The Couchbase Data Model
The Couchbase Data Model provides a lightweight, flexible schema; which can be progressively evolved by applications, over time.
Couchbase Server and JSON: The Benefits
The Couchbase data model is based on JSON, which provides a simple, lightweight, human-readable notation. It supports basic data types, such as numbers and strings; and complex types, such as embedded documents and arrays. JSON provides rapid serialization and deserialization; is native to JavaScript; and constitutes the most common REST API return-type. Consequently, JSON is extremely convenient for web-application programming.
An individual document often represents a single instance of an object in application code. A document might be considered equivalent to a row in a relational table; with each of the document’s attributes being equivalent to a column. Couchbase, however, provides greater flexibility than relational databases, in that it can store JSON documents with varied schemas.
Documents can contain nested structures. This allows developers to express many-to-many relationships without requiring a reference or junction table; and is naturally expressive of hierarchical data.
Documents versus Tables
The nature and value of the document data model is clarified by comparison with the relational. To support an online flight-booking application, allowing users to search for flights by date, the relational model requires multiple tables — for flights, airlines, and schedules. The result may be as follows:
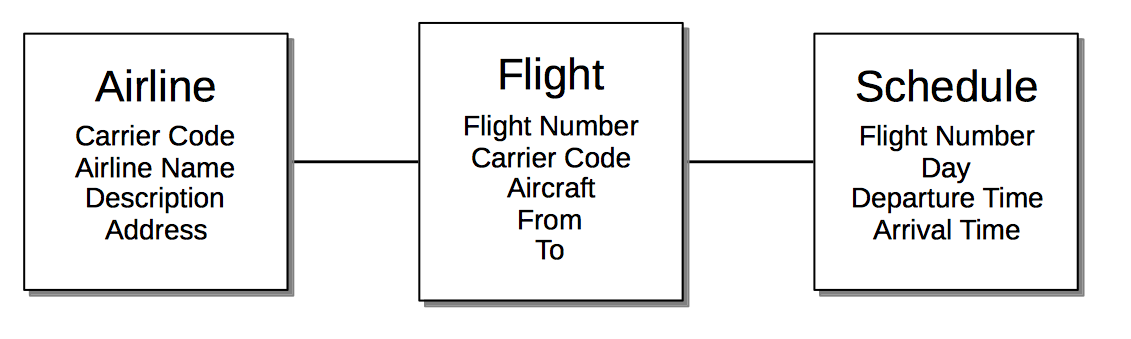
By contrast, the document model likely requires only a single document, which embeds an array of schedules for all flights between each of two airports:

Thus, in the document model, each document can be highly self-contained. This supports the rapid fulfillment of application-requests, and has important implications for both scalability and latency: one document can be replicated, or atomically changed, without other documents needing to be accessed; eradicating the need for complex inter-node coordination, and minimizing contention.
Flexible, Dynamic Schema
In the document model, a schema is the result of an application’s structuring of its documents: schemas are entirely defined and managed by applications. A document’s structure consists of its inner arrangement of attribute-value pairs.
Couchbase Server does not enforce uniformity: document-structures can vary, even across multiple documents that each contain a type attribute with a common value.
This allows differences between objects to be represented with great efficiency.
It also allows a schema to be progressively evolved by an application, as required: properties and structures can be added to the document, without other documents needing to be updated in the same way.
(This flexibility is especially advantageous when the application itself is large and long-lived.)
Document Design Considerations
When JSON documents are initially designed, performance and scalability should be considered. The best document-design can often be determined through consideration of access-patterns and object-management routines:
-
The definition of a small number of rich documents, each embedding complex information, may sometimes be appropriate: in order to group together properties typically accessed or written at the same time. This potentially allows information to be read or written in a single operation; atomicity to be improved, due to the simultaneous occurrence of mutations; and scalability to be enhanced, due to the existence of fewer relations between independent objects. It may also allow the grouped properties to be more easily maintained in a state of mutual consistency.
-
The definition of a large number of simple documents, each of which refers to others, may be appropriate when access-patterns are predictable, and data-size needs to be kept small, in order to reduce network-bandwidth consumption. Documents can refer to each other by key.