full Text logs can be found in the file fts.log. This is stored with the other Couchbase Server logs; the exact location depends on your operating system.
Q: I just did a search but I don’t see the document contents, I just see the document IDs. I don’t want to have to click on document IDs.
You need to store fields in order to see result snippets and highlighting. Note that doing so makes your indexes larger and take longer to build, so make sure you need these features.
Q: Why doesn’t a search for X return document Y?
Check the following:
-
How are the search terms being analyzed?
Text is analyzed when it is written to the index, and separately, search terms are analyzed when you perform a search. These processes are independent. Unless the same analyzer is used for both indexing and search, the terms may not match.
The analyzer being used on your search terms may not the one you expected. This may happen if the search is not be scoped to the field, or is scoped to the wrong field name.
If the search clause is scoped to a field, FTS uses the same analyzer that the index mapping dictates for that field.
-
After analysis, what terms is the search looking for in the index?
Once you know what analyzer is being used on your search query, use http://analysis.blevesearch.com/ to see the exact terms that the analyzer outputs for your search. For example, if you’ve determined that the "en" analyzer is being used, a search for "marketing blunders" will result in term searches for "market" and "blunder."
-
Run a special query called a term search for one term at a time, exactly as the terms come from the analyzer in step 2. Be sure to return the document id match. Rerun for each term.
curl -XPOST -H "Content-Type: application/json" \ http://localhost:8094/api/index/perf_fts_index/query \ -d '{ "query": { "conjuncts": [ { "term": "market" }, { "ids": ["Y"] } ] } }' -
Did you get any results?
If yes, the search query is working fine. If not, check the following:
-
The document (as analyzed) does not contain the terms in question. Review the contents of the document.
-
The terms in the document don’t analyze the way the user expected. Try changing the analyzer, possibly define a custom analyzer.
-
The index mapping may be incorrect and the expected analyzer isn’t actually being used.
-
-
Advanced: Digging deeper into the index
Run command-line tools on the pindex that contains the document you expect to match.
$ cbft-bleve dump doc [path_to_pindex] [doc_id]
This dumps everything the index knows about that document.
Q: Why is this document in the search results, or why is this document ranked high in the search results?
Check the following:
-
Run the query with the option "explain" set to true. Understand which terms contributed to the document scoring the way it did. Higher numbers indicate that a term contributes more weight.
-
Experiment with boost to adjust this. For example, a query like "name:margaret^2 hobby:singing" would give twice as much weight to a match in the name field as the hobby field.
Q: Why is indexing so slow?
By default, FTS tries to index all the fields in a document yet you typically only need to search on a few key fields. Indexing all fields requires more computation and results in larger indexes than you get if you limit the index to just the fields you need.
Here are some tips to speed up indexing:
-
Build a custom mapping, set "dynamic": false to disable automatic indexing, and explicitly index only the named fields that you need to search.
-
Avoid numeric/date fields if there is no query use case/requirements around those non-text fields.
-
Avoid storing fields unless you absolutely need snippets or highlighting.
-
Consider disabling term vectors for a particular field if you know that you do not need snippets, highlights, or phrase search.
Q: Why is querying so slow?
Slow queries can be caused by searches that require a lot of processing to satisfy. This is commonly due to a search includes high frequency terms, that is, terms that appear in many or even all documents. Searches on high frequency terms require more work than searches for low frequency terms and can easily be 100x slower due to the large number of matches.
-
If possible, consider adding high frequency terms to a stop word list and reindex so they are not excluded from the index altogether. High frequency words often contribute little to the search effectiveness and they can have a seriously detrimental impact on search performance, index size and index build times.
-
Check your indexes to rule out unexpected high frequency terms. Words like "the" and "a" in English are relatively obvious candidates to add to a stopword list, but you may also have unexpected high frequency terms in your index, perhaps because there is a common token in your data you didn’t expect or a tokenizer is breaking words in an unexpected way, leading to other common terms.
-
Try rewriting queries to be more efficient if you must search on high frequency terms. Using conjunction (AND) queries can help make the search faster. In a query string, you can do this by using the + operator (MUST). For If searching for the following is slow: lowFreqTerm highFreqTerm, try +lowFreqTerm highFreqTerm.
Although it is a different search, it should perform better and may be acceptable.
Q: Why are the queries getting rejected with HTTP status code 429?
