Reduce Function
- concept
Reduce functions are used to summarize the content generated during the map phase.
Reduce functions are optional in a view and do not have to be defined.
When they exist, each row of output (from each emit() call in the corresponding map() function) is processed by the corresponding reduce() function.
If a reduce function is specified in the view definition it is automatically used.
You can access a view without enabling the reduce function by disabling reduction ( reduce=false ) when the view is accessed.
Typical uses for a reduce function are to produce a summarized count of the input data, or to provide sum or other calculations on the input data. For example, if the input data included employee and salary data, the reduce function could be used to produce a count of the people in a specific location, or the total of all the salaries for people in those locations.
The combination of the map and the reduce function produce the corresponding view. The two functions work together, with the map producing the initial material based on the content of each JSON document, and the reduce function summarizing the information generated during the map phase. The reduction process is selectable at the point of accessing the view, you can choose whether to the reduce the content or not, and, by using an array as the key, you can specifying the grouping of the reduce information.
Each row in the output of a view consists of the view key and the view value.
When accessing a view using only the map function, the contents of the view key and value are those explicitly stated in the definition.
In this mode the view will also always contain an id field which contains the document ID of the source record (i.e.
the string used as the ID when storing the original data record).
When accessing a view employing both the map and reduce functions the key and value are derived from the output of the reduce function based on the input key and group level specified. A document ID is not automatically included because the document ID cannot be determined from reduced data where multiple records may have been merged into one.
The following diagram shows an example of the view creation process:
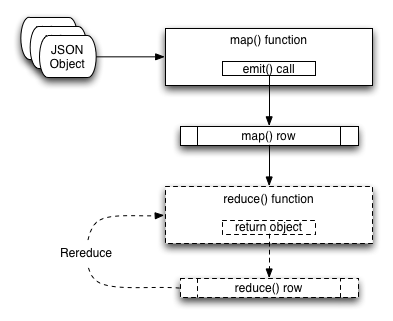
Because of the separation of the two elements, the two functions can be considered individually.
For information on how to write map functions, and how the output of the map function affects and supports searching.
View names must be specified using one or more UTF-8 characters. You cannot have a blank view name. View names cannot have leading or trailing whitespace characters (space, tab, newline, or carriage-return).
To create views, you can use either the Web Console View editor, use the REST API for design documents, or use one of the client libraries that support view management.
Often the information that you are searching or reporting on needs to be summarized or reduced. There are a number of different occasions when this can be useful. For example, if you want to obtain a count of all the items of a particular type, such as comments, recipes matching an ingredient, or blog entries against a keyword.
When using a reduce function in your view, the value that you specify in the call to emit() is replaced with the value generated by the reduce function.
This is because the value specified by emit() is used as one of the input parameters to the reduce function.
The reduce function is designed to reduce a group of values emitted by the corresponding map() function.
Alternatively, reduce can be used for performing sums, for example adding up all the invoice values for a single client or adding up the preparation and cooking times in a recipe. Any calculation that can be performed on a group of the emitted data.
In each of the above cases, the raw data is the information from one or more rows of information produced by a call to emit().
The input data, each record generated by the emit() call, is reduced and grouped together to produce a new record in the output.
The grouping is performed based on the value of the emitted key, with the rows of information generated during the map phase being reduced and collated according to the uniqueness of the emitted key.
When using a reduce function the reduction is applied as follows:
-
For each record of input, the corresponding reduce function is applied on the row, and the return value from the reduce function is the resulting row.
For example, using the built-in _sum reduce function, the value in each case would be totaled based on the emitted key:
{
"rows" : [
{"value" : 13000, "id" : "James", "key" : "James" },
{"value" : 20000, "id" : "James", "key" : "James" },
{"value" : 5000, "id" : "Adam", "key" : "Adam" },
{"value" : 8000, "id" : "Adam", "key" : "Adam" },
{"value" : 10000, "id" : "John", "key" : "John" },
{"value" : 34000, "id" : "John", "key" : "John" }
]
}
Using the unique key of the name, the data generated by the map above would be reduced, using the key as the collator, to the produce the following output:
{
"rows" : [
{"value" : 33000, "key" : "James" },
{"value" : 13000, "key" : "Adam" },
{"value" : 44000, "key" : "John" },
]
}
In each case the values for the common keys (John, Adam, James), have been totalled, and the six input rows reduced to the 3 rows shown here.
-
Results are grouped on the key from the call to
emit()if grouping is selected during query time. As shown in the previous example, the reduction operates by the taking the key as the group value as using this as the basis of the reduction. -
If you use an array as the key, and have selected the output to be grouped during querying you can specify the level of the reduction function, which is analogous to the element of the array on which the data should be grouped.
The view definition is flexible. You can select whether the reduce function is applied when the view is accessed. This means that you can access both the reduced and unreduced (map-only) content of the same view. You do not need to create different views to access the two different types of data.
Whenever the reduce function is called, the generated view content contains the same key and value fields for each row, but the key is the selected group (or an array of the group elements according to the group level), and the value is the computed reduction value.
Couchbase includes the following built-in reduce functions:
-
_count -
_sum -
_stats.
| You can also write your own custom reduction functions. |
The reduce function also has a final additional benefit. The results of the computed reduction are stored in the index along with the rest of the view information. This means that when accessing a view with the reduce function enabled, the information comes directly from the index content. This results in a very low impact on the Couchbase Server to the query (the value is not computed at runtime), and results in very fast query times, even when accessing information based on a range-based query.
The reduce() function is designed to reduce and summarize the data emitted during the map() phase of the process.
It should only be used to summarize the data, and not to transform the output information or concatenate the information into a single structure.
When using a composite structure, the size limit on the composite structure within the reduce() function is 64KB.