Views and Stored Data
This section describes how the views system relates to stored data.
The view system relies on the information being formatted as a JSON document. The formatting of the data in this form enables the individual fields of the data to be identified and used.
Information is stored into your Couchbase database the data stored is parsed, if the information can be identified as valid JSON then the information is tagged and identified in the database as valid JSON. If the information cannot be parsed as valid JSON then it is stored as a verbatim binary copy of the submitted data.
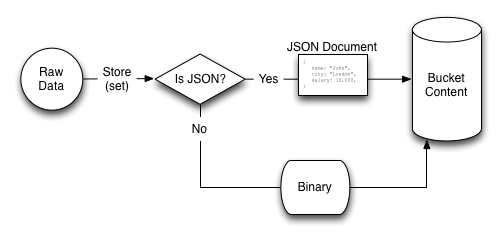
When retrieving the stored data, the format of the information depends on whether the data was tagged as valid JSON or not:
JSON information
Information identified as JSON data may not be returned in a format identical to that stored. The information will be semantically identical, in that the same fields, data and structure as submitted will be returned. Metadata information about the document is presented in a separate structure available during view processing.
The white space, field ordering may differ from the submitted version of the JSON document.
For example, the JSON document below, stored using the key mykey :
{
"title" : "Fish Stew",
"servings" : 4,
"subtitle" : "Delicious with fresh bread"
}
May be returned within the view processor as:
{
"servings": 4,
"subtitle": "Delicious with fresh bread",
"title": "Fish Stew"
}
Non-JSON information
Information not parsable as JSON will always be stored and returned as a binary copy of the information submitted to the database. If you store an image, for example, the data returned will be an identical binary copy of the stored image.
Non-JSON data is available as a base64 string during view processing.
A non-JSON document can be identified by examining the type field of the metadata structure.
The significance of the returned structure can be seen when editing the view within the Web Console.
JSON basics
JSON is used because it is a lightweight, easily parsed, cross-platform data representation format. There are a multitude of libraries and tools designed to help developers work efficiently with data represented in JSON format, on every platform and every conceivable language and application framework, including, of course, most web browsers.
JSON supports the same basic types as supported by JavaScript, these are:
-
Number (either integer or floating-point).
JavaScript supports a maximum numerical value of 253. If you are working with numbers larger than this from within your client library environment (for example, 64-bit numbers), you must store the value as a string.
-
String — this should be enclosed by double-quotes and supports Unicode characters and backslash escaping. For example:
"A String"
-
Boolean — a
trueorfalsevalue. You can use these strings directly. For example:{ "value": true} -
Array — a list of values enclosed in square brackets. For example:
["one", "two", "three"] -
Object — a set of key-value pairs (such as an associative array or hash). The key must be a string, but the value can be any of the supported JSON values. For example:
{ "servings" : 4, "subtitle" : "Easy to make in advance, and then cook when ready", "cooktime" : 60, "title" : "Chicken Coriander" }
If the submitted data cannot be parsed as a JSON, the information will be stored as a binary object, not a JSON document.
Document metadata
During view processing, metadata about individual documents is exposed through a separate JSON object, meta, that can be optionally defined as the second argument to the map().
This metadata can be used to further identify and qualify the document being processed.
The meta structure contains the following fields and associated information:
-
id
The ID or key of the stored data object. This is the same as the key used when writing the object to the Couchbase database.
-
rev
An internal revision ID used internally to track the current revision of the information. The information contained within this field is not consistent or trackable and should not be used in client applications.
-
type
The type of the data that has been stored.
A valid JSON document will have the type json.
Documents identified as binary data will have the type base64.
-
flags
The numerical value of the flags set when the data was stored. The availability and value of the flags is dependent on the client library you are using to store your data. Internally the flags are stored as a 32-bit integer.
-
expiration
The expiration value for the stored object. The stored expiration time is always stored as an absolute Unix epoch time value.
These additional fields are only exposed when processing the documents within the view server. These fields are not returned when you access the object through the Memcached/Couchbase protocol as part of the document.
Non-JSON data
All documents stored in Couchbase Server will return a JSON structure, however, only submitted information that could be parsed into a JSON document will be stored as a JSON document.
If you store a value that cannot be parsed as a JSON document, the original binary data is stored.
This can be identified during view processing by using the meta object supplied to the map() function.
Information that has been identified and stored as binary documents instead of JSON documents can still be indexed through the views system by creating an index on the key data. This can be particularly useful when the document key is significant. For example, if you store information using a prefix to the key to identify the record type, you can create document-type specific indexes.
Document storage and indexing sequence
The method of storage of information into the Couchbase Server affects how and when the indexing information is built, and when data written to the cluster is incorporated into the indexes. In addition, the indexing of data is also affected by the view system and the settings used when the view is accessed.
The basic storage and indexing sequence is:
-
A document is stored within the cluster. Initially the document is stored only in RAM.
-
The document is communicated to the indexer through replication to be indexed by views.
This sequence means that the view results are eventually consistent with what is stored in memory based on the latency in replication of the change to the indexer. It is possible to write a document to the cluster and access the index without the newly written document appearing in the generated view.
Conversely, documents that have been stored with an expiry may continue to be included within the view until the document has been removed from the database by the expiry pager.
Couchbase Server supports the Observe command, which enables the current state of a document and whether the document has been replicated to the indexer or whether it has been considered for inclusion in an index.
When accessing a view, the contents of the view are asynchronous to the stored documents.
In addition, the creation and updating of the view is subject to the stale parameter.
This controls how and when the view is updated when the view content is queried.