At a high level, the HTTP status code 429 indicates that ftsMemoryQuota for the cluster is under-provisioned. Whenever Search service receives a query, it tries to forecast the memory requirements for performing that search request. When processing an incoming query, the query gets rejected by FTS when the cumulative memory usage has exceeded the set memory quota limit. The memory allotted to Search service could be used by any of the following concurrent operations:
-
Parallel queries handled by the system.
-
Heavy concurrent indexing of data.
-
Parallel rebalance operations.
-
Complex queries with higher from/size parameters.
You can fix this by following the right sizing guidelines, increasing the ftsMemoryQuota, or by adding more Search nodes.
Q: Sort isn’t working like I think it should. Why do I see some weird characters in my search response object’s sort field?
When you sort results on a field that isn’t indexed, or when a particular document is missing a value for that field, you will see the following series of Unicode non-printable characters appear in the sort field: \ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd.
The same characters may render differently when using a graphic tool or command line tools like jq.
"sort": [
"����������",
"hotel_9723",
"_score"
]
Check your index definition to confirm that you’re indexing all the fields you intend to sort by.
You can control the sort behavior for missing attributes using the missing field. See Sorting Query Results.
Also remember, documents that have the same value for every field you specified in the sort field will be sorted non-deterministically.
Try adding _id, which is guaranteed unique.
Q: Are there command-line tools to help troubleshoot?
Yes - cbft-bleve command line utility. It supports several options.
These are upside_down specific commands …
-
check
-
checks the contents of the index
-
-
count
-
counts the number of documents in the index
-
-
dictionary
-
prints the term dictionary for the specified field in the index
-
-
dump
-
dumps the contents of the index
-
-
fields
-
lists the fields in this index
-
-
mapping
-
prints the mapping used for this index
-
-
query
-
queries the index
-
-
registry
-
registry lists the bleve components compiled into this executable
-
These are scorch specific commands …
-
scorch
-
command-line tool to interact with a scorch index
-
-
zap
-
command-line tool to interact with a zap file
-
Invoking the commands above with --help will highlight more information and further sub commands available for each.
Q: How does the Search service (FTS) score documents?
FTS’s internal text indexing library (bleve) uses a slightly modified version of standard tf-idf scoring. This improvisation is done to normalize the score by various relevant factors. The search scoring happens at query time.
When bleve scores a document - it sort of sums a set of sub scores to reach the final score. Scores across different searches are not directly comparable as the search query is also an input factor to the scoring function. The more conjuncts/disjuncts/sub clauses your query has, the more it will influence the scoring. The score of a particular hit is not absolute, meaning that it can only be used as a comparison to the highest score from the same search result. There isn’t a pre-defined range for valid scores.
Below is the summary of the scoring function in Search service,
Given a document which has a field f over which a given match query q is applied, then the scoreFn for that document is defined as:
scoreFn(q, f) = coord(q, f) * SUM(tw(t0, q, f), tw(t1, q, f), tw(t2, q, f)..., tw(tn, q, f)) where ti := term in q coord(q, f) = nFoundTokens(q, f)/nTokens(q) tw(ti, q, f) = queryWeight(q, f, ti) * fieldWeight(f, ti) queryWeight(q, ti) = w(ti) * queryNorm(q) w(ti) = boost(ti) * idf(ti) queryNorm(q) = 1 / SQROOT(SUM(SQ(w(t0)),...,SQ(w(tn)))) fieldWeight(f, ti) = SQROOT(FREQ(ti, f))*idf(f, ti)*fieldNorm(f) fieldNorm(f) = 1 / SQROOT(nTokens(f)) idf(f, ti) = 1 + LN(|Docs| / (1 + FREQ(ti, FIELDNAME(f), Docs))) Docs = a set of all indexed documents
where SQROOT, SUM, and LN denote standard mathematical functions. Auxiliary functions are:
-
coord(q, f) — is a dampening factor defined as a ratio of query tokens that are found in the given field, and the total number of tokens in a query.
-
tw(ti, q, f) — ti ’s term weight is the product of ti ’s query weight and ti’s field weight.
-
queryWeight(q, ti) — ti ’s query weight (wrt to q ) is the product of its inverse document frequency (see idf below) and its boosting factor.
-
queryNorm(q) — is used to normalize each query term’s contribution. It uses the Euclidean distance as the normalization factor.
-
fieldWeight(f, ti) — is a normalized product of ti ’s idf and the square root of its frequency.
-
FREQ(ti, f) — is the frequency of ti in the given field f .
-
fieldNorm(f) — normalizes each (in f ) term’s contribution to the score. The normalisation factor is the square root of the number of distinct terms in f. (Note that f ’s terms may and may not be part of q. )
-
idf(f, ti) — a dampening factor that favours terms that have high frequency in a small set of field, but not across the whole indexed (document) set.
-
FREQ(ti, FIELDNAME(f), Docs) —frequency of ti across all documents’ fields that have the same ID/Name as f .
Bleve’s tf-idf scoring variant differs with the standard textbook functions (see Intro to Information Retrieval): mainly in these points.
-
Term frequency is augmented with the square root function.
-
The idf function is “ inverse document frequency smooth ” (due to the (1+) factor). Note that it is present in both the query weight and the field weight.
-
The normalization factors are different for the field weight (a variant of the byte size normalization) and the query weight ( Euclidean ).
-
The coordination factor, which is often not present by default, can have an impact on scores for small queries.
You have an option to explore the score computations during any search in FTS by enabling the "Explain" field in the searchRequest to retrieve the score deriving details for the hits.
Q: Can I store specific document fields within FTS and retrieve those as a part of the search results?
Yes, it involves a two-step process:
-
Indexing - you need to specify the desired fields of the matching documents to be retrieved as a part of the index definition. To do so, select the "store" option checkbox in the field mapping definition for the desired fields. The FTS index will store the original field contents intact (without applying any text analysis) as a part of its internal storage.
For example, if you want to retrieve the field "description" in the document, then enable the "store" option like below.
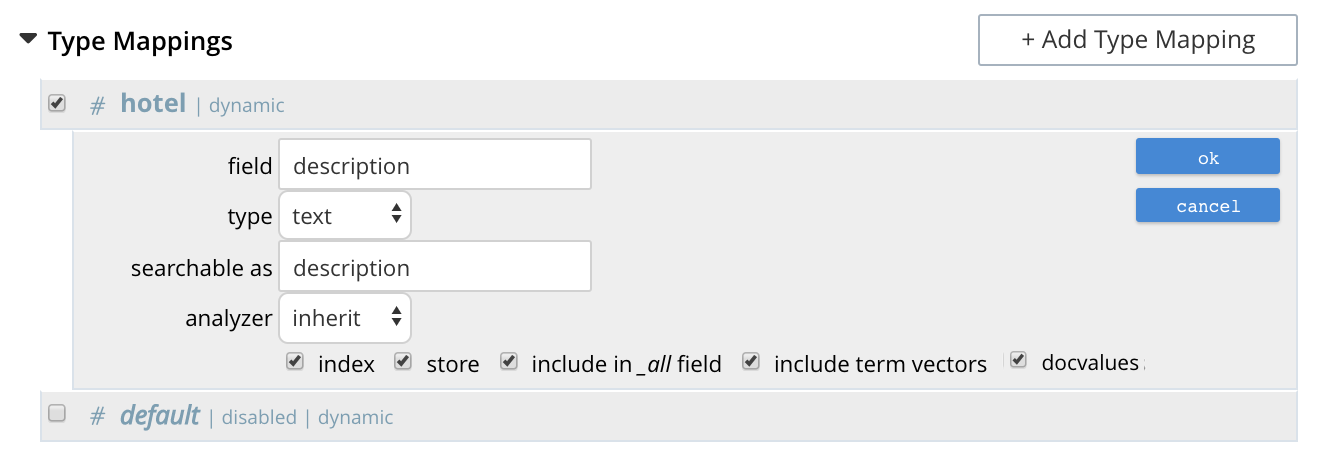
-
Searching - you need to specify the fields to be retrieved in the "fields" setting within the search request. This setting takes an array of field names which will be returned as part of the search response. The field names must be specified as strings. While there is no field name pattern matching available, you can use an asterisk ("*") to specify that all stored fields be returned with the response.
For retrieving the contents of the aforementioned "description" field, you may use the following search request.
curl -XPOST -H "Content-Type: application/json" -u username:password http://host:port/api/index/FTS/query -d '{ "fields": ["description"], "query": {"field": "queryFieldName", "match": "query text"}, }